
최근 회사에서 주어진 텍스트가 특정 Class에 속하는지 여부 (True or False)를 검사하는 Binary Classification 혹은 Detection 모델을 학습하였다.
학습된 모델은 교육 현장에서 교수자의 과제물 채점을 보조하는 서비스에 탑재되기 때문에 모델의 잘못된 Prediction 결과가 학생들의 억울함을 초래할 수 있다.
가장 좋은 예방 방법은 모델의 성능 자체를 끌어올리는 것이지만, 모델의 성능이 언제나 100%가 된다고 보장할 수 없기에.. 모델 Prediction 결과에 대한 신뢰도 (Confidence)를 고객에게 함께 제공해야 한다고 생각한다.
하지만 불행하게도 최근 딥러닝 모델들의 Calibration 성능이 좋지 못하다는 연구들이 다수 존재하고.. 본인은 ACL 2023에서 공개된 LM의 Calibration에 관한 Survey 논문을 리뷰하여 대응책을 준비하려 한다!
Reviewed Papers
(Guo et al., 2017)
(Chen et al., 2022)

Calibration Metric
•
딥러닝 분류 모델은 예측 클래스 (Predicted Class Label)와 함께 이에 대한 신뢰도 (Confidence)를 출력할 수 있다
◦
ex) 모델이 입력 데이터 x에 대해 클래스 A/B/C에 속할 각 확률 (Logit)을 0.65/0.2/0.15로 예측했을 때 → 예측 클래스는 A이고, 신뢰도는 65%이다
•
Calibration이란 모델이 실제로 정확한 (Ground Truth) 신뢰도를 출력하는 능력을 일컫는 것으로,
◦
모델이 신뢰도 80%로 예측한 데이터 100개 중 80개가 실제로 예측 클래스에 속하게 되는 경우 Calibration 성능이 좋다고 할 수 있다
