
지난 달, arXiv에 공개된 Imperial College & DeepMind의 Research.
Prefix-Tuning의 Upgraded Version 느낌..!
현 시점 Data-To-Text Generation 각종 Benchmarks에서 가장 좋은 성능을 기록 중!
Prefix-Tuning
(Imperial College, 2021) Control Prefixes for Text Generation
Abstract
•
GPT-2,3와 같은 Large Scale의 Pre-Trained LM을 Fully Fine-Tuning하기보다, LM은 Freeze하고, 추가적인 Small Parameters만을 학습하는 것이 최신 연구 동향
•
Input Text에 Trainable Propmts를 추가하여 해당 Parameters만을 학습하는 Prompt Learning이 활발히 연구되는 중
•
최근 리뷰한 Prefix-Tuning이 Prompt Learning을 활용하여 Data-To-Text (& Summarization) 성능을 향상시킨 대표적인 Research
•
그러나 Prefix-Tuning은 Task-Specific한 Prefix (Prompt)만을 사용하는데, 본 논문은 이에 단일 Data에 Specific한, Attribute-Level Prefix를 추가로 사용하여 성능을 개선: Finer-Grained Control
•
(저자는 CTRL & PPLM과 같은 Controlled Generation에서 영감을 받았다고 함)
Proposed Model: Control Prefixes
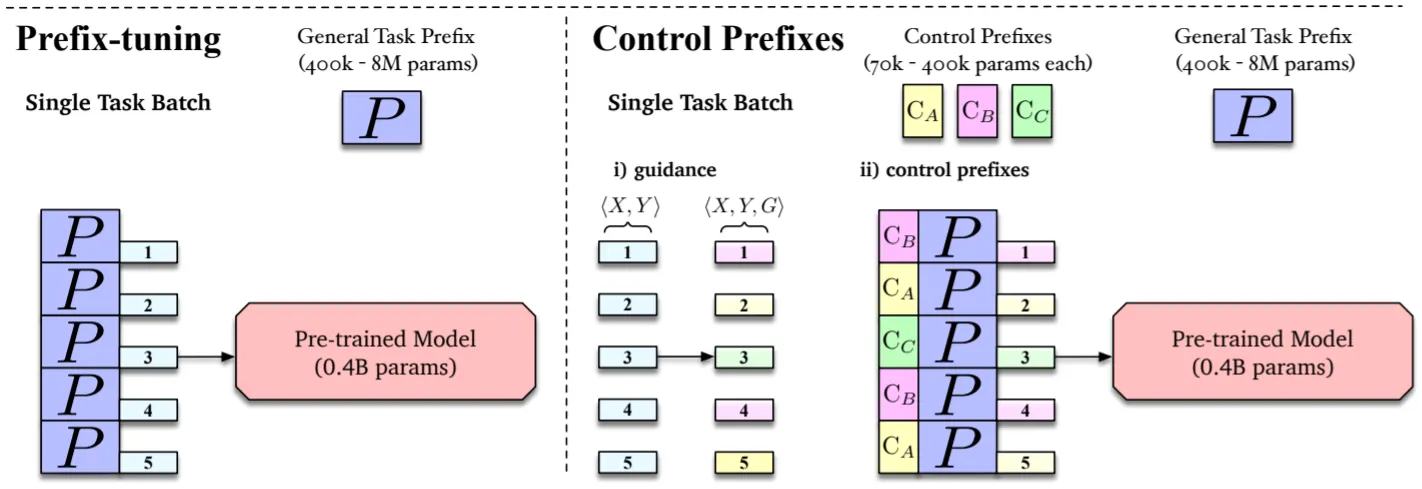
•
Baseline LM은 T5 (for Data-To-Text), BART로 Transformer Enc-Dec 구조
•
(T5가 GPT-2에 비하여 좋은 성능을 보인다고 하며, Data-To-Text Tasks에서 T5가 적합하다는 Google의 Research도 존재함. 해당 Research는 글 마지막에 간략히 소개하겠음)
•
Task-Specific한 (Like Prefix-Tuning) General Prefix, Attribute-Level의 Control Prefixes 그리고 Attribute-Level 정보 혹은 Guidance를 Input Text에 추가
•
Prefix는 Self-Attention의 Key-Value Pairs인데, Enc-Dec 구조로 인하여 3가지 버전 (for Encoder & Cross & Decoder Masked-Attention)이 필요
•
(Prefix-Tuning에서와 같이) 각 Prefix는 Reparameterization을 위해 MLP를 거치는데, 3가지 버전이 존재하므로 MLP도 3개가 필요함. 중요한 점은 2종류의 Prefix가 Shared MLP를 갖는다는 것!
