
PEGASUS: Abstractive Summarization을 위한 Pre-Trained LM
이를 활용한 Google Docs의 Auto-Generated Summaries
(정말 개인적이고, 주관적인 생각들)
예전에도 언급하였지만, 본인은 LM의 Pre-Training 방법론에 관한 논문들을 좋아하는 편이 아니다.
18년도부터 이어지고 있는 Transformer의 시대가 고착화되면서 굵직한 연구들이 자주 나오지 않는 것도 있지만, 설령 나온다 하더라도 내일 당장 Pre-Training을 수행할 수도 없는 노릇이기 때문이다.
이는 아마 본인이 항상 GPU 리소스가 부족한 연구실 or 스타트업에서 일한 탓이겠지만, 대기업의 순수 Research 조직이 아닌 이상 대부분 비슷할 것이라고 생각한다.
(일의 목적과 가치를 매우 중요하게 생각하는 본인이 Pre-Training보다 Target Task에 밀접한 Fine-Tuning을 더 좋아하기도 한다..)
)그럼에도 불구하고, 선택하는 PLM (Pre-Training 방법)에 따라 Downstream Tasks에서의 성능이 많이 달라질 수 있기 때문에, 해당 논문들을 기록해두었다가 생각날 때마다 읽곤 한다.
실제로 PEGASUS도 최근 Dialogue State Tracking (DST)을 공부하던 중에 Summarization을 목적으로 Pre-Trained된 LM을 활용하면 더 좋은 성능을 보인다는 Google의 연구에서 처음 접하였다.
이후 Google AI Blog를 보다가 Google Docs의 새로운 기능인 Auto-Summarization에 PEGASUS가 사용되었다는 포스트를 읽고 (간단한) 리뷰를 결심하게 되었다.
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
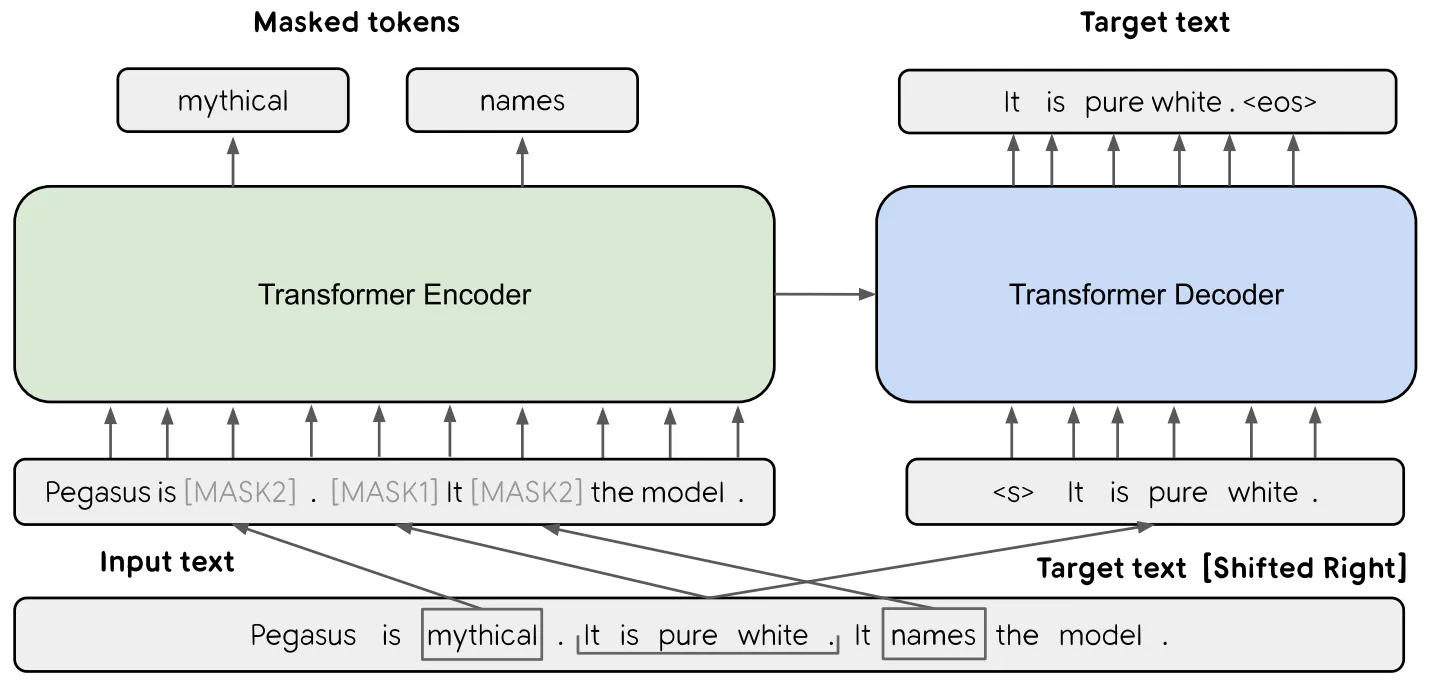
PEGASUS는 Abstractive Summarization 수행을 위한 Transformer Enc-Dec 기반 LM으로 Gap Sentences Generation (GSG) 및 MLM Objective로 Pre-Training 된다.
