
EMNLP 2021에서 공개한 Apple의 Controlled Data-To-Text Generation Paper.
지난 주에 리뷰한 TWT와 유사한 연구지만, 어떤 내용을 생성할지 (What To Generate)보다 생성할 내용의 순서 (In What Order)에 초점을 맞춘 점,
그리고 WebNLG와 같은 Graphical Data에도 적용할 수 있다는 것이 차이점!
Abstract
TWT와 비슷하게 Neural Model 기반의 Data-To-Text Generation 기법들은 생성 문장의 구조 (내용의 순서)를 조절하는 능력 (Controllability)이 결여된 점을 지적함.
문장의 구조는 Naturalness와 밀접한 관련이 있는데, 예를 들어, Levels는 어떤 Artist의 곡이야? 라는 질문에 Levels는 Avicii의 곡이야 라는 답과 Avicii는 Levels를 작곡했어 라는 답변은 의미적으로 동일하지만 전자의 경우가 훨씬 자연스러운 것을 알 수 있음.
추가로, 생성 문장의 구조를 조절할 수 있다는 점은 Generation의 다양성을 확보할 수 있다는 뜻임.
본 논문은 주어진 데이터에 가장 적합한 문장 구조 (Content Plan)를 파악하여, 이를 기반으로 문장을 생성하는 Framework, PlanGen을 제안함.
Dataset
논문에서 다루는 Dataset은 ToTTo (Tabular Data)와 WebNLG (Graphical Data) 2종류.
•
ToTTo는 (Slot Key, Slot Value) 쌍의 집합인 Data와 정답 문장 집합 References로 구성
e.g. (Reference) Levels는 Sweden 출신 Avicii의 곡이다
Avicii
(Slot Key) | (Slot Value) |
Song | Levels |
Country | Sweden |
•
WebNLG는 (Subject, Predicate, Object)의 RDF Triple 집합 Data와 References로 구성
e.g. (Levels, Artist, Avicii) (Avicii, Country, Sweden)으로부터 Levels는 Sweden 출신 Avicii의 곡이다
그러나 2종류의 Dataset 모두 Content Plan을 포함하지 않음. 본 논문은 Heuristic Delexicalizer, F를 활용하여 Reference로부터 (정답) Content Plan을 추출.
Reference의 Slot Value들을 해당 Slot Key로 치환하는 방식. (Graphical Data는 Predicate 치환)
e.g. Levels는 Sweden 출신 Avicii의 곡이다로부터 (Content Plan) Song -> Country 추출
Proposed Model: PlanGen
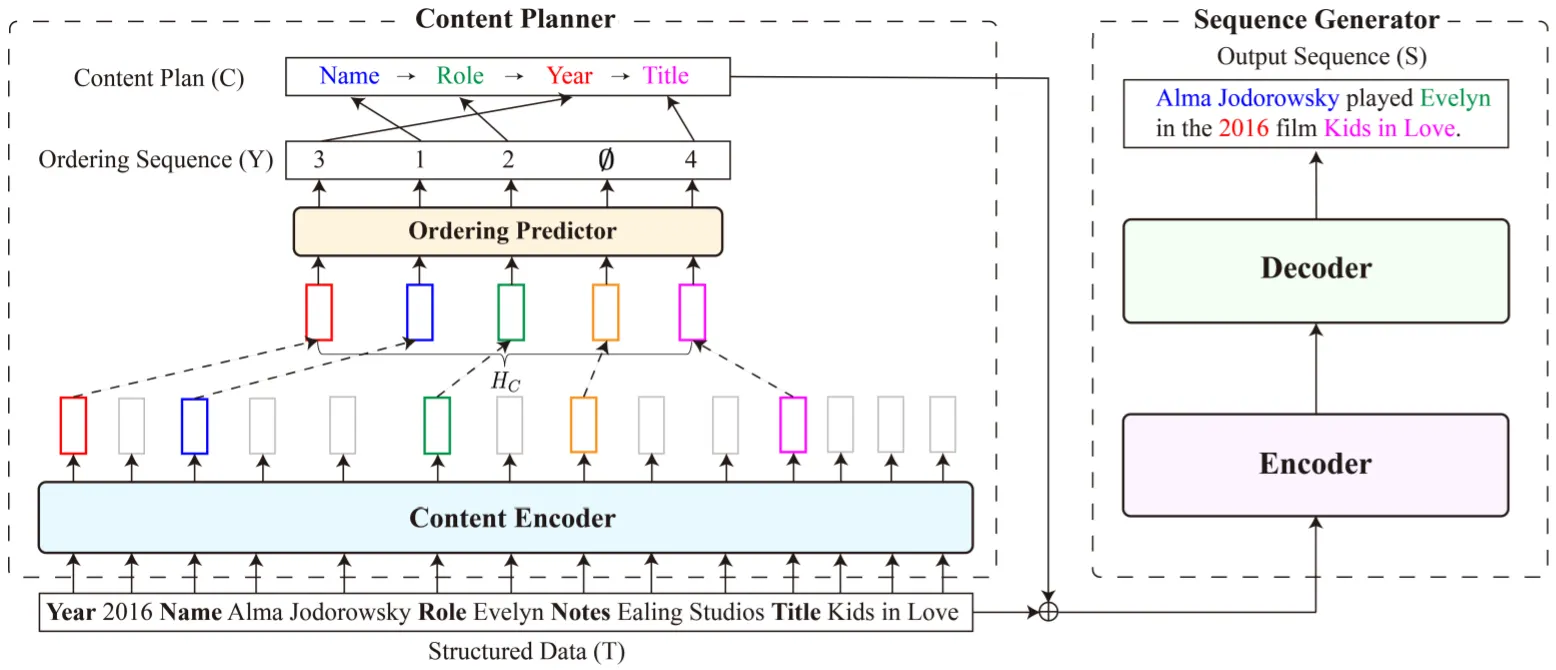
주어진 데이터로부터 가장 적합한 생성 문장의 구조 (Content Plan)를 추출하는 Content Planner와 이를 기반으로 문장을 생성하는 Sequence Generator로 구성.
