
EMNLP 2021에서 공개된 Controlled Text Generation Paper.
Sentiment & Topic Control에 Prefix-Tuning을 적용한 느낌.
핵심 아이디어는 LM이 학습 데이터의 Domain 특징을 포함하지 않는, 순수한 Target 속성의 Text를 생성하도록 하는 점..!
나의 실력 부족이 가장 큰 원인이겠지만, 유난히 읽기에 난해하고 납득이 어려운 내용들이 다수 존재했던 Paper.. (GitHub도 404 Error)
Abstract
(기존 Controlled Generation 기법들의 문제점)
CTRL과 같이 Control Codes를 Prompt에 Prepend하여 LM을 학습 (From Scratch or Fine-Tune)시키는 기법들은 큰 Computational Cost를 필요로 함. (via Large-Sized LM)
PPLM과 같이 Discriminator를 활용하여 LM의 Hidden States를 Perturb하거나, Output (Next Token) Distribution을 Re-Weight하는 기법들은 LM의 성능 (Fluency 등)을 저하시키고, Inference가 느림.
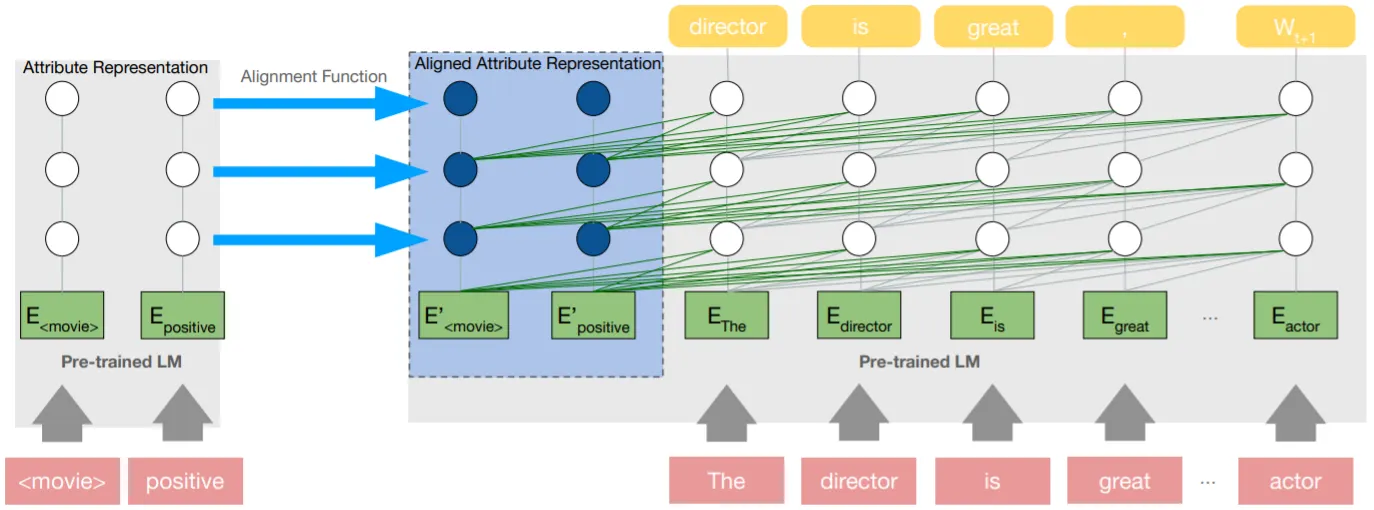
본 논문은 Prefix-Tuning과 유사하게, LM이 원하는 속성의 Text를 생성하도록 Past Key-Values (Attribute Representations)를 제공하는 Attribute Alignment 기법을 제안함.
•
Attribute Representations를 직접 생성하는 Prefix-Tuning과 달리, 속성 Text (Positive, Negative, Economy, Sports etc)를 Pre-Trained LM으로 Encoding한 결과를 Alignment Function에 Feed하여 얻어냄 (위 그림 참조)
•
학습 과정에서 Alignment Function만을 Update하기에 Computationally 효율적이며, Inference 시에 Unseen Attribute Representations를 쉽게 얻을 수 있어 Zero-Shot Inference에 유리함
본 논문의 핵심 Point는 순수한 Target 속성의 Representations를 학습하는 점! 예를 들어, IMDB Reviews로부터 긍/부정의 Text를 학습한 LM은 영화 리뷰와 같은 Text를 생성할 확률이 높은데, 논문은 학습 과정에서 영화 리뷰의 특징과 긍/부정의 특징을 분리하여 학습한 후, 순수한 (영화 리뷰 같지 않은) 긍/부정의 Text를 생성하는 것을 목표로 함.