◦
반대로 모델이 신뢰도 20%로 데이터 100개를 예측한 경우.. 개중 20개 데이터만이 실제 예측 클래스에 속할 때 Calibration 성능이 좋다고 할 수 있다
•
즉, 데이터셋 X에 대해 모델의 신뢰도 평균과 분류 정확도가 동일할 때 (Average Confidence=Accuracy) Calibration 성능이 이상적이라고 할 수 있다
•
(Guo et al., 2017)은 과거 딥러닝 모델들에 비해 현재 딥러닝 모델들이 더 좋은 분류 성능을 보이지만, Calibration 성능은 그렇지 못함을 지적한다
◦
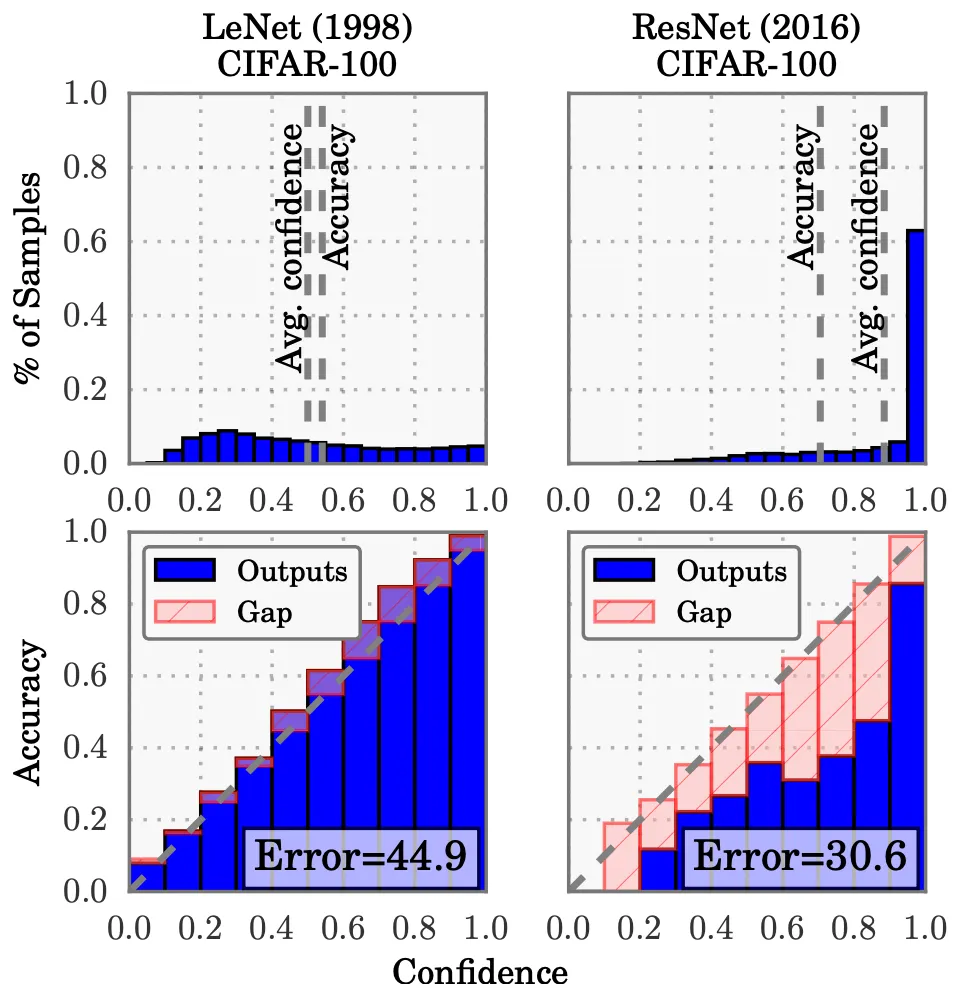
5-Layer LeNet (1998) vs 110-Layer ResNet (2016).. 아래 그림 상단 참조
•
대표적인 Calibration 성능 측정법은 Reliability Diagram을 그리는 것이다 (위 그림 하단 참조)
◦
n개의 데이터를 모델의 예측 신뢰도를 기반으로 m개의 구간으로 나누고 (x축),
◦
각 구간의 데이터 집합을 대상으로 분류 정확도를 계산한다 (y축)
◦
Diagram이 y=x 축과 가깝게 그려질수록 좋은 성능
•
위 Diagram에서 정량적으로 오차를 측정하는 ECE (Expected Calibration Error)도 대표적인 성능 지표이다 (위 그림 하단 참조)
◦
각 구간별로 신뢰도 평균과 분류 정확도 간의 오차를 계산한 후 이들을 평균낸 값
◦
값이 작을수록 좋은 성능
•
