
회사 일과 사라진 재택으로 한 달 만에 작성하는 리뷰..
덩달아 사라진 연구&논문에서의 흥미를 되찾기 위해 순수하게 재미있어 보이는 분야 (V-L Models)의 논문을 선정함!!
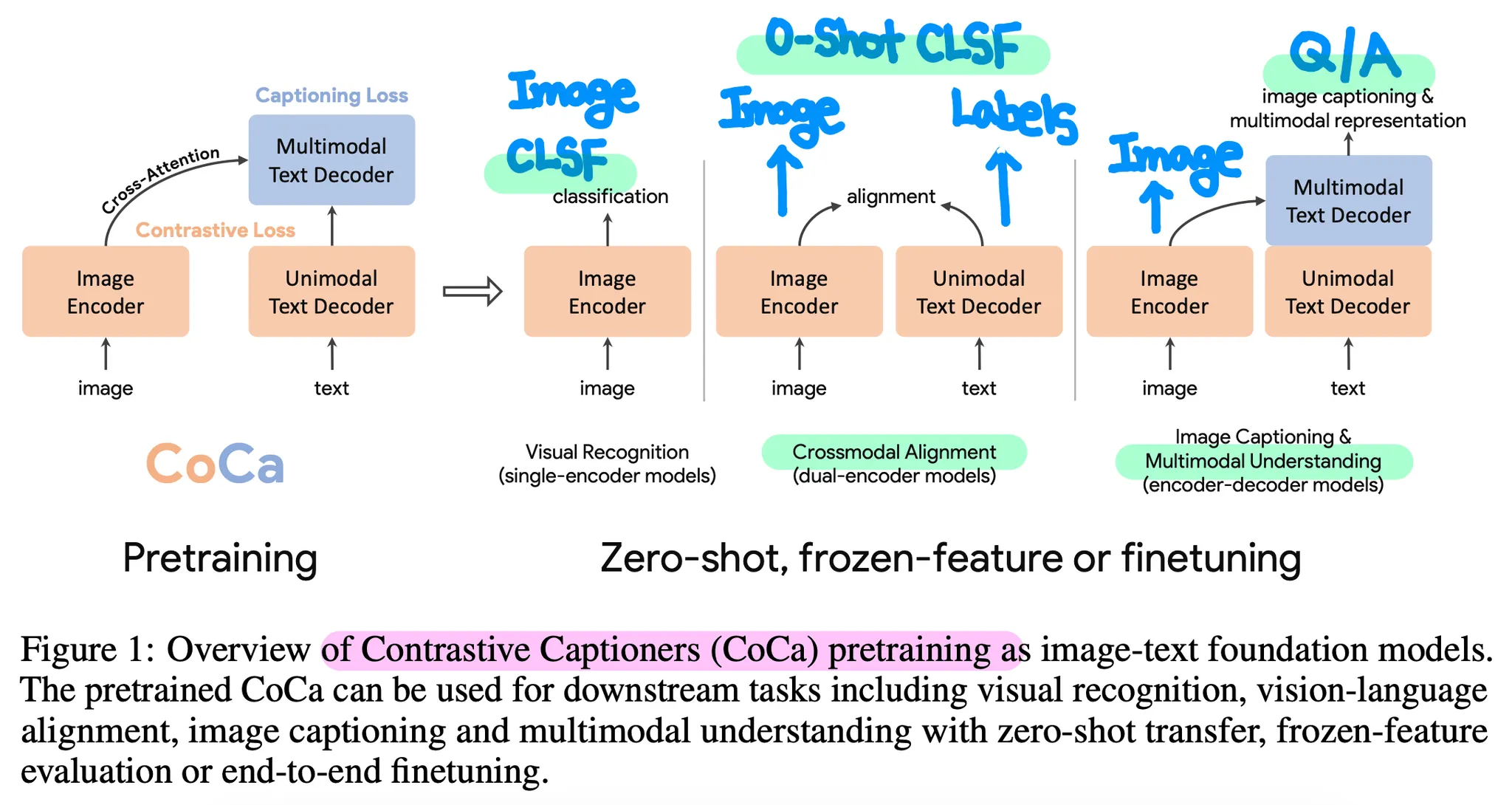
다양한 Vision-Language Tasks (Cross-Modal Alignment, Multi-Modal Understanding 등)을 수행할 수 있는 Google의 Foundation Model.
덩달아 사라진 연구&논문에서의 흥미를 되찾기 위해 순수하게 재미있어 보이는 분야 (V-L Models)의 논문을 선정함!!
다양한 Vision-Language Tasks (Cross-Modal Alignment, Multi-Modal Understanding 등)을 수행할 수 있는 Google의 Foundation Model.Abstract
NLP에서 BERT, RoBERTa 등 Large Pre-Trained Model을 구축하여 다양한 Downstream Tasks에서 좋은 성능을 달성한 것처럼, Vision 혹은 Vision-Language 분야에서도 Foundation Model을 구축하려는 시도들이 존재한다.
(최근에 Pre-Trained Model 대신 Foundation Model이라는 용어가 자주 사용되는데, Stanford에서 시작된 현상으로 보인다.)
