
GPT-3.5, ChatGPT 등 Language 분야에서 좋은 Generalization (Zero/Few-Shot) 성능을 보인 Instruction Tuning 기법..
GPT-4를 필두로 Vision-Language 분야에서도 적극 활용되기 시작!
그중 대표적인 VL Instruction-Following 모델들.. LLaVA, MiniGPT-4, InstructBLIP, Otter에 관한 내용 (Base Model, Dataset 등)을 간단히 정리..
Introduction
•
Visual ChatGPT, HuggingGPT 등.. 외부 Vision 모델들과 ChatGPT Prompting을 활용하여 LLM의 Generalization 능력을 Text에서 Image까지 확장시키려는 연구들이 존재
•
But, 본 글에서는 외부 모델을 활용하지 않는 End-to-End VL Instruction-Following 모델들을 리뷰함
•
그중에서도 Compute-Efficient한 방식으로 학습된 모델들을 선정
◦
Pre-Trained Unimodal (Vision+Language) 모델 기반 → 별도의 Projection Layer 혹은 작은 모델을 두어 해당 부분만 학습
◦
일반적으로 Vision-Language 모델 간의 Alignment를 위해 CC3M, CC12M, SBU, LAION-400M 등 Captions Dataset을 활용한 Pre-Training 수행
◦
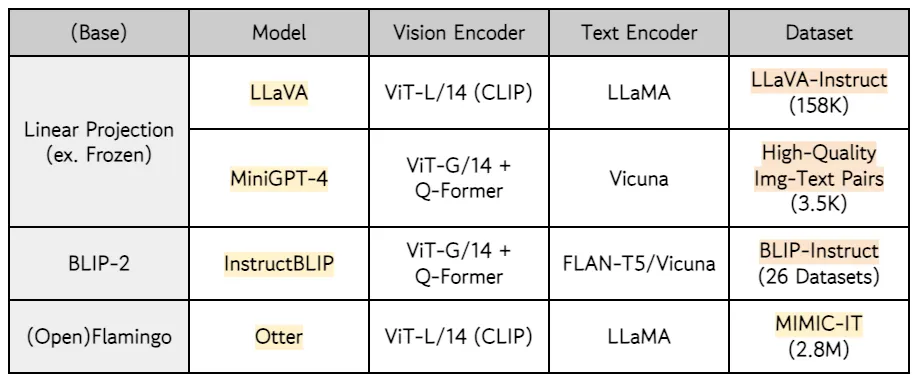
•
LLaVA, MiniGPT-4, InstructBLIP의 Dataset명은 가칭
•
LLaVA는 2nd-Stage Training에서 LLaMA의 Params를 Update → 다른 모델들에 비해 Compute-Inefficient한 특징이 있음