(Guo et al., 2017)은 NLL (Negative Log Likelihood)을 Calibration 성능 지표로 활용할 수 있다고 주장한다
•
(Chen et al., 2022)은 조금 더 Practical (Application-driven)한 성능 지표를 제시한다
◦
CErr_pos: 정답 예측이 낮은 신뢰도로 인해 기각되는 경우 가정. (1 - 올바르게 예측한 데이터 집합의 신뢰도 평균)으로 계산
◦
CErr_neg: 오답 예측이 높은 신뢰도로 인해 채택되는 경우 가정. (잘못 예측된 데이터 집합의 신뢰도 평균)으로 계산
◦
두 지표 모두 값이 작을수록 좋은 성능
Observing Calibration
•
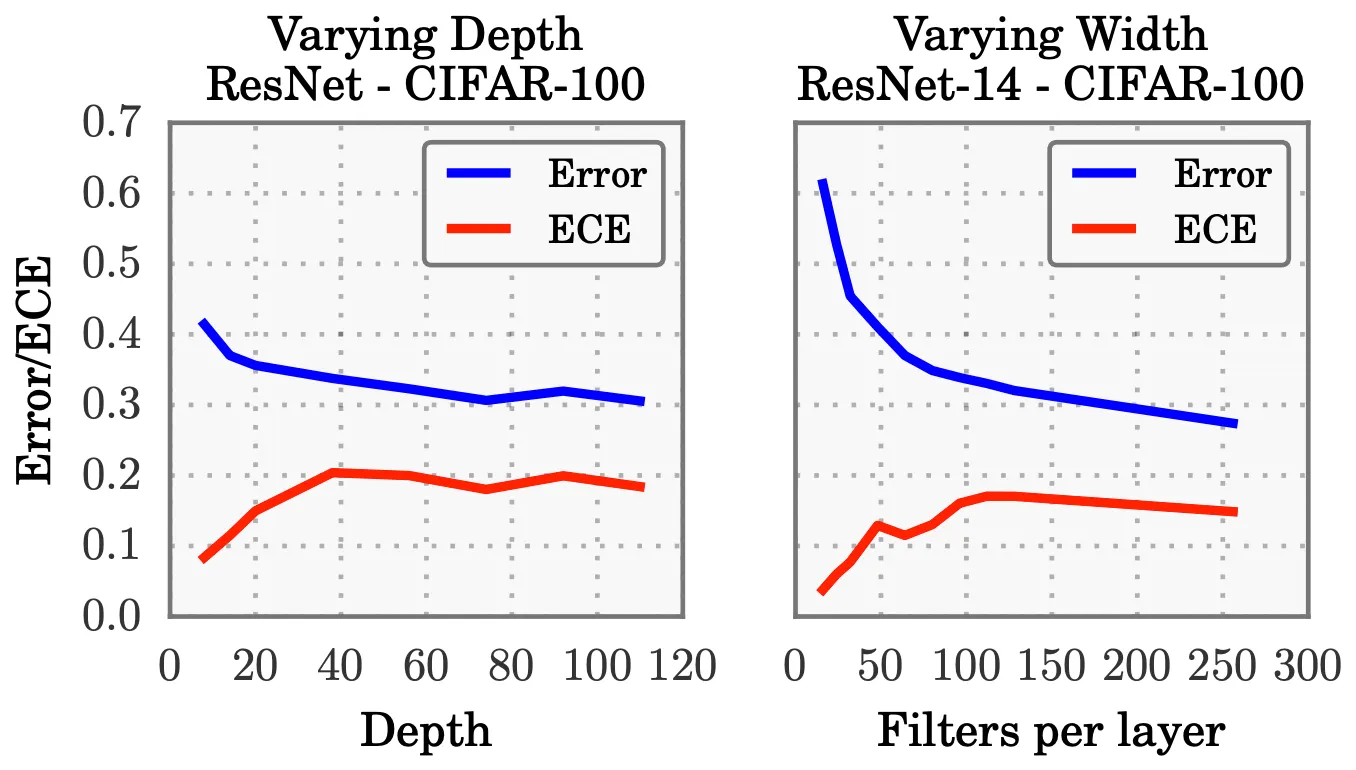
(Guo et al., 2017)은 CNN 계열의 ResNet 모델 구조를 변경하여 Calibration 성능에 영향을 미치는 요인들을 분석한다
•
Calibration 성능에 가장 중요한 요인 중 하나는 모델의 크기이다 (위 그림 참조)
◦
최근 딥러닝 모델들의 크기가 Scaling-Up 되면서 Model Capacity가 증가하였고,
◦
학습 과정에서 모델은 학습 데이터 대부분을 정확히 분류하는 것을 넘어 예측 신뢰도 값을 키워 Log Likelihood 값이 커지도록 (NLL Loss 감소) 학습된다
◦
이 과정에서 모델의 Over-Confident한 경향성이 나타나고.. Calibration 성능이 감소하게 된다
•
또한, Batch Normalization이 Calibration 성능을 감소시키고, 반대로 강한 Regularization (Weight Decay) 기법이 Calibration 성능을 향상시킨다고 주장한다
