
NeurIPS 2021 Proceeding을 살펴보다가 발견한, 과거에 리뷰하려다 잊었던 Paper!
(이미 이름부터) MS의 LM Pre-Training에 관한 Research.
최근 회사에서 일을 하다 보니, 논문이 주장하는 ‘1%의 성능 향상’이 서비스 상에서 어떤 의미를 갖는지 잘 모르겠음..
비슷한 맥락에서, 이미 Transformer 구조로 고착된 Pre-Trained LM을 더 공부해야 하나 생각이 잠깐 들었지만, Pre-Training Objective에 따라 특정 Downstream Tasks에서 성능 향상이 클 수 있으니 리뷰하기로 결정함!
(위의 생각은 ML/DL 초보의 건방진 생각임을 알고 있으나, 여전히 AI 기술 자체보다 이를 활용한 기획 내용이 더 중요하다고 생각함)
Abstract
자연어이해 (Natural Language Understanding, NLU) Tasks에서 Masked LM Objective로 학습된 언어 모델의 성능이 좋다는 사실은 자명함.
그러나 BERT와 같이 Input Sequence의 15% 정도를 Masking하는 방법은 사실상 Training Corpus의 15%만을 활용하는 것으로 생각할 수 있음.
위 내용은 ELECTRA 논문의 주장으로, Masked LM의 학습이 Not Efficient한 점을 문제 삼고 있음.
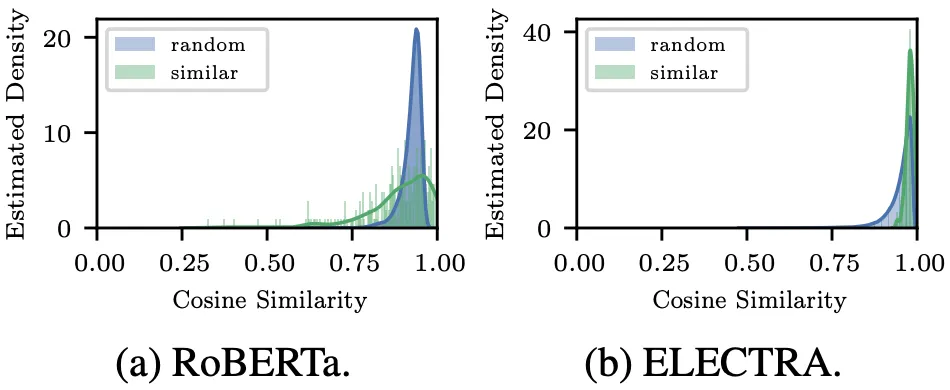
또한, Masked LM의 문장 Embedding은 (Semantic) 내용과 관계 없이, 대부분 비슷한 값을 갖는 문제가 있음.
경험상, BERT를 활용한 Raw한 문장 Embedding은 (빈도수가 높은) 특정 단어에 큰 영향을 받았으며, 이를 해결하기 위해 Sentence BERT나 Contrastive Learning 등을 활용하여야 했음.
ELECTRA는 Replaced Token Detection (RTD)으로 Efficiency를 확보하지만, 대부분의 ‘Not Replaced’ Token들이 동일한 Label을 갖도록 하는 바람에 Language Modeling 성능이 저하됨.
이에 순전한 Token-Level Training Objective로 문장 Embedding 성능 역시 더욱 저하됨. (아래 그림 참조)
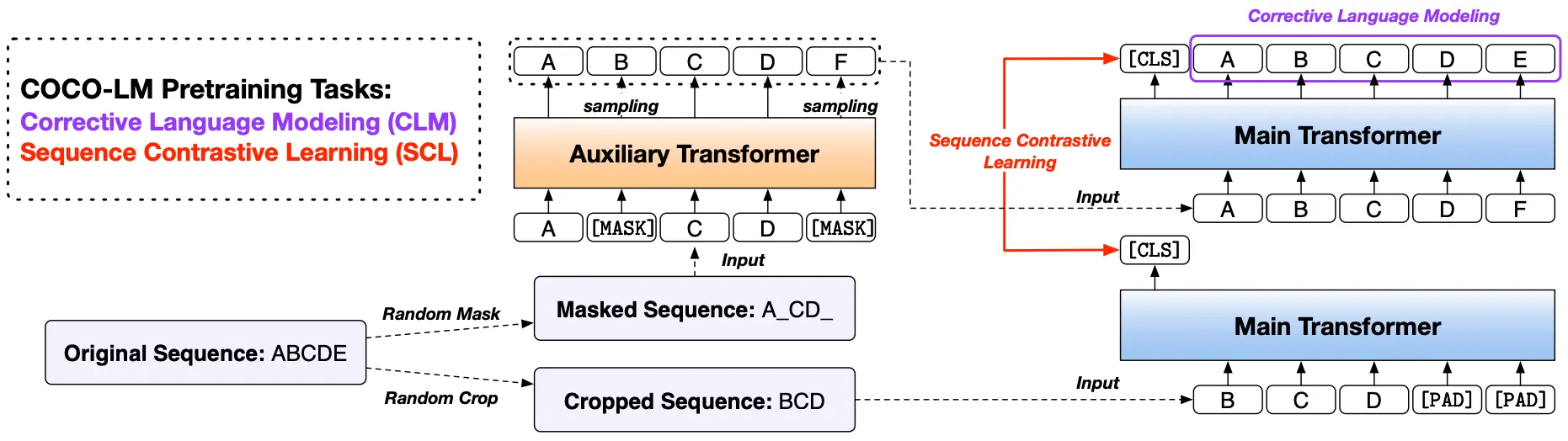
본 논문은 기본적으로 ELECTRA-Style에 Language Modeling과 문장 Embedding 성능을 보완한 Pre-Training 기법을 제안함.
