
최근 회사에서 연구 중인 Data-To-Text Generation에 관하여 공부한 & 공부할 내용들.
연구에 자주 사용되는 Datasets & Baselines 정리!
Table, Graph와 같이 구조화 혹은 정제된 데이터로부터 Text를 생성하는 Task를 Data-To-Text Generation이라 명칭함. 그러나 논문들마다 해당 Task를 Table-To-Text, Graph-To-Text 등으로 다르게 언급하여 혼란스런 부분이 존재함.
이를 명확하게 하기 위해 데이터의 형식에 따라 Task의 명칭과 특징을 구분하고자 함.
Graph-To-Text
(Subject, Predicate, Object)로 구성된 Triple RDF 집합으로부터 Text를 생성함.
e.g. (Levels, Artist, Avicii) (Avicii, Country, Sweden)으로부터 Levels는 Sweden 출신 Avicii의 곡이다를 생성
대표적인 특징은 주어진 집합의 RDF 내용을 모두 포함하는 Text를 생성하는 점으로 LM의 고차원적 Inference 능력을 필요로 하지 않음.
•
Datasets
◦
WebNLG
▪
DBPedia 15개 Categories로부터 추출한 Triple 형태의 RDF & Text 쌍으로 구성
▪
Train & Dev & Test Set에 모두 출현하는 10개의 Seen Categories, Test Set에만 출현하는 5개의 Unseen Categories로 구성
◦
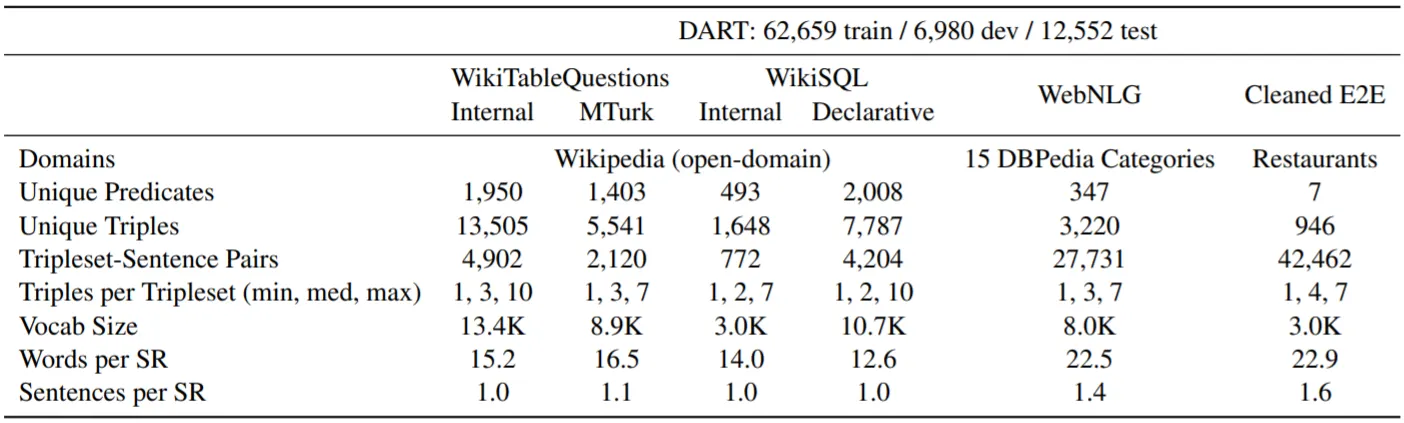
