
Experts를 활용한 Allen AI의 Decoding-Time Controlled Generation Research.
DAPT/TAPT, DEMix Layers 등 관련 분야의 연구를 다수 수행한 Allen AI의 연구로 많은 기대를 하며 본 Paper..
Abstract
LM의 크기와 학습 Corpus 양이 증가함에 따라 LM의 안전한 서비스 적용 (Deployment)을 위한 Controlled Generation의 중요성이 부각되고 있음.
이에 본 논문은 다음과 같은 특성의 Controlled Generation 기법을 제안함.
•
GeDi와 유사한 Decoding Time Method
◦
원하는 (혹은 원하지 않는) 속성의 Text를 생성하는 작은 크기의 LM, (Anti-)Experts를 활용하여 Base LM의 가중치 업데이트 없이 Generation을 조절할 수 있음
◦
Base LM에 완전한 접근이 필요하지 않음: LM이 출력하는 Logits (혹은 Softmax 값)만을 필요로 하기 때문에 OpenAI API를 통한 GPT-3의 활용도 가능함
•
Anti-Expert만을 활용하여 기존 기법들을 능가하는 성능을 보임
◦
Anti-Expert (Toxic LM)만을 사용하여 Detoxification을 수행할 수 있음: Base LM을 Expert로 활용
◦
Non-Toxic Annotated Data가 필요하지 않음
•
Sentiment Control의 Adversarial Setting에서 효과적임
◦
부정적인 Prompt로부터 긍정적인 Continuation을 생성할 수 있음 (Vice Versa)
Proposed Method: DExperts
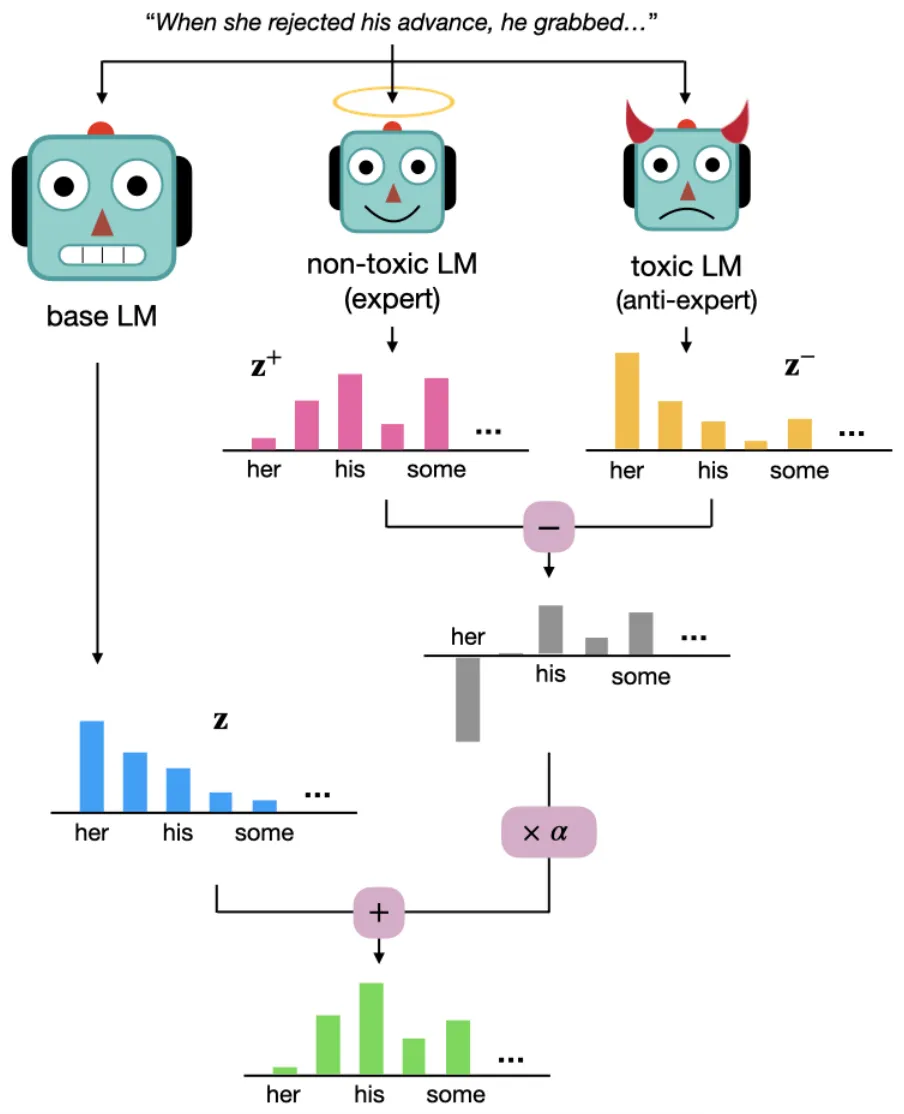
DExperts의 기본 원리는 위와 같이 Base LM의 Output (Next Token) 확률 분포에 Expert와 Anti-Expert의 확률 분포 차이를 더해주는 것!
