
최근 몇 주 동안 연일 화제인 ChatGPT를 공부합니다!
(바쁜 일정으로 이제서야 리뷰합니다..)
)InstructGPT


•
InstructGPT는 ChatGPT의 기반이 되는 모델로, 작년(2022년) 초에 OpenAI가 공개함
◦
ChatGPT가 좋은 성능으로 각광을 받고 있지만, 학습 방법론은 기존의 InstructGPT와 크게 다르지 않음
◦
작년 여름 이후, Stable Diffusion 등 Generative AI가 주목을 받기 시작하면서 덩달아 유명해진 것이 아닐까..? 생각중
•
InstructGPT가 해결하고자 하는 기존의 문제점은 다음과 같음
◦
175B GPT-3 등 초거대 LM은 현실적으로 학습이 불가능할뿐더러 Generalization 능력이 이미 출중하기 때문에, 원하는 결과를 얻기 위해 Prompting 기법을 활용함
// Input Text (Prompt) 예시
주어진 "상황"에 알맞는 "대화"를 생성하시오
상황: 친구가 시험에 합격함
대화: 너 시험 합격했다며! 너무 잘 됐다~ 축하해!
상황: 친구가 다침
대화: 많이 다쳤어? 괜찮니? 빨리 나으면 좋겠다ㅠ
상황: 친구가 새로운 옷을 구매함
대화:
// Model Output (Generation) 예시
옷 샀구나? 너무 잘 어울린다! 어디서 샀어?
Markdown
복사
◦
그러나 일반적인 Causal LM은 단순히 (주로 인터넷에서 크롤링한) 문장의 다음 단어를 예측하도록 학습되기 때문에, Prompting으로는 초거대 LM을 완벽히 통제할 수 없음
▪
단순히 의도한 결과를 출력하지 않을 수도 있고 (Simply Not Helpful),
▪
거짓 정보를 진실인 양 생성하거나 (Hallucination),
▪
공격적이고 편향된 글을 생성하는 문제가 있음 (Toxic & Biased)
•
InstructGPT는 주어진 Prompt로부터 의도한 결과를 생성 (Accordance with User’s Intention)하는 법과 이에 대한 사람의 피드백 (Feedback)을 학습하는 방식으로 위의 문제점들을 극복함
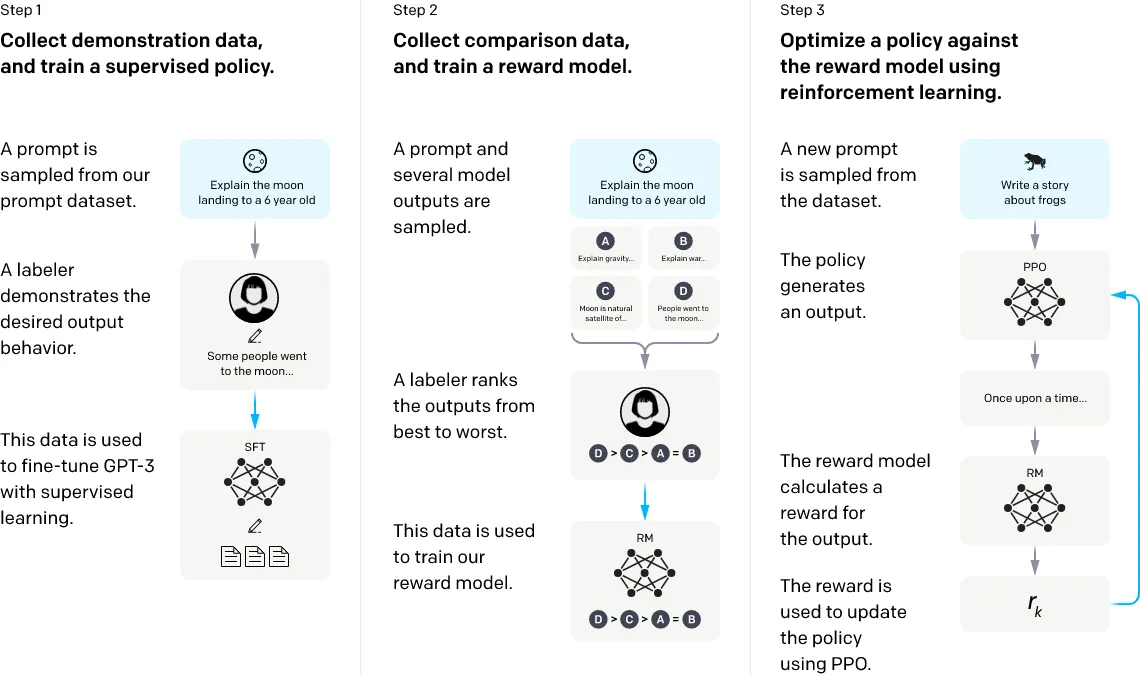
◦
Step 1: OpenAI API와 레이블러의 직접 작성을 통해 Prompt를 수집하여, 레이블러가 Prompt의 의도에 맞는 결과 Texts (Demonstrations)를 작성하고, 이를 활용하여 GPT-3를 Supervised Fine-Tuning (SFT)함
◦
Step 2: n개의 Prompt를 추출하고, 학습한 모델을 활용하여 Prompt별로 복수의 결과를 생성함. 이에 레이블러가 점수를 매긴 Dataset (Comparisons)을 통해 Reward Model (RM)을 학습함
◦
Step 3: RM을 활용하여 Reinforcement Learning을 수행하고, LM의 성능을 높임
•
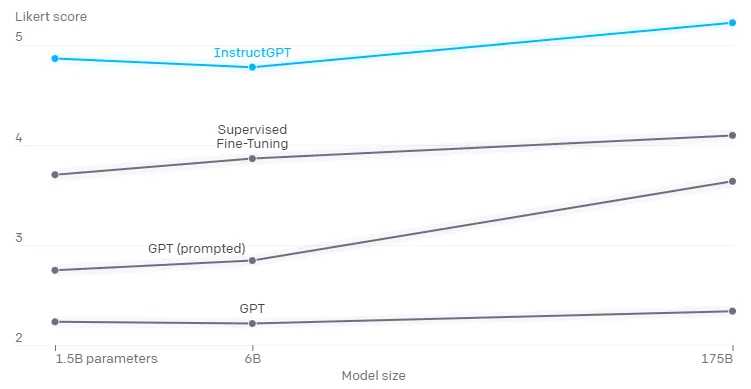
실험 결과, InstructGPT가 GPT-3에 비해 좋은 퀄리티의 (Prompt의 의도에 맞는) 결과를 생성하며, 덩달아 생성 결과물의 Hallucination과 Toxicity, Bias가 완화됨을 확인할 수 있음
•
InstructGPT에서 활용하는 Reinforcement Learning 기법은 RLHF (Reinforcement Learning from Human Feedback)로, PPO (Proximal Policy Optimization) 알고리즘을 사용함 (추후 공부)