Proposed Method: Attribute Alignment
제안 기법은 앞서 언급했듯, 학습 데이터의 Domain 특징 (Corpus Domain Representations)과 원하는 속성의 특징 (Attribute Representations)을 분리하여 학습하는 것을 목표로 함.
저자는 4가지 방법론을 제안하는데,
•
Attribute Representation with Alignment Function (A)
◦
핵심 아이디어에 대한 일종의 반례로, Corpus Domain Representations (d)를 분리하지 않고, 단일 Attribute Representations (a)를 학습함
◦
즉, Attribute Representations가 Domain 특징을 포함한다는 의미
•
Attribute Representation with Corpus Representation Disentanglement (AC)
◦
Corpus Domain Representations와 Attribute Representations를 분리하여 학습함 (Alignment Function 역시 2종류)
◦
Inference에서는 Attribute Representations만을 사용함
◦
특이한 점은 Corpus Domain 명칭을 Pre-Trained LM으로 Encoding할 시에 Special Token (<movie review> 등)으로 처리하는 점. 학습 과정에서 LM은 Update되지 않기 때문에 해당 Token은 Random한 값을 갖게 되는데, 실제로 사용할 Representations가 아니므로 큰 신경을 쓰지 않는 것으로 추측함
•
KL Disentanglement (ACK)
◦
AC에 KL-Divergence 항을 추가하여 LM의 Distribution이 원본에 크게 벗어나지 않도록 함
◦
LM의 Distribution이 Domain-Specific한 Tokens에 쏠리지 않도록 하는 의도이나, 원하는 속성의 Tokens을 생성할 확률 역시 감소함
•
Bayes Disentanglement (ACB)
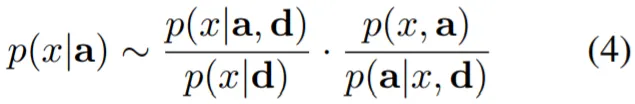
