210829 Review Domain Adaptation

본 논문은 작년 즈음에 흥미롭게 읽었던 DAPT/TAPT 논문 저자의 신작이다. 역시나 Language Model의 Domain Adaptation에 관한 연구이며, Domain별로 Expert를 구축하고 Mixture Model로 활용하는 내용이다.
Domain Adaptation
많은 양의, General Data로 학습된 Language Model(LM)들은 특정 Domain의 Task에서 좋은 성능을 보이지 못한다. 하여, 해당 Domain Data로 LM의 추가적인 학습(Domain Adaptation)을 수행하는데, (논문에서 Dense Training이라고 칭하는) 일반적인 방법은 LM의 모든 Parameter들을 모든 Domain Data에서 Loss를 줄이는 방향으로 Update하는 것이다. 하지만 이러한 방법은 몇 가지 문제를 갖는다.
•
LM의 크기가 커질수록 Computational Cost가 비싸진다.
•
새로운 Domain의 Data로 학습을 수행하면 이전 Domain의 정보를 잊는 등, 다른 Domain에서의 Model Performance가 저하될 수 있다.
논문에서는 이를 해결하기 위해 Domain별로 Specialized Components(Layers)를 갖는 Modular한 LM을 제안한다. Modular LM의 특징으로는 다음과 같은 점들이 있다.
•
새로운 Domain을 학습할 때 Shared Parameter 제외, Specialized Parameter들만 Update되므로 Computationally 효율적이며, 다른 Domain의 Performance에 변화가 생기지 않는다.
•
이렇게 학습한 Domain별 Layer들을 Expert라고 칭한다.
•
Expert는 GPT-3와 같은 Transformer LM의 Feed-Forward Network(FFN) Component를 변환한 것이다.
•
Inference시에는 여러 Expert들을 Mixing하는 등 Customizing이 가능하다.
Multi-Domain Corpus

Training Data와 Inference시에 사용하는 새로운 Domain의 Data: Novel Data를 구성하는 Corpus의 정보를 나타낸 표이다.
학습 과정에서 Training Data로 총 8개의 Expert를 구축하고, 실험에서는 8종류의 In-Domain Data와 8종류의 Out-Of-Domain(Novel) Data로 LM의 (Generalization)성능을 평가한다.
Proposed Model(Expert): DEMIX Layer