Proposed Pre-Training: COCO-LM
1.
Corrective Language Modeling (CLM)
CLM은 ELECTRA의 변형, All-Token MLM의 개선 버전으로 생각할 수 있음.
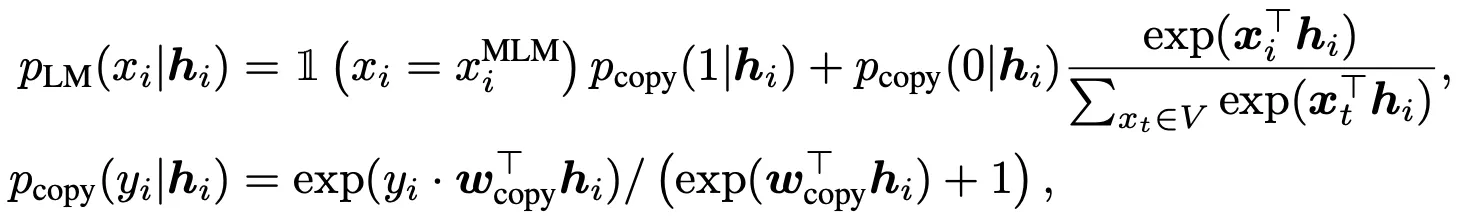
All-Token MLM은 (위 수식 참조)
•
RTD의 Binary Classification을 Copy Mechanism으로 활용 (특정 Token이 Not Replaced, 즉 Original인 경우 그대로 출력)하고,
•
(반대로 특정 Token이 Replaced인 경우, Original Token을 예측하는) 별도의 Language Modeling Layer를 갖는 구조임.
그러나, LM이 위의 두 작업을 동시에 수행하는 것은 너무 어려움.
이에 본 논문은 위 과정을 독립된 2개의 Task로 분리함. (아래 수식 참조)
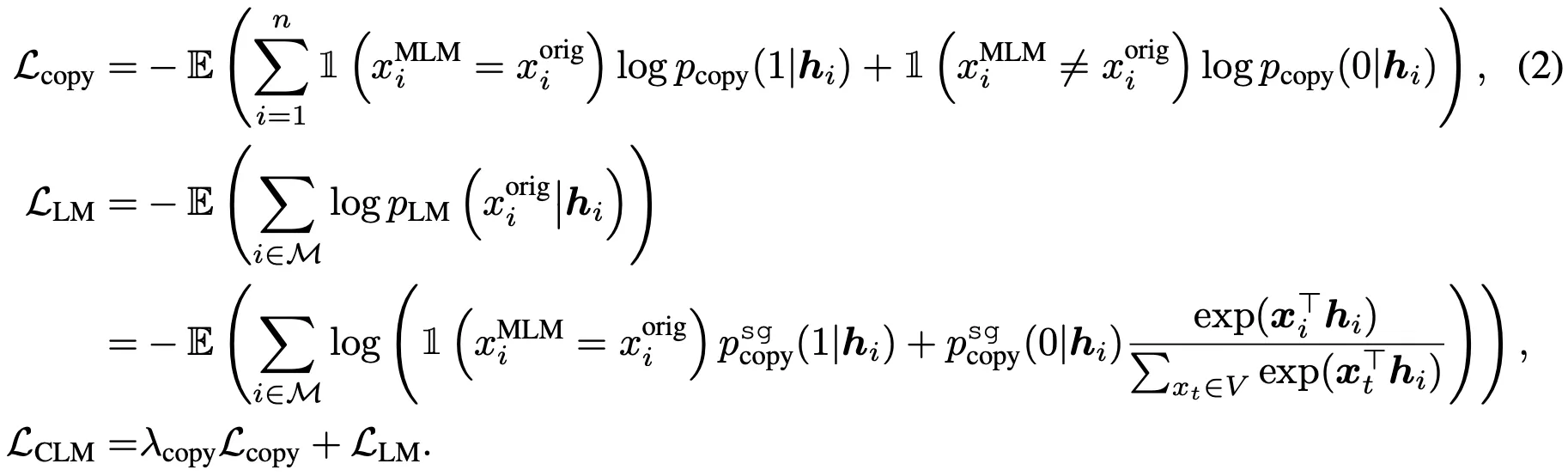
상대적으로 학습이 쉬운 RTD (Copy Mechanism)가 Language Modeling을 돕는 형식임.