원하는 속성의 Token 생성 확률은 증가시키고, 그렇지 않은 Token의 생성 확률은 감소시키는 목적.
단, 확률 분포의 수정 (Perturbation) 전, Top-k 혹은 Nucleus Sampling을 수행하여 생성 확률이 높은 Token들만을 대상으로 함.
이후에는 Pure Sampling을 통해 Next Token을 결정.
Experiments & Results
실험은 크게 2종류, Detoxification과 Sentiment Control로 구성됨.
DExperts의 Base LM으로 GPT2-Large, (Anti-)Experts로 GPT2-Small~Large를 활용함.
Detoxification
•
Jigsaw Dataset으로 (Anti-)Experts를 Fine-Tuning
•
RealToxicityPrompts Dataset에서 무작위 추출한 1만개의 Non-Toxic Prompts로부터 Text를 생성한 후, Toxicity를 측정
•
다음과 같은 Baseline Models를 사용
◦
DAPT: OpenWebText의 Non-Toxic Corpus로 Further Pre-Training
◦
PPLM
◦
GeDi
◦
Anti-Only DExperts
◦
Non-Toxic Expert
•
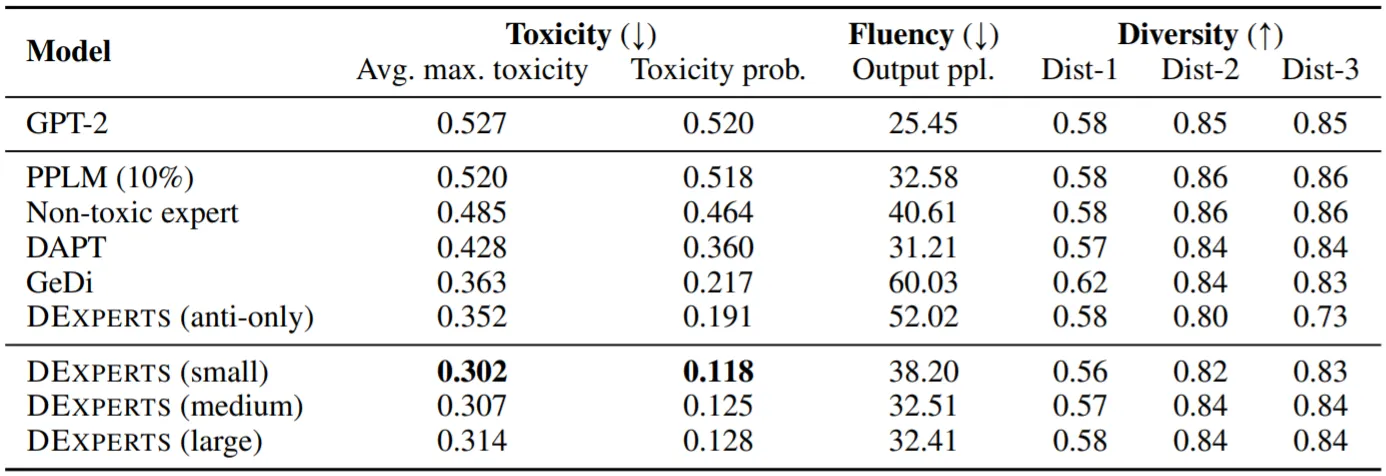
모델의 성능은 Controllability (by Toxicity), Fluency (by PPL of GPT2-XL), Diversity 총 3가지 척도로 측정
•
실험 결과, 제안 기법 (DExperts)이 모든 지표에서 최고 수준의 성능을 보임
•
Anti-Expert만을 사용하는 것으로도 Baseline Models를 능가하는 성능을 보임
•
번외로, Human Eval에서도 제안 기법이 가장 좋은 성능을 보이며, Top-100개 Token의 확률 분포만을 제공하는 GPT-3 API를 (Base LM으로) 활용하여 GPT2-Large보다 나은 결과를 냄
