
지난 포스팅에 이은 LM Calibration 2편!
LM의 Calibration 성능 향상을 위한 기법들과 그 효과를 정리한다.
Previous Post
•
지난 포스팅에서 최근 딥러닝 모델들의 좋지 않은 Calibration 성능이 모델 사이즈 Scaling-Up에 의해 증가한 Model Capacity로부터 비롯되었음을 알 수 있었다
•
(Chen et al., 2022)은 모델 학습 과정에서 Over-Fitting이 Calibration 성능을 감소시킨다고 주장하였고, (Guo et al., 2017)은 강한 Regularization이 Calibration 성능 감소를 막을 수 있다며 궤를 같이하였다
•
본 포스팅에서는 위의 두 논문이 소개/제시한 Calibration 기법들을 정리한다
Calibration Methods
가장 먼저 생각할 수 있는 방법은 모델의 출력 Confidence를 사후적으로 조정 (Post-Processing)하는 것이다
•
Histogram Binning
◦
출력 Confidence를 M개의 구간 (Bin)으로 나누고, 각 구간에 조정된 Confidence를 부여하는 기법
◦
ex) Confidence를 10개 구간 (0.0~0.1 / 0.1~0.2 / … / 0.9~1.0)으로 나누고, 각 구간에 조정된 Confidence (0.07 / 0.15 / … / 0.93)를 부여. 데이터 x에 대한 모델의 원본 Confidence가 0.95일 때, 이를 0.93으로 조정
◦
구간은 일정 길이로 나누거나 or 각 구간에 속한 데이터의 수가 동일하도록 나눈다
◦
각 구간에 부여하는 Confidence 값은 구간별 (Confidence와 Label 간) Squared Loss가 가장 작아지도록 조정
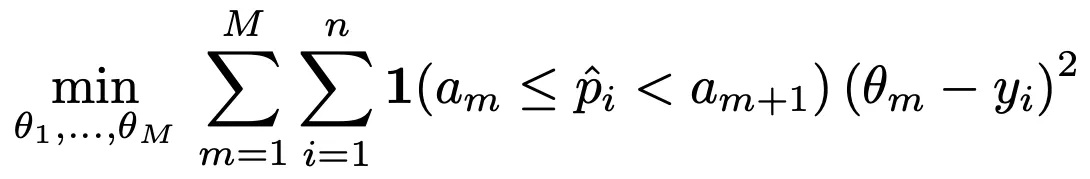
◦
•
Isotonic Regression
◦
Histogram Binning의 변형 버전
◦
•
Platt Scaling
◦
◦
분류 모델의 Logits 값을 입력으로 받아 조정 Confidence 값을 출력하는 Logistic Regression 모델 활용
◦
Validation Set을 활용하여 Negative Log Likelihood 값이 작아지도록 모델 학습
•
Temperature Scaling
◦
(Guo et al., 2017)이 제안한 Platt Scaling의 간단한 변형 버전
◦
Logits 값에 Softmax를 적용하기 전.. 단일 Scalar 값, T (> 1)로 나눠준다 → “Soften” Softmax
◦
다중 Class 분류 시에도 사용 가능 → 분류 Accuracy 변화x (Class별 Logit 값이 동일하게 감소/증가)