DART
▪
▪
▪
기존 Graph-To-Text Datasets의 크기 (특히, Domain과 술어 격인 Predicate 수)가 작음을 지적하며, 다양한 Datasets으로부터 Triple RDF를 추출하고 이를 통합한 대용량의 Dataset을 구축 (위 그림 참조)
▪
다양한 (Open) Domain을 포함하므로 모델의 Generalization 능력을 Test하기에 적합
▪
WebNLG와 같은 다른 Dataset 실험에서 Augmentation Set으로 활용되기도 함
◦
E2E
•
Baselines
◦
PlanEnc
▪
GCN을 활용한 모델. 그러나 Kale에 의하면 Pre-Trained LM이 GCN-based Models에 비해 좋은 (Generalization) 성능을 보인다고 함
Table-To-Text
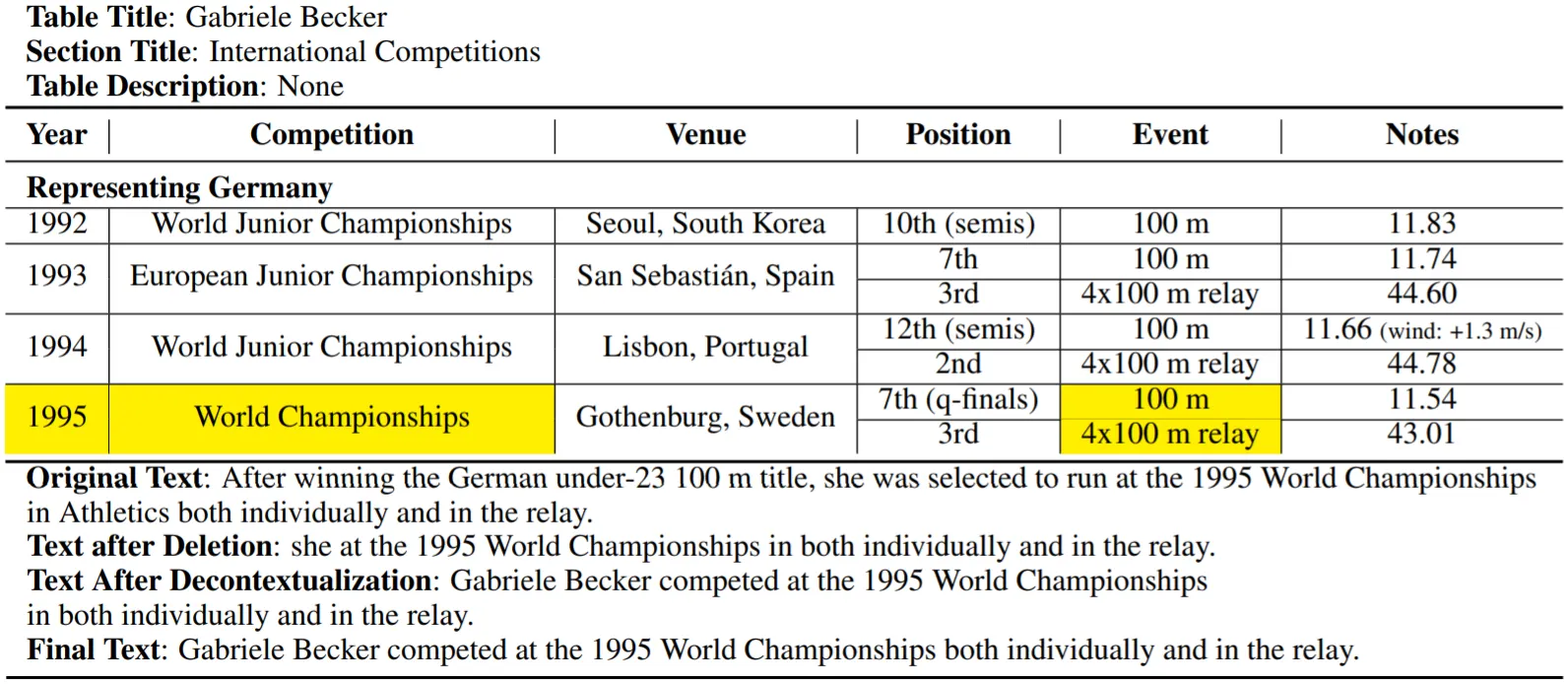
Tabular Data로부터 Text를 생성하는 대표적인 Dataset으로 Google Research의 ToTTo가 있음.
•
Datasets
◦
ToTTo
▪
▪
주어진 데이터의 모든 내용을 포함하는 Text를 생성하는 Graph-To-Text Datasets와 달리, Table에서 강조된 Cells의 내용만을 생성하는 Controlled Generation Dataset
•
(ToTTo를 제외한 범용적인 Dataset은 아직 찾지 못했음.. 이번 EMNLP에서 관련 논문을 찾았는데 조만간 Review할 생각!)
이번 EMNLP에서 관련 논문을 찾았는데 조만간 Review할 생각!)