Sentiment Control
•
Movie Reviews를 포함하는 SST Dataset으로 (Anti-)Experts를 Fine-Tuning
•
Domain의 경계를 넘어, 평가는 OpenWebText Dataset의 Prompts로부터 생성한 Text를 바탕으로 수행함
•
기본적으로 중립 (Neutral) Prompts로부터 긍정 혹은 부정적인 Text를 생성하는 것과 달리, Adversarial Setting에서는 부정 Prompts에서 긍정 Text (혹은 그 반대)를 생성해야 함
•
사용하는 Baseline Models는 다음과 같음
◦
DAPT: OpenWebText의 긍정 혹은 부정적인 Corpus로 Further Pre-Training
◦
PPLM
◦
GeDi
◦
Anti-Only DExperts
◦
Positive/Negative Experts
◦
CTRL: Class-Conditional LM (CC-LM)으로, Amazon Reviews로부터 긍/부정 Text 학습
•
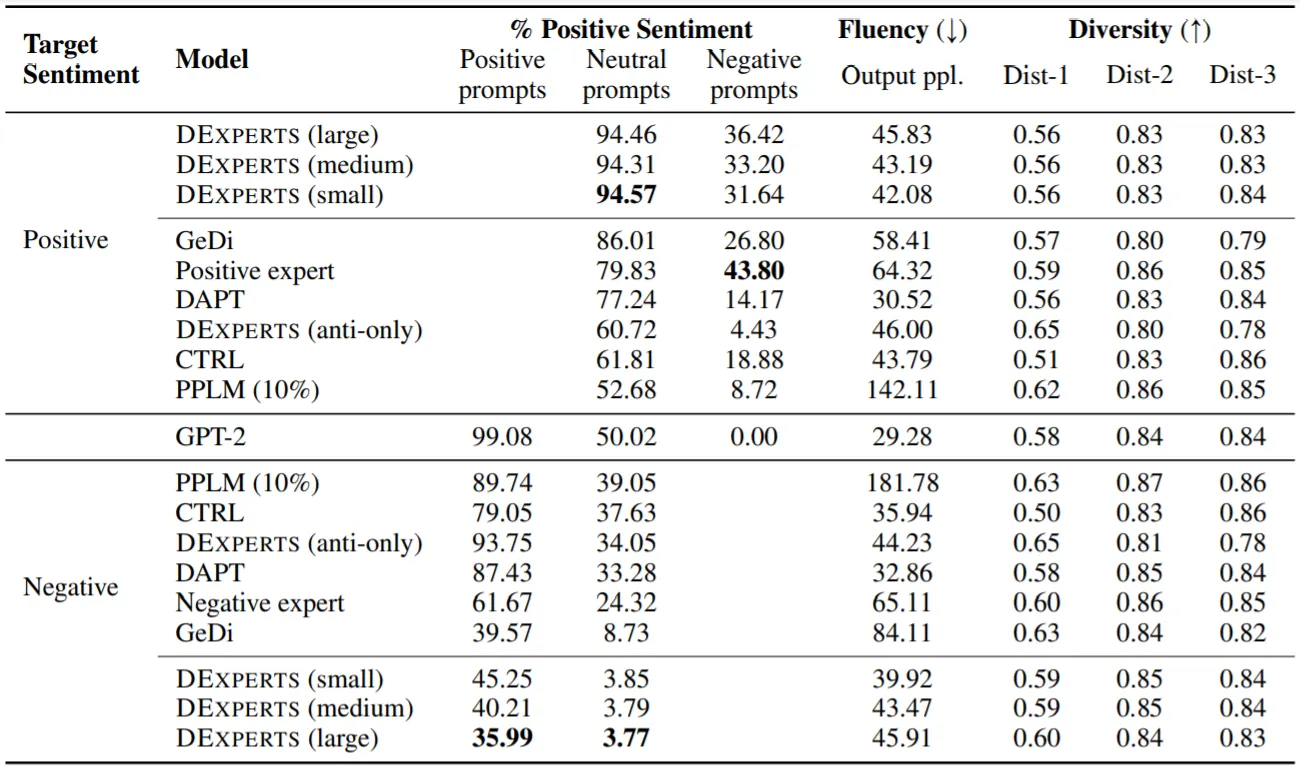
모델의 성능은 Detoxification 실험과 동일하게 측정
•
CTRL은 Out-Of-Domain Data에서 형편없는 Controllability를 보이지만, 좋은 Fluency를 보임
•
Positive/Negative Experts 역시 다른 Domain의 Data로 학습되었으나, 긍정 혹은 부정적인 (단일) Text만을 학습해서인지 좋은 Controllability를 보임. 그러나 Fluency에서 큰 성능 저하를 보임
•
위의 두 결과는 CC-LMs vs. Experts 차이로, (CC-LMs을 사용하는) GeDi와 (Experts를 사용하는) DExperts의 성능 차이 역시 이러한 점에서 발생한 것이 아닐까 추측함
•
DAPT는 In-Domain Data로 학습된 만큼 좋은 Controllability+Fluency를 보이지만, Adversarial Setting에서 매우 좋지 않은 성능을 보임