•
(Chen et al., 2022)은 RoBERTa와 T5-base 모델을 4가지 Task (감성 분석, NLI, 뉴스 분류, 토픽 분류)에서 실험해가며 Calibration 성능에 영향을 미치는 요인들 (학습 길이, 모델 크기 등)을 분석한다
•
실험은 독특하게도 모델을 Full Fine-Tuning하지 않고, Prompt-based Learning & Parameter-Efficient Learning (Soft Prompt, Adapter) 방식으로 학습시켜 진행한다
◦
해당 방식들이 보편적이지 않다는 뜻이 아니라.. 굳이 Full Fine-Tuning을 하지 않을 이유가 있었을까..? 하는 의문
•
실험 결과는 다소 복잡하지만, (Guo et al., 2017)와 비슷하게 모델의 크기를 중요한 한 요인으로 지적한다
◦
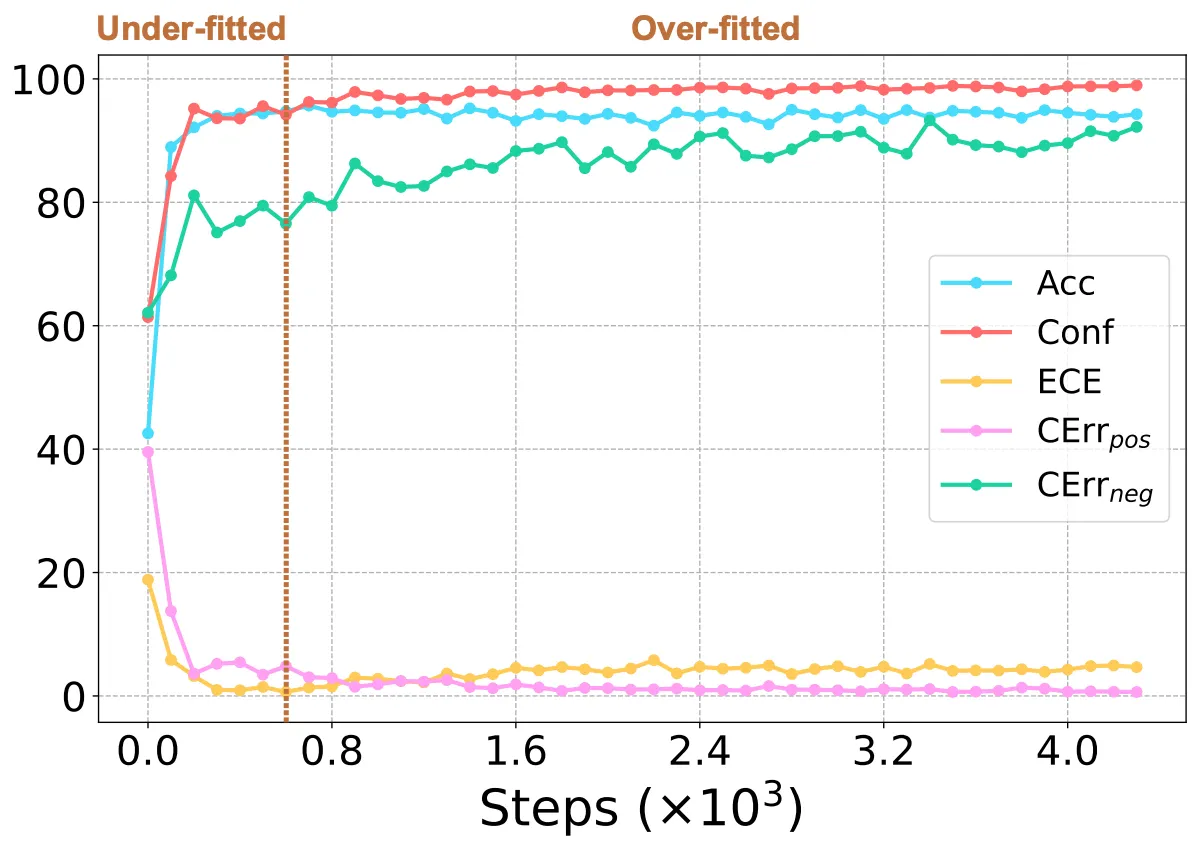
모델의 크기가 커지면서 학습 과정에서 분류 성능은 그대로 & 신뢰도만 증가하는 과적합 (Over-Fitting)이 발생하고, 이때 ECE와 CErr_neg 값이 계속해서 증가하는 모습을 확인할 수 있다 (위 그림 참조)
◦
저자는 난이도가 높은 BIG-bench 데이터셋에서 성능을 테스트하여 모델이 충분히 학습되지 않은 상태에서 실험을 진행했다는 논리를 들어 Larger PLMs이 좋은 Calibration 성능을 보인다는 기존의 연구를 반박한다 (정확히 이해x)
•
또한, PLM에 대해 다음과 같이 설명하며 다른 성능 지표보다 CErr_neg에 더욱 초점을 둔다
◦
PLMs mostly don’t know “what they don’t know”