
[BLIP-2 논문 리뷰]
GPT-4 공개 이후, 다수의 Vision-Language(VL) Instruction-Following 모델들이 등장하고 있음
LLaVA, MiniGPT-4와 함께 Salesforce에서 공개한 InstructBLIP 모델이 흥미로웠으며, 기반이 되는 모델인 BLIP-2를 리뷰하게 되었음..!
Introduction
•
최근, 성능이 좋은 단일 Vision/Language Pre-Trained 모델들이 다수 공개되어 있고 → 본 논문에서는 이를 활용한 Compute-Efficient VL Pre-Training 기법을 제안
•
본 논문에서 제안하는 Compute-Efficient VL 모델: BLIP-2
(Figure. BLIP-2)
◦
기존 모델들과 마찬가지로.. Pre-Trained LM + Vision Model을 Freeze하고,
◦
Q-Former라는 Vision-Language Alignment 모델을 학습 → LM이 이해할 수 있는 유의미한 Visual Features를 추출 (핵심)
◦
Q-Former는 Learnable Query Vector Set과 가벼운 Transformer 모델로 구성
Proposed Model: BLIP-2
(1st-Stage Pre-Training: VL Representation Learning)
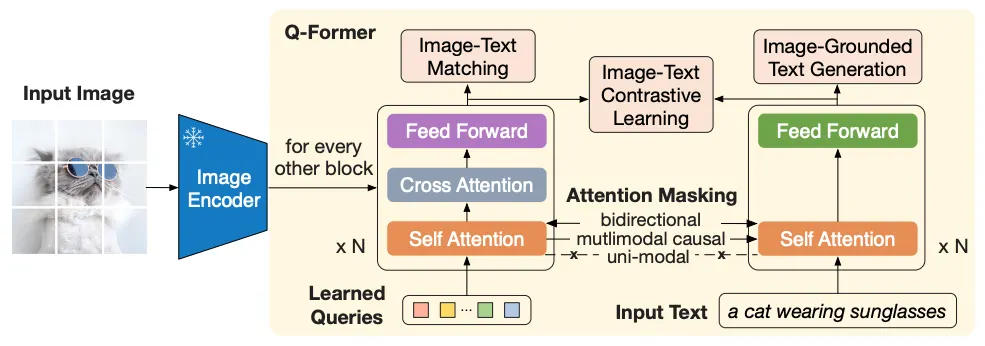
•
BLIP-2의 핵심 모듈, Q-Former는 다음과 같은 두 하위 모듈로 구성
◦
Image Transformer (위 그림 Q-Former 왼쪽)
▪
Learnable Query Vector Set을 입력으로 받아 Self-Attention Layer에 Feed하고,