제안 방법으로 ELECTRA의 Efficiency, Language Modeling 성능을 모두 확보할 수 있음.
2.
Sequence Contrastive Learning (SCL)
상단의 그림 (학습 과정) 참조.
동일한 Original 문장으로부터 보조 Transformer가 복원한 문장과 Cropping된 문장이 Positive 쌍, 나머지가 Negative 쌍이 되어 Contrastive Learning 수행.
(Computer Vision, Sentence Embedding 분야에서 자주 활용되는 방법론!)
Experiments & Results
제안 모델은 BERT와 동일한 구조에 T5의 Relative Position Encoding 활용.
보조 Transformer는 ELECTRA 논문에서와 달리, 동일한 Hidden Dimension Size에 Layer 수만 축소+Replaced Token Sampling 시에 Dropout 비활성화.
총 3가지 Size에서 GLUE, SQuAD로 성능 측정. (다른 PLM들과 비교)
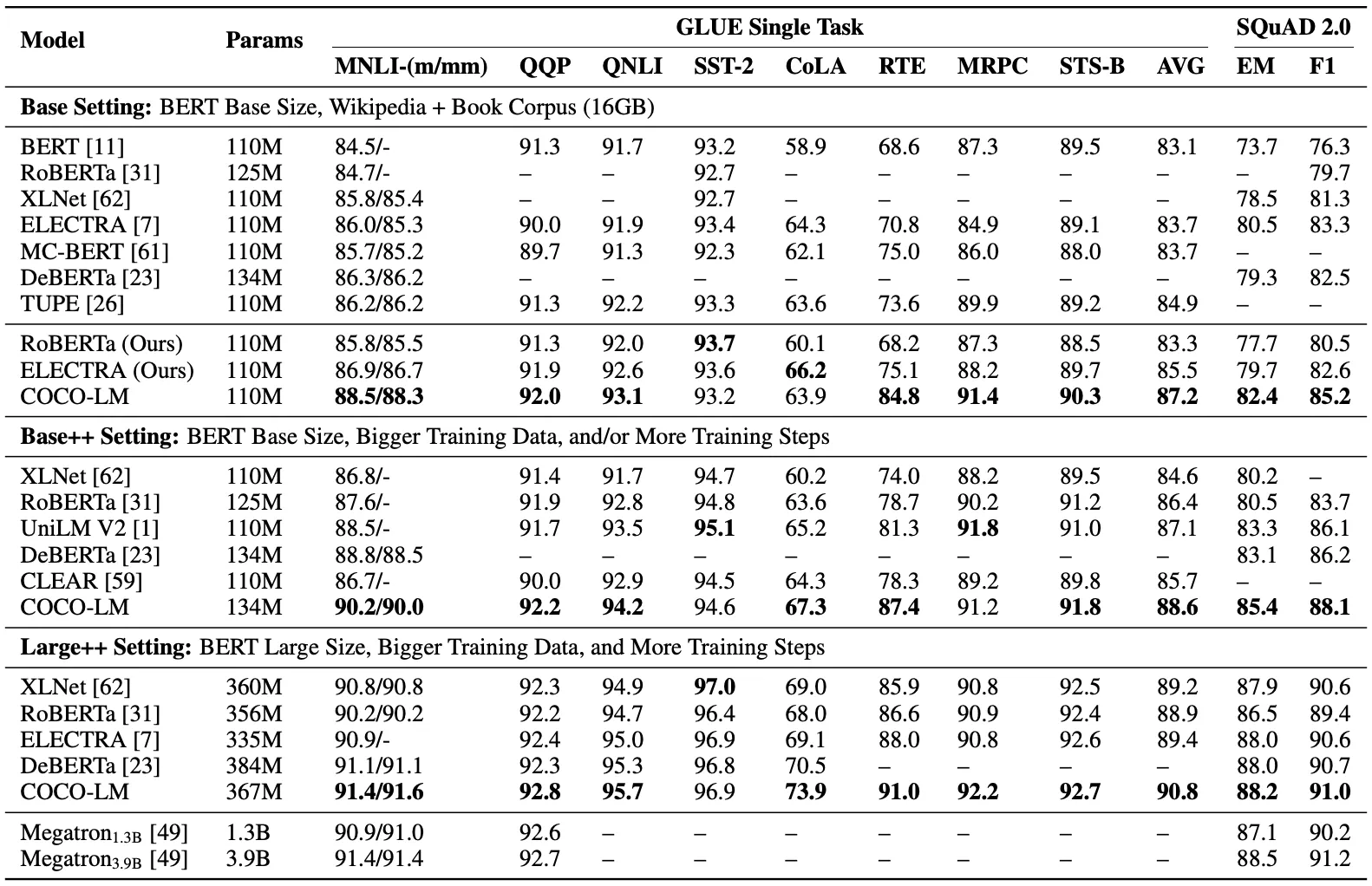
실험 결과, 3가지 Size에서 모두, 제안 모델이 가장 좋은 성능을 보임.
MNLI에서 RoBERTa, ELECTRA의 50~60% 수준의 학습량으로 동일한 성능을 보임.
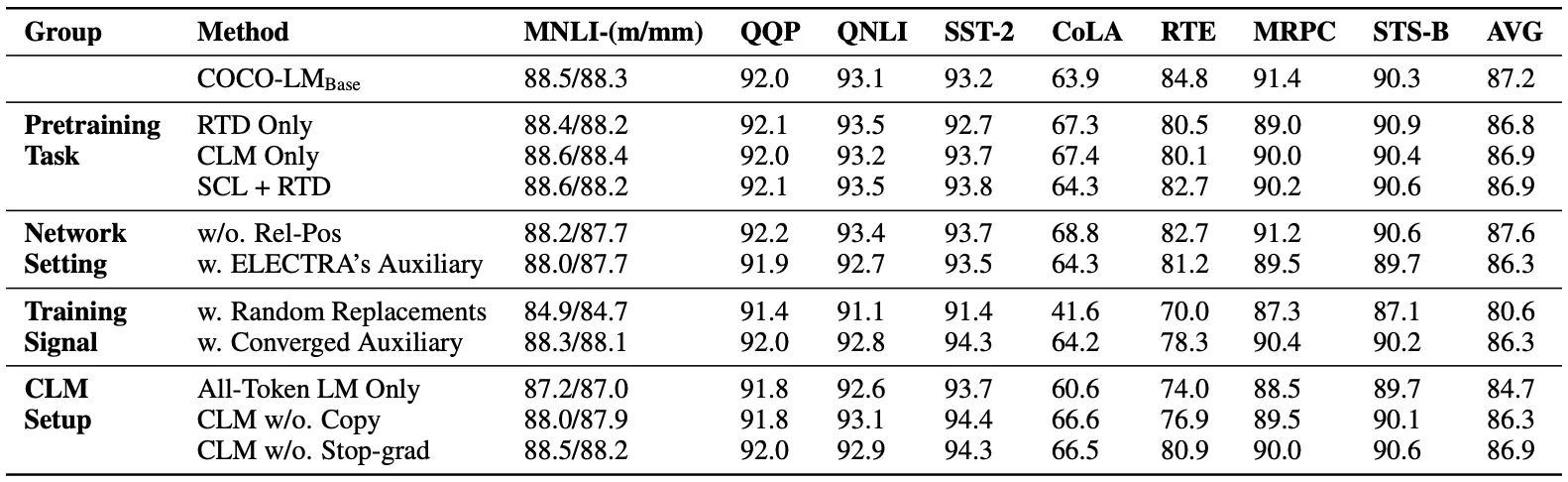
Ablation Study.
생각 외로, 보조 Transformer의 구조가 성능에 큰 영향을 미침.
처음부터 ‘Converged’ 보조 Transformer를 활용하는 것보다, Main Transformer와 함께 학습하는 편이 좋음. (Main Transformer 입장에서 학습 난이도가 너무 높음)
CLM이 All-Token MLM의 상위 호환임을 알 수 있음.