
효율적인 Size(7B)의 Instruction-following 모델: Stanford Alpaca 리뷰..
Stanford Alpaca
•
ChatGPT가 GPT-3, PaLM 등 기존의 Large LM들에 비해 특히 각광을 받고, 유용하다고 생각되는 이유는 간단하게 작성된 사람의 명령(Instruction)을 곧잘 알아듣기 때문임
◦
9~540B Size의 기존 LLM들도 충분한 지식(Knowledge) 수준을 갖췄지만, 단지 간단한 텍스트 형태의 명령을 수행하는 능력이 부족할 뿐이며 → 이는 사람이 작성한 명령어-모델 출력 쌍으로 구성된 Instruction-following Dataset으로 LLM을 Fine-Tuning함으로써 보완됨 (이전 포스팅 참고)
•
그러나, 현재 ChatGPT와 같은 대부분의 Instruction-following 모델들은 접근이 불가능하며, 직접 구축을 하기에도 다음과 같은 제약 조건들이 존재
◦
강력한 성능의 PLM: 일반적으로 큰 Size
◦
고품질의 Instruction-following Dataset
•
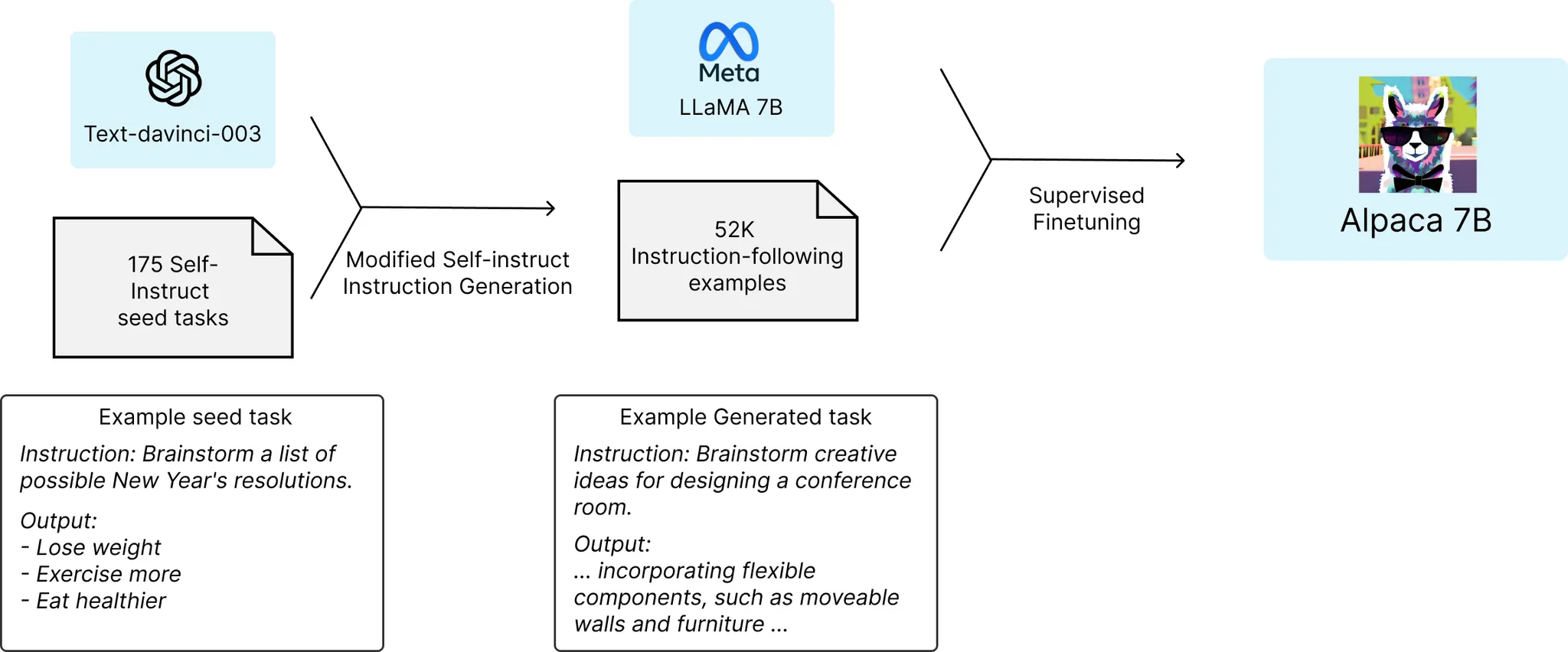
Stanford CRFM에서는 효율적인 Size(7B)의 Instruction-following 모델, Alpaca 구축을 위해 다음과 같은 방법을 사용
◦
Meta에서 공개한 PLM, LLaMA를 기반 모델로 사용


▪
상대적으로 작은 Size(7~65B)의 모델을 더욱 길게(More Tokens) 학습시킴 → 좋은 성능
▪
Meta AI는 작년부터 OPT, BlenderBot 3 등의 LLM들을 대중(연구자)들에게 공개하고 있음
▪
하지만, 아쉽게도 20개국어만을 지원(한국어x)
◦
Self-Instruct 기법(추후 공부 예정)과 OpenAI의 text-davinci-003 API를 활용하여 Instruction-following Dataset 구축
▪
PLM을 활용하여, 사람의 개입을 최소화한 Instruction-following Dataset 구축 Pipeline 제안
•
결과적으로, 적은 비용으로 text-davinci-003(InstructGPT 기반)에 버금가는 성능의 모델을 구축
◦
클라우드 컴퓨팅 서비스에서 A100 80GB 8대, 3시간 학습 → 100달러
◦
text-davinci-003 API 호출하여 52K개 명령어-출력 쌍 생성 → 500달러