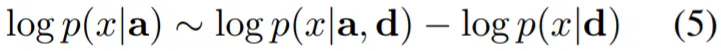
◦
Bayes Rule에 기반하여 (4)식을 얻어냄. 저자는 학습 과정에서 p(a|x,d)는 Uniform하다고 가정하기 때문에 상수로 취급할 수 있고, p(x,a)는 Pre-Trained LM으로부터 유추(?)할 수 있으므로 생략하여, 최종적으로 (5)식의 학습 목표를 제시함
Experiments & Results
실험은 Sentiment & Topic을 Control하는 2종류.
Dataset은 SST (for Sentiment), AG News & DBpedia (for Topic) 사용.
Evaluation은 Attribute Relevance, Training Corpus Resemblance 그리고 Linguistic Quality 3종류로, Automatic & Human Eval 모두 진행.
Baselines으로는 다음과 같은 모델 사용.
•
GPT2 (Medium)
•
GPT2-Concat (Prepend Control Token before Prompt)
•
GPT2-Finetune
•
PPLM
•
GeDi
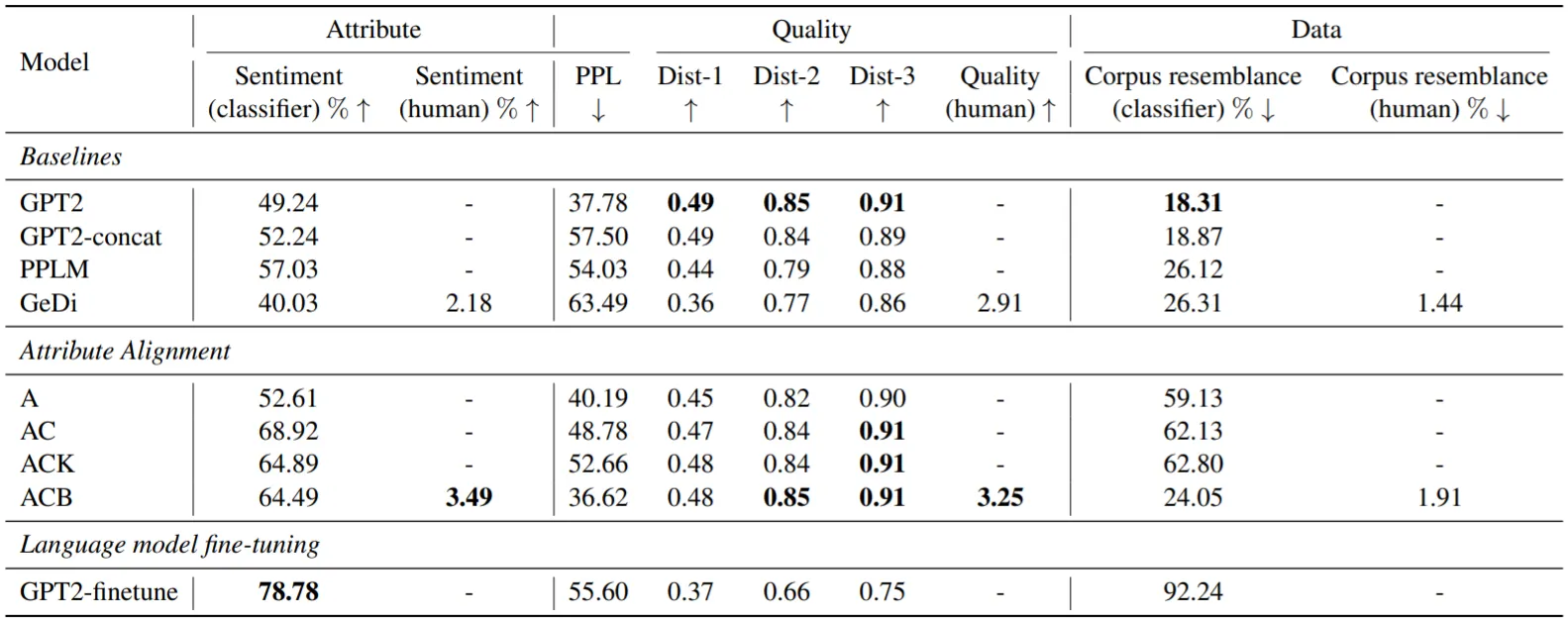
Sentiment Control 실험 결과,
•
Fine-Tuned GPT2에는 미치지 못하지만, 제안 기법들이 다른 Baselines에 비해 높은 Attribute Relevance를 보임
•
ACB의 경우, Training Corpus Resemblance와 Linguistic Quality에서도 좋은 성능을 보임
•
다만, GeDi의 성능이 유난히 좋지 못한 점이 의아하며, AC와 ACK가 A보다 높은 Training Corpus Resemblance를 보이는 점도 납득이 어려움
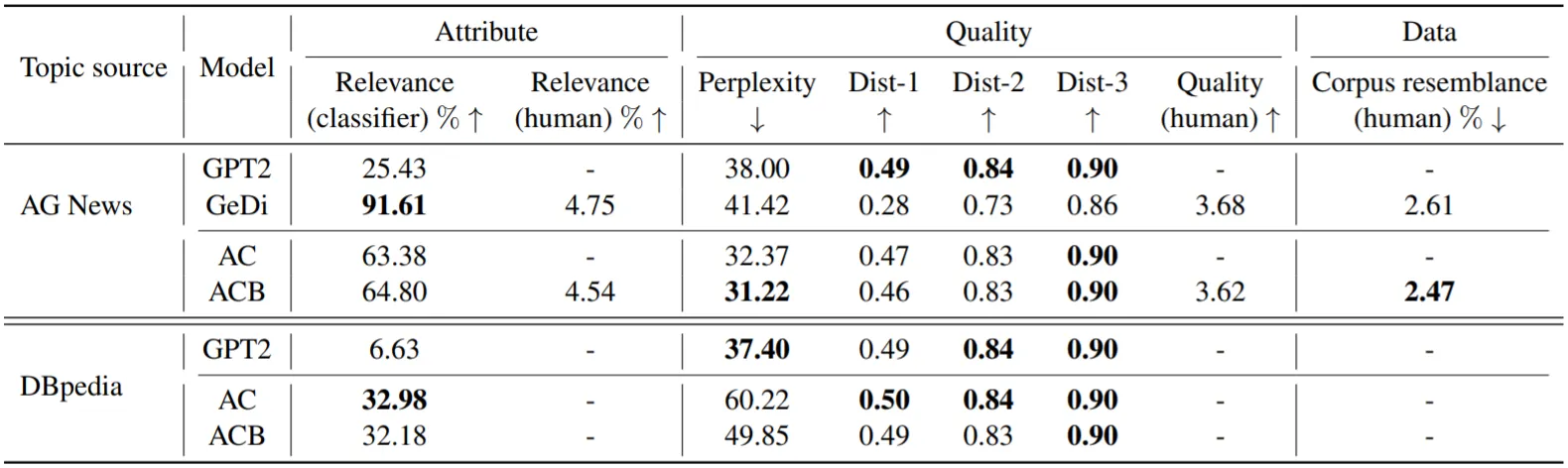
Topic Control 실험 결과,
•
실험이 부실한 느낌이 약간 있지만, DBpedia에서 제안 기법들이 좋은 성능을 보임
•
AG News에서는 GeDi가 매우 큰 차이로 제안 기법들에 비해 높은 Attribute Relevance를 보임
•
그러나 제안 기법들은 여전히 좋은 Linguistic Quality를 증명함