또한, Structure-Aware Reinforcement Learning을 활용.
•
Content Planner
◦
선형화된 입력 데이터를 Encoding하는 Content Encoder와 Slot Key에 해당하는 Encoded Token들로부터 Content Plan을 추출하는 Ordering Predictor로 구성
◦
Content Encoder로는 Pre-Trained BERT-base를, Ordering Predictor로는 Linear-Chain CRF를 차용
◦
•
Sequence Generator
◦
BART-base 차용
•
Structure-Aware RL
◦
생성한 완성된 문장으로부터 Reward 계산
◦
Reward=BLEU(정답 문장, 생성 문장)+BLEU(Content Plan, F(생성된 문장))
Sequence Generator는 초반 10k Steps에서 Casual LM Objective만으로 학습되고, 이후에는 Structure-Aware RL Objective를 추가하여 학습됨.
Experiments & Results
메인 실험은 ToTTo, WebNLG Test Set으로 수행하며 BLEU, PARENT, BLEURT, METEOR의 Metric으로 제안 모델의 성능을 평가함.
실험을 통해 거의 모든 Metric에서 제안 모델이 유사한 다른 모델들에 비해 좋은 성능을 보이는 것을 증명함. (표 생략)
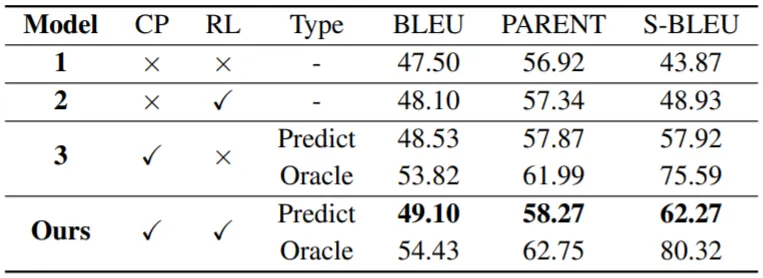
ToTTo Validation Set에서 수행한 Ablation Study (위 표)와 Case Study (아래 표)가 흥미로운데, 결과를 살펴보면,
•
위 표의 Predict는 Content Planner에서 추출한 Planning Signal로부터 생성한 결과를, Oracle은 F로부터 추출한 (정답) Content Plan으로부터 생성한 결과를 나타냄
•
S-BLEU는 BLEU(Content Plan, F(생성된 문장)) Score로 Content Plan이 Generation에 반영이 되는 정도를 나타냄
•
실험 결과, Content Plan과 Structure-Aware RL 모두 성능 향상에 중요한 요소임을 알 수 있음
•
Predict와 Oracle의 차이를 통해 Content Plan의 Quality가 Generation 성능에 큰 영향을 미침을 확인할 수 있음
•
아래의 표에서 단순히 Content Plan의 순서를 바꾸는 것으로 다양한 구조의 Quality 높은 문장을 생성할 수 있음 (Controllability, Diversity)을 보임
•
일부 에러 (우측 최하단 Cell)를 통해 Content Plan에 따라 Generation 성능이 달라짐을 다시 확인 가능함
•
이는 학습 과정에서 모델이 접하는 Content Plan이 (주로 정답의 Case에) 한정되어 있기 때문