▪
Cross-Attention Layer를 통해 Image Features를 Attend
◦
Text Transformer (위 그림 Q-Former 오른쪽)
▪
Text 입력을 받아 Self-Attention Layer에 Feed
▪
Text Encoder or Decoder로 모두 활용 가능
•
두 Transformer는 Self-Attention Layer를 공유하기 때문에 → Query Vector와 Input Text 간의 정보 공유가 가능
◦
Self-Attention Layer의 Params는 Pre-Trained BERT-base(110M)로 초기화
◦
Cross-Attention Layer의 Params는 Random 초기화
(Self-Attention Masking in 1st-Stage)
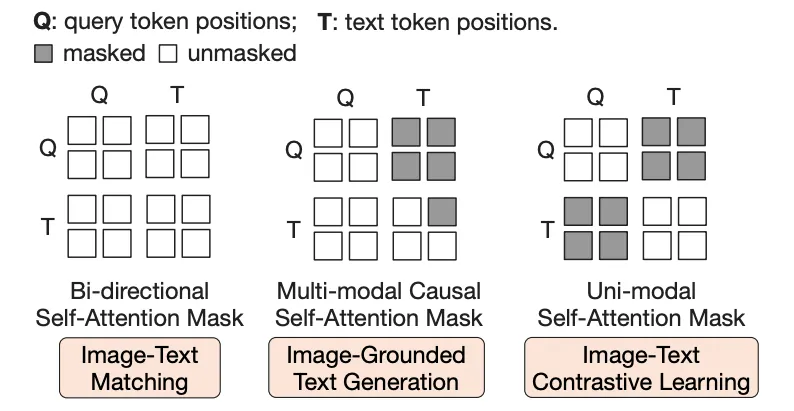
•
Pre-Training (Q-Former의 학습)은 두 단계로 구성
•
1st-Stage: VL Representation Learning
◦
Image-Text 쌍을 활용하여 LM이 이해할 수 있는, 유의미한 Visual Features를 추출하도록 학습
◦
▪
ITC (Image-Text Contrastive Learning): 동일한 쌍의 Image와 Text Representations가 유사한 값을 갖도록 학습
▪
ITG (Image-grounded Text Generation): 주어진 Image를 기반으로 동일 쌍의 (짝지어진) Text를 생성하도록 학습
▪
ITM (Image-Text Matching): 주어진 Image와 Text가 동일한 쌍 (Positive)인지 다른 쌍(Negative)인지 분류하도록 학습