GSG란 입력 문서의 한 문장 전체를 Masking 한 후, 주변 문장들로부터 해당 문장을 복원하는 Task이다.
Masking 하는 문장의 수 (비율)를 Gap Sentences Ratio (GSR)라고 하며, 일종의 HyperParameter로 조절 가능한 수치이다.
논문은 Masking 하는 문장들을 선택하는 방법으로 다음과 같은 3가지를 제시한다.
•
Random: Random하게 선택
•
Lead: 가장 먼저 나오는 문장들 선택
•
Principal
◦
의미적으로 중요한 문장들을 Heuristic하게 골라내어 선택
◦
기본적인 방법은 입력 문서의 각 문장과 이외의 문장들 간의 ROUGE1-F1 값을 계산하여 가장 높은 값을 갖는 문장들을 선택 (Ind)
◦
이 때, 선택하는 문장들의 집합인 S를 정의하고, S와 이외의 문장들간의 ROUGE1-F1 값을 Maximize 하는 방향으로 문장들을 Greedy하게 선택해 나갈 수도 있음 (Seq)
◦
ROUGE1-F1 값을 계산할 때, n-grams를 고유한 집합으로 취급 (Uniq)하거나 본래 방식 (Orig)으로 처리할 수 있음
◦
결과적으로 Ind/Seq-Orig/Uniq, 총 4가지 옵션이 존재
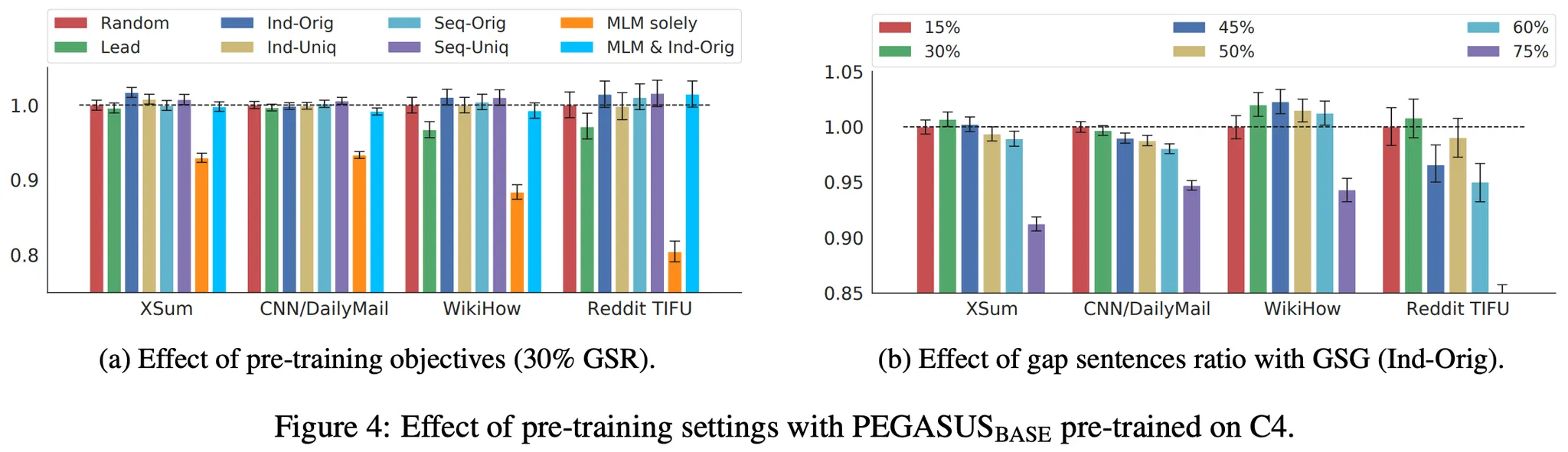
Pre-Training (500k Steps)에 사용한 Corpus는 C4, HugeNews이며 실험 결과는 다음과 같다.
•
GSG-Principal (Ind-Original) 방법으로 Pre-Training 한 결과가 가장 좋음
•
GSG-Principal의 서로 다른 옵션들 간 성능 차이는 크지 않으며, MLM은 Pre-Training Step 수가 커지면 크게 도움이 되지 않음
•
GSR은 50% 이하에서 좋은 성능을 보임 (Optimal 30%)
논문에서 최종적으로 제시한 모델 (PEGASUS-large) Spec은 다음과 같다.
•
GSG-Principal (Ind-Original)
•
GSR 30%
•
Vocab Size 96k
•
Larger Batch Size, 8192 (유독 큰 느낌)
Pre-Training의 효과로 적은 수 (약 1천 개)의 데이터로 Fine-Tuning을 수행하여도 SOTA의 성능을 보인다고 한다.