•
Single Encoder
◦
가장 고전적인 Vision Foundation Model의 형태
◦
ImageNet 등 Classification Task로 Pre-Training 수행
◦
값비싼 Supervision을 필요로 하는 단점
•
Dual Encoder
◦
인터넷 상의 Noisy한 Image-Text 쌍으로부터 약한 Supervision을 추출하여 학습에 활용
◦
CLIP이 대표적인 예시로, Contrastive Loss 사용
◦
Zero-Shot Image Classification, Image-Text Retrieval 등 Cross-Modal Alignment에서 좋은 성능을 보이지만, VQA 등 Multi-Modal Understanding을 직접적으로 수행할 수 없음
◦
(VQA의 경우는 Decoder의 부재로 인한 한계라고도 생각할 수 있음)
•
Encoder-Decoder
◦
◦
VQA 등 Multi-Modal Understanding에 강점이 있지만, 독립적인 Text Representations를 추출할 수 없기에 Cross-Modal Alignment를 수행하기 어려움 (Dual Encoder와 상호보완)
본 논문은 위에서 언급한 3가지 형태를 통합(Unify)한 구조의 Foundation Model, CoCa를 제안한다.
Proposed Model: CoCa
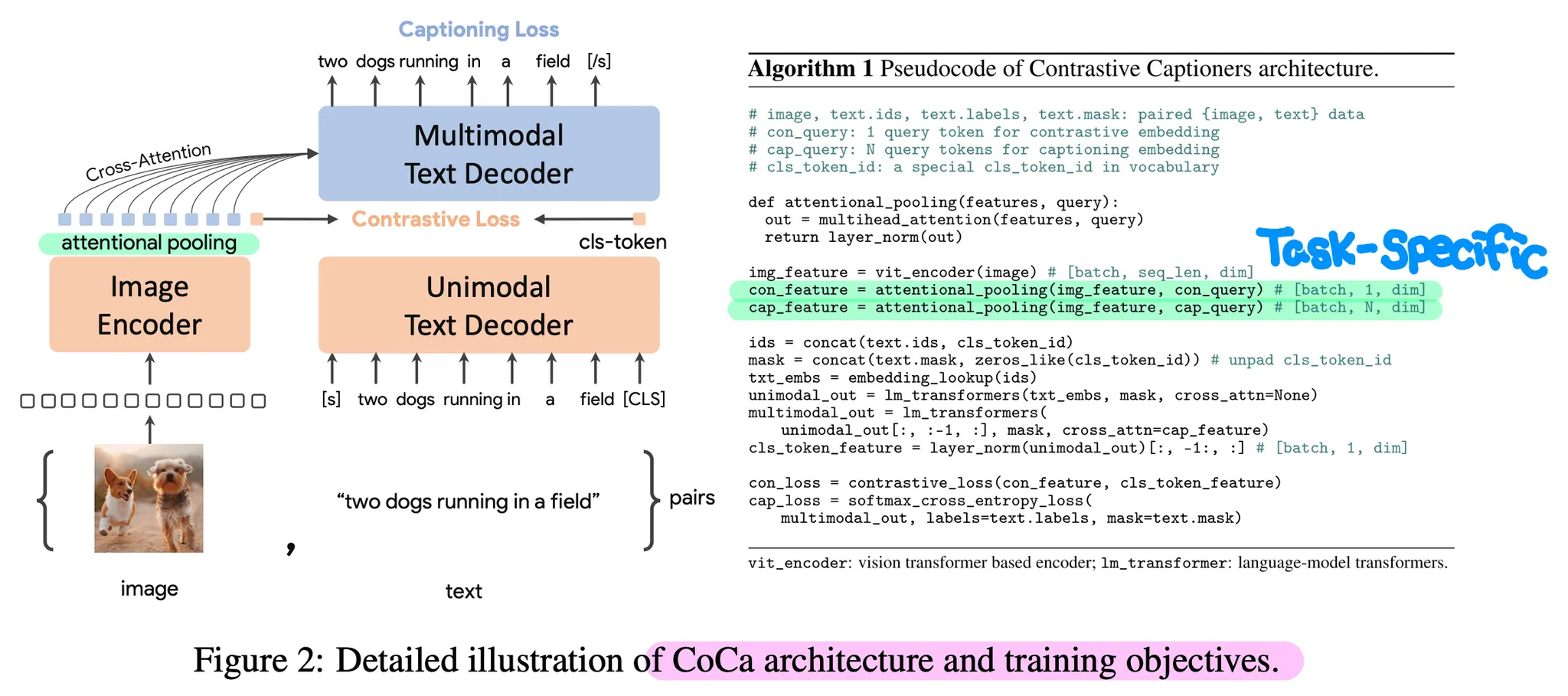
CoCa는 2개의 파트로 나누어진 Decoder 구조와 Contrastive 및 Captioning (Casual LM) Loss를 동시에 사용하는 점이 핵심 특징이다.
•
Decoupled Text Decoder
◦
CoCa는 기본적으로 Image Encoder-Text Decoder 구조
◦
Decoder는 Unimodal (such as GPT) 파트와 Multi-Modal (such as T5) 파트로 분리되어 있음
◦
Decoder Input에 [CLS] Token을 Append하고, Unimodal 파트 이후 임베딩 값을 Text Representations로 취급하여 Image Representations와 Contrastive Loss 계산
◦
Multi-Modal 파트는 Image Tokens의 임베딩 값을 Attend하여 Text Generation을 수행하고, Captioning (Casual LM) Loss 계산
◦
Contrastive Loss는 Image/Text의 Global Feature를, Captioning Loss는 Fine-Grained Feature를 캐치
◦
(실험을 통해 Captioning Loss의 효과를 증명)
•
Attentional Pooler
◦
Image Encoder 이후 각 Loss와 Downstream Tasks에 맞게 독립적으로 Attentional Pooling 수행
◦
Loss/Task 별로 Attention Query를 정의하고 이를 학습하는 방식
◦
(실험에서 Encoder는 고정시키고, Pooler만 학습하는 Fine-Tuning 방식을 제안)
•
Pre-Training Efficiency
◦
한 번의 Forwarding으로 Contrastive 및 Captioning Loss를 계산하여 효율적인 학습이 가능