◦
각 Training Objective에 따라 다른 Attention Mask 적용 (위 그림 참조)
(2nd-Stage Pre-Training: V-to-L Generative Learning)
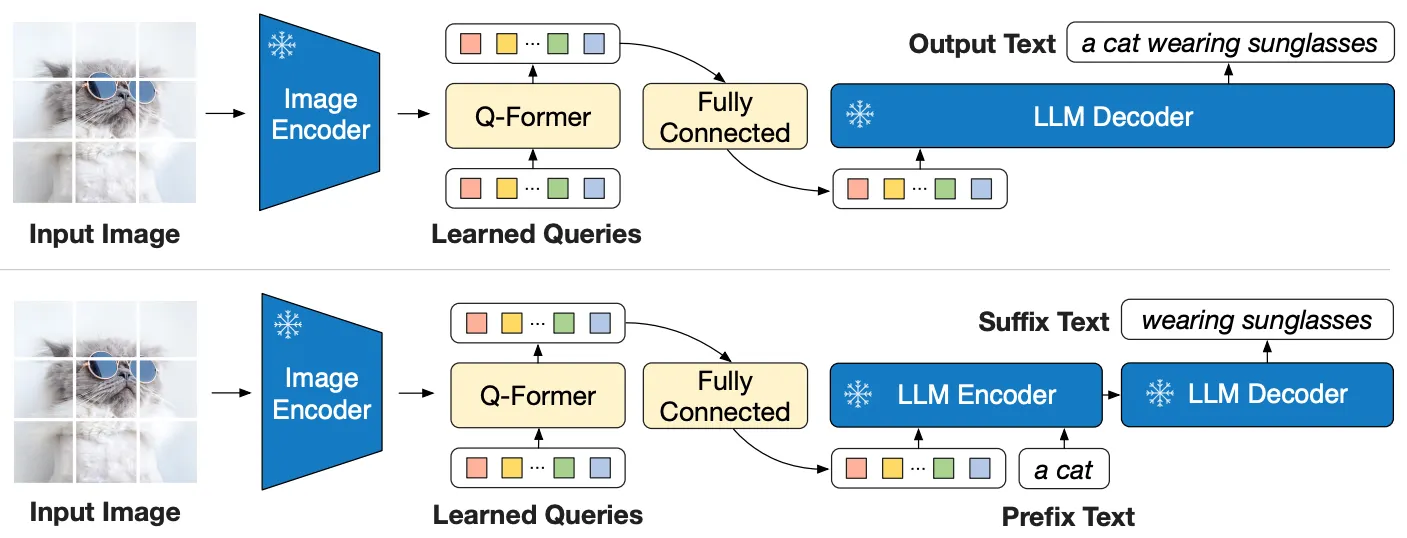
•
2nd-Stage: V-to-L Generative Learning
◦
주어진 Image를 입력받아 출력한 Embedding 값을 (Fully-Connected Layer를 거쳐) Freeze한 LM에 Feed하여 Text를 생성(완성)하도록 학습
◦
2nd-Stage에서는 Text Transformer를 사용하지 않지만, 추후 실험에서 VQA Fine-Tuning or InstructBLIP Training 시에는 Prefix Text를 Image와 함께 Feed하기도 함
Experiments & Results
•
BLIP-2, 제안 모델은 Captions Dataset으로 Pre-Training 수행
•
Pre-Trained LM으로는 OPT or FlanT5 (Instruction-Tuned) 사용
•
Pre-Training 시에 Vision Model + LM의 Params를 FP16으로 변환하여 사용
•
Pre-Training 시에 실제 Update되는 Params는 Q-Former + Query Vector, 약 188M개
•
실험은 크게 다음과 같은 3개 Task에서 수행 → 성능 측정
◦
VQA (Visual Question Answering)
◦
Image Captioning
◦
Image-Text Retrieval
•
각 Task에서 BLIP-2의 Zero-Shot + Fine-Tuned 성능을 모두 측정
◦
Fine-Tuning 시에는 Q-Former와 Vision Model의 Params를 Update
◦
VQA Fine-Tuning 시에는 Q-Former에 Image와 질문 Text를 함께 Feed
•
결론부터 말하면, 모든 Task에서 SOTA의 성능 → 유의미한 결과만 살펴보자!
(Zero-Shot VQA)
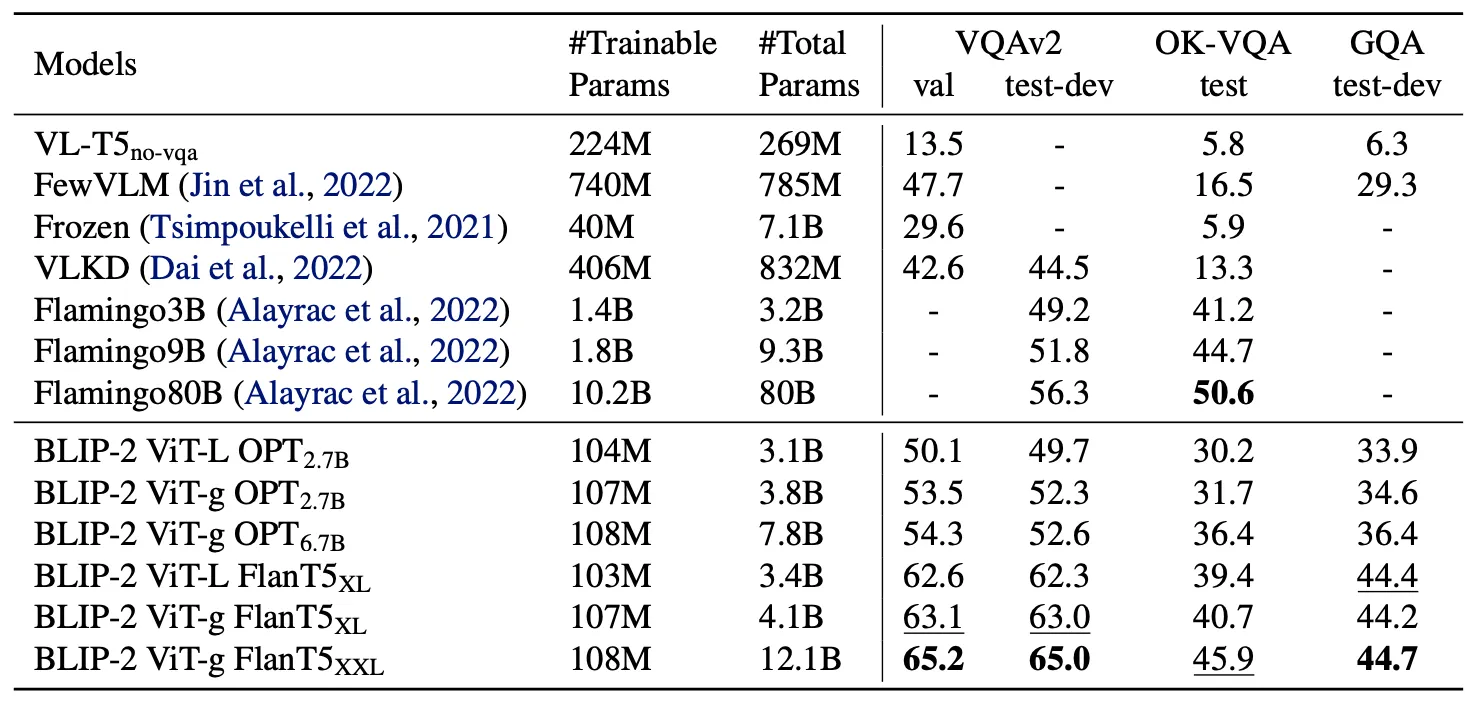
•
기존 모델들에 비해 훨씬 적은 수의 Params를 학습했음에도 가장 좋은 성능을 보임
•
Pre-Trained LM or Vision Model의 Size가 커질수록 좋은 성능을 보임
•
Instruction-Tuning을 수행한 FlanT5가 OPT에 비해 좋은 성능을 보임
(Ablation Study: VL Representation Learning on Zero-Shot VQA)
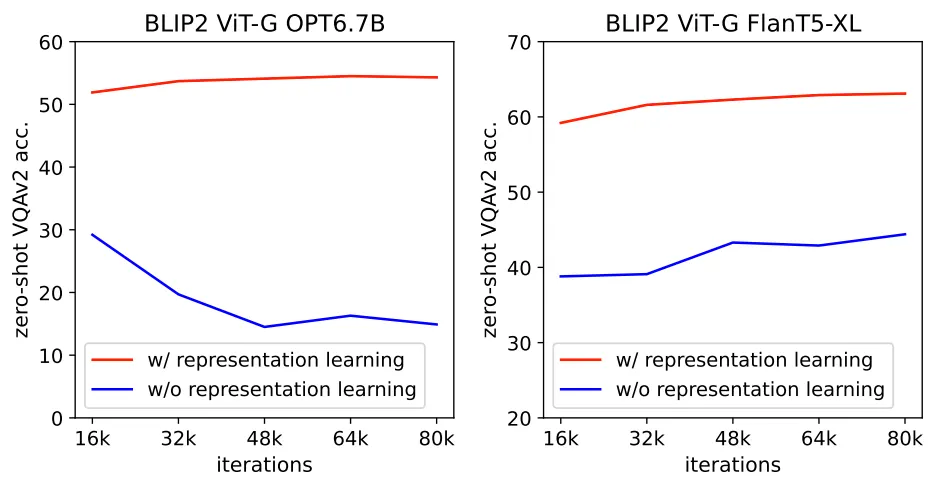
•
VL Representation Learning (1st-Stage Pre-Training): BLIP-2 모델이 Frozen, Flamingo 등 기존의 유사한 모델들과 차별화되는 부분
•
Ablation Study를 통해 BLIP-2의 좋은 성능이 실제로 VL Representation Learning에 기인했음을 확인할 수 있음
(Instructed Zero-Shot Image-to-Text Generation)

•
도입부에 말한 VL Instruction-Following Model, InstructBLIP의 시초가 되는 실험 결과 아닐까..?
•
Instruction Tuning의 궁극적인 목적 → Good Generalization 능력!