
RLHF: Reinforcement Learning from Human Feedback

•
(위 블로그 포스팅 내용을 정리함)
•
LM의 강화 학습(Reinforcement Learning) 필요성
◦
LM이 주어진 Prompt로부터 “좋은” Text를 생성했는지 평가할 수 있는 마땅한 지표(Metric)가 존재하지 않음
◦
여전히 LM의 Pre-Training에는 단순 Next Token Prediction Loss (Cross-Entropy)가 사용되며,
◦
이를 보완하기 위해 (Text Generation Tasks에서는) BLEU, ROUGE 등의 지표를 활용하지만, 여전히 사람이 작성한 References가 필요하다는 값비싼 단점이 존재함
◦
만약, LM이 생성한 Text에 대한 사람의 피드백을 성능 평가 지표 or Loss로 활용하면 어떨까?라는 생각에서 강화 학습이 제안됨
•
학습 방법(Methods)
◦
Step 1. PLM 준비
▪
학습에 사용할 PLM을 준비함
▪
InstructGPT는 레이블러들이 직접 작성한 Text로 LM을 추가 학습시켰지만, 일반적인 PLM을 사용하여도 무방함
◦
Step 2. Reward Model(RM) 학습
▪
LM이 생성한 Text를 입력받아 Scalar 점수 (사람의 선호도)를 출력하는 모델 (RM) 학습
▪
사전에 준비한 Prompt를 Step 1에서 준비한 PLM에 입력하여 n개의 Text를 생성하고, 이를 레이블러들이 점수를 매겨 RM 학습을 위한 Dataset을 구축함
▪
엄밀히 말하면, n개의 Text 각각에 점수를 매기는 것이 아닌 n개의 Text를 대상으로 상대적인 Ranking을 부여함 (Elo Rating을 사용하기도 함)
▪
(최근에 Google로부터 투자 유치를 받은 Anthropic에서 공개한 Dataset)

▪
RM의 크기는 제각각이지만, 직관적으로 PLM이 생성한 Text를 이해할 수 있는 정도의 Capacity를 가져야 함
◦
Step 3. 강화 학습 수행
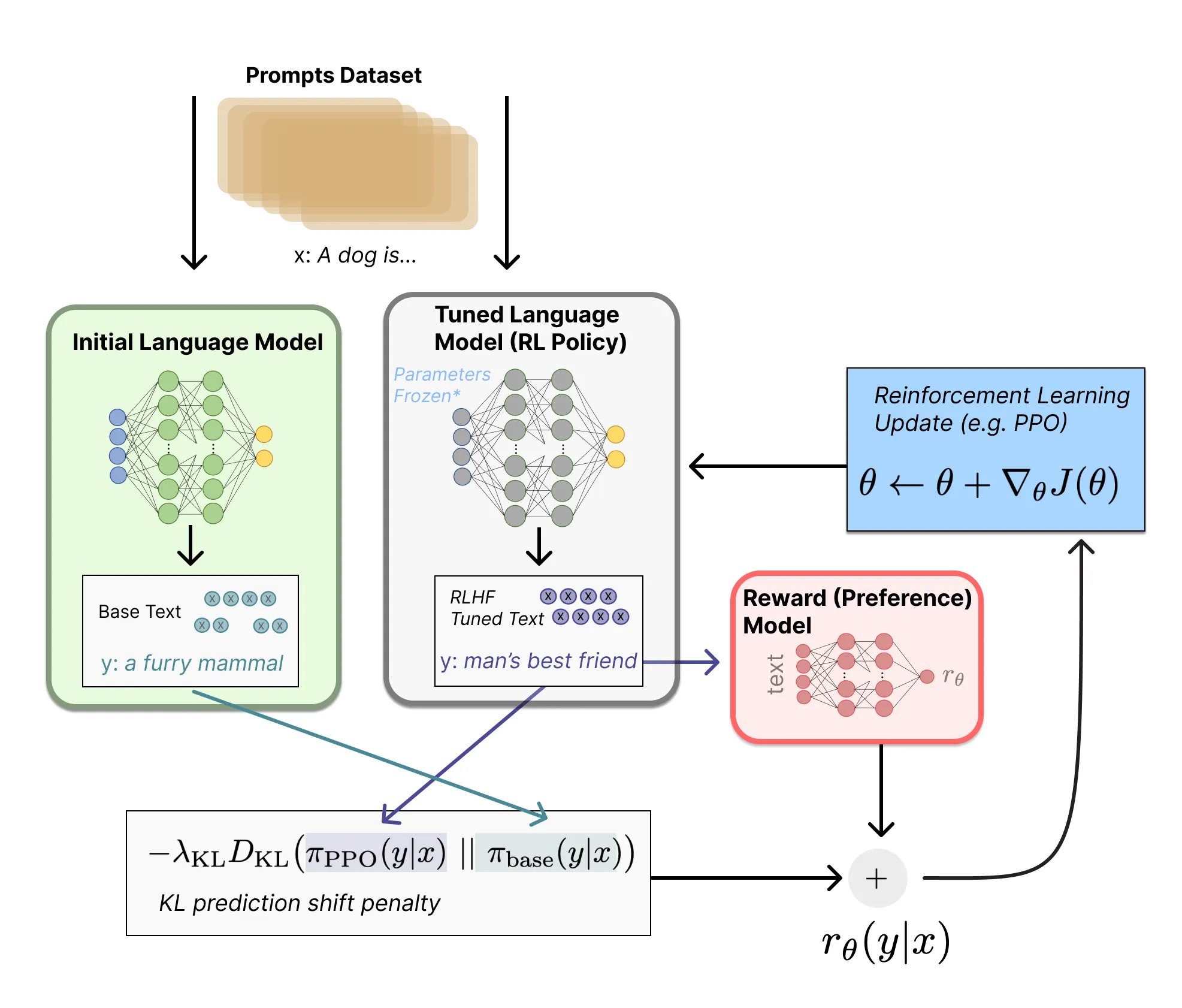
▪
PLM을 복사하고, (대부분의 Params를 고정하여) 일부 Params만을 Proximal Policy Optimization (PPO) 알고리즘으로 학습시킴


▪
Prompt를 입력받아 Text를 생성하는 (PLM의 복사본) LM이 Policy가 되며,
▪
LM의 Tokenizer Vocab에 존재하는 Token들이 Action Space,
▪
Step 2에서 학습한 RM이 Reward Function이 됨
▪
Reward Function에는 RM의 출력값(사람의 선호도 점수) 이외에 원본 PLM과 LM의 출력 간의 KLD Term이 추가 활용됨
▪
이는 LM이 생성하는 Text의 분포가 원본과 너무 달라지지 않게 조절하는 (일반적으로 자주 사용되는) 장치임
▪
PPO는 처음 공개된 이후 많은 시간이 지났지만, 여전히 좋은 성능과 친숙함으로 현재에도 널리 사용되고 있는 듯함 (강화 학습 잘 모름..)
)ChatGPT
•
ChatGPT는 InstructGPT의 Supervised Fine-Tuning(SFT) 과정에서 레이블러가 작성한 Human-AI Assistant 간의 대화 데이터를 추가 활용함
◦
레이블러는 자연스러운 대화 데이터 구축을 위해 AI 모델 (LM)이 작성한 대답 (Text)을 수정할 수 있는 권한을 가짐
•
위의 과정을 통해 ChatGPT는 대화를 이어가며 사람이 원하는 Text를 생성할 수 있게 됨