다음은 모델의 학습/추론 과정에 Regularization 등의 기법을 적용하는 방법이다
•
Label Smoothing
◦
◦
Hard Label (ex. [0 1 0 0]) 대신 Soft Label (ex. [0.02 0.94 0.02 0.02])을 활용하여 모델 학습
•
Data Augmentation
◦
Regularization과 유사하게 모델 Robustness 향상 효과가 있을 것 같다.. (대충 이해)
•
Model Ensemble
마지막으로 메인 분류 모델 이외에 Calibration을 위한 별도의 분류 모델을 활용하는 방법이다
•
원본 데이터 x와 모델의 예측 y를 입력받아 모델의 원본 예측이 옳은지 판별하는 별도의 분류 모델 학습 → Validation Set 활용
•

•
(Chen et al., 2022)은 별도의 (Extrinsic) 분류 모델로 MLP or T5 학습 → E-MLP or E-T5
•
또한, (Chen et al., 2022)은 메인 분류 모델이 자체적으로 (Intrinsic) 신뢰도를 출력하도록 학습
◦
I-Vanilla: 메인 분류 Task 학습 → Calibration Task 학습. 그러나 메인 Task 성능이 감소
◦
I-Iter: 메인 분류 Task, Calibration Task를 반복적으로 학습
◦
I-Simul: 메인 분류 Task, Calibration Task를 동시에 학습
Calibration Performance
•
(Chen et al., 2022)은 RoBERTa / T5 분류 모델에 Calibration 기법들을 적용하여 그 성능을 관찰한다
•
실험은 In-Distribution (ID) / Out-of-Distribution (OOD) 세팅에서 진행한다
•
아래 표는 T5 분류 모델에 대한 실험 결과이며, 공간 제약으로 인해 원본 표 일부를 잘라내었다
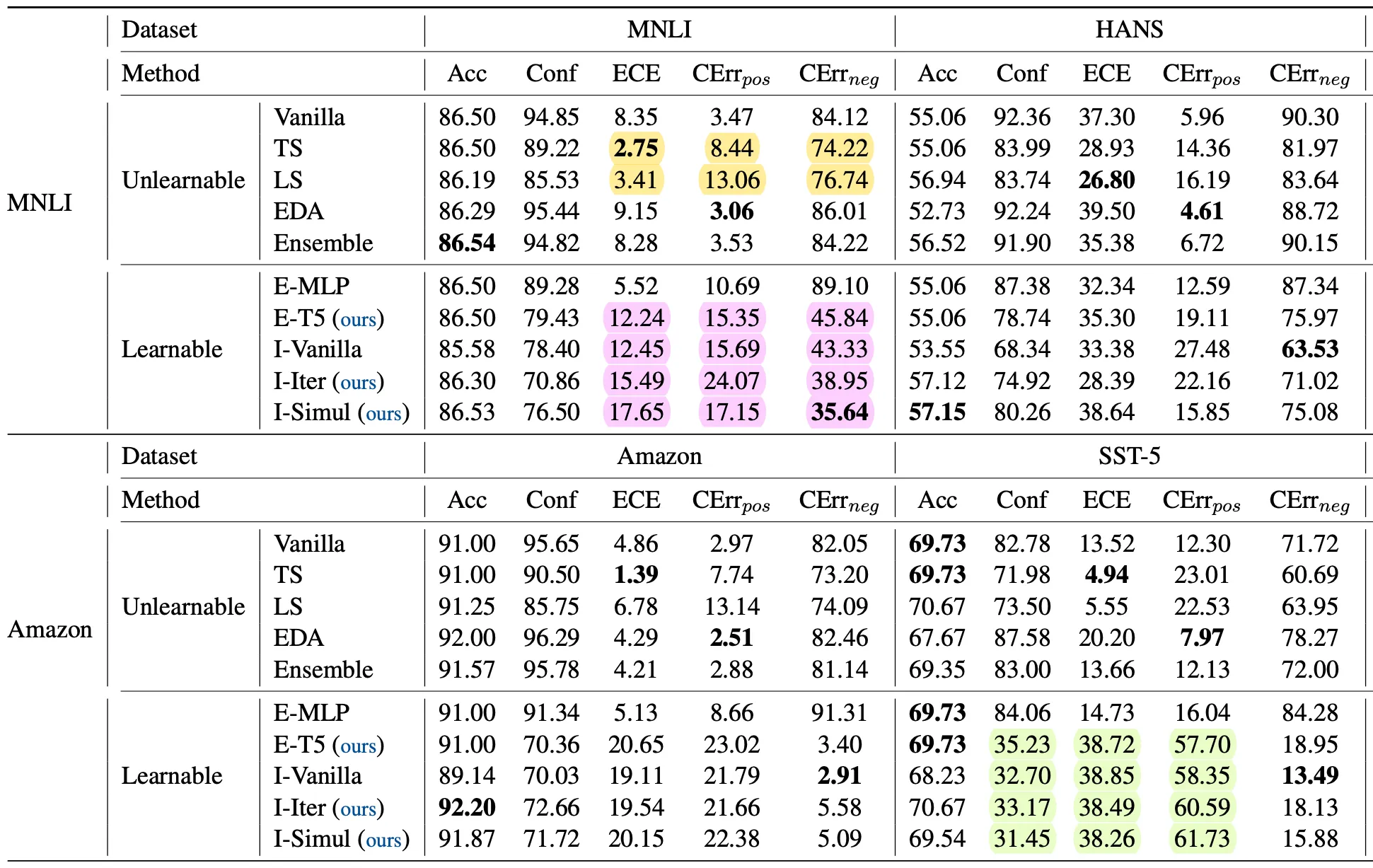
실험 결과..
•
•
Temperature Scaling (TS)과 Label Smoothing (LS)은 ECE 수치상 가장 좋은 성능을 보임
◦
위 표의 노란색 하이라이팅 참조
•
Calibration을 위한 분류 모델을 추가 학습하는 경우 잘못된 예측에 대한 Confidence가 대폭 감소 → CErr_neg 감소
◦
위 표의 분홍색 하이라이팅 참조
•
Calibration을 위한 분류 모델을 추가 학습하는 경우 OOD 세팅에서 Confidence 값이 대폭 감소
◦
위 표의 연두색 하이라이팅 참조
◦
OOD 세팅에서는 모델이 학습하지 않은 도메인의 데이터를 추론하는 것이므로 예측 결과에 대한 신뢰도가 작은 편이 합리적으로 생각됨
◦
단, ECE와 CErr_pos 값이 대폭 오르는 경향성이 있음