Experiments & Results
실험은 Data-To-Text Part만 확인.
•
WebNLG, DART, E2E 사용
•
원 논문과 다르게 Prefix-Tuning을 T5에 적용
•
WebNLG는 Train & Validation Set에 등장하는 Seen Categories 10개, Test Set에만 등장하는 Unseen Categories 5개로 구성
•
WebNLG Categories (Airport, Food..)가 Attributes로 활용됨
•
Inference에서 Unseen Categories는 Glove Embedding상 가장 유사한 Seen Categories로 Mapping됨
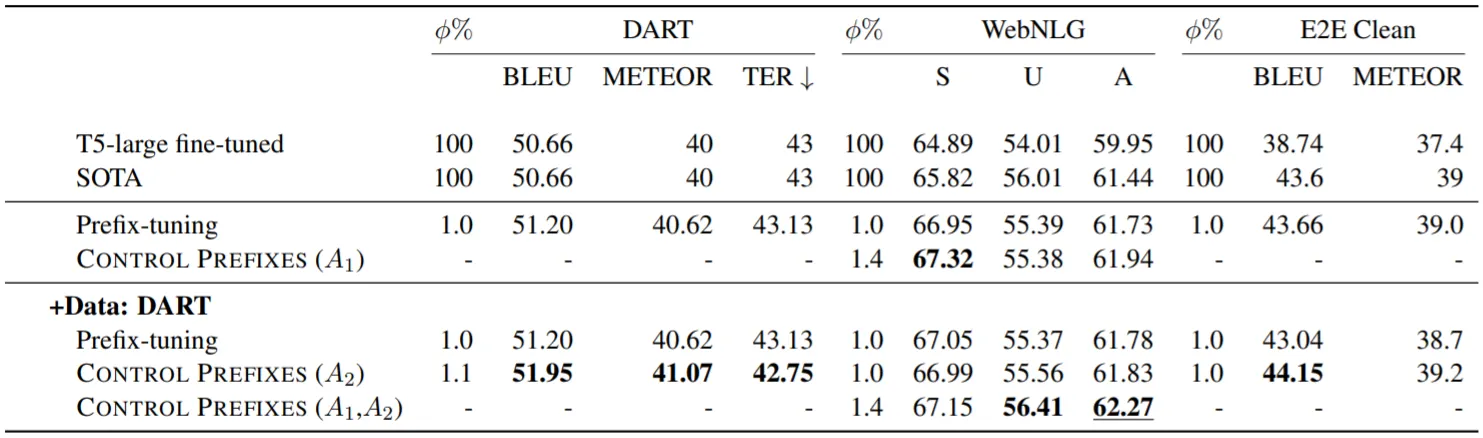
•
실험 결과, 모든 Dataset에서 SOTA의 성능을 보임
•
Prefix-Tuning 논문의 실험을 보면 WebNLG에서 Seen 성능을 일부 포기하는 대신, Unseen (Generalization) 성능을 크게 향상시키는 것을 알 수 있음
•
본 논문은 Attribute-Level Prefix를 추가하여 Prefix-Tuning의 (Unseen 성능은 유지하면서) Seen 성능을 끌어올리는 것으로 이해할 수 있음: Table상 WebNLG 중간 Part
•
DART Data를 추가하는 것은 상대적으로 약한 Unseen 성능을 끌어올려 결과적으로 SOTA의 성능을 이끌어냄
(Google, 2020) Text-to-Text Pre-Training for Data-to-Text Tasks
•
T5 Pre-Training을 통해 BERT, GPT-2 혹은 복잡한 구조의 Models를 능가하는 (Simple End2End) Data-To-Text Generation LM을 구축할 수 있음
•
특히, Out-Of-Domain에서의 Generalization 성능이 좋음
•
단, Unsupervised Objective로만 학습된 버전이 아닌, Supervised Multi-Task 버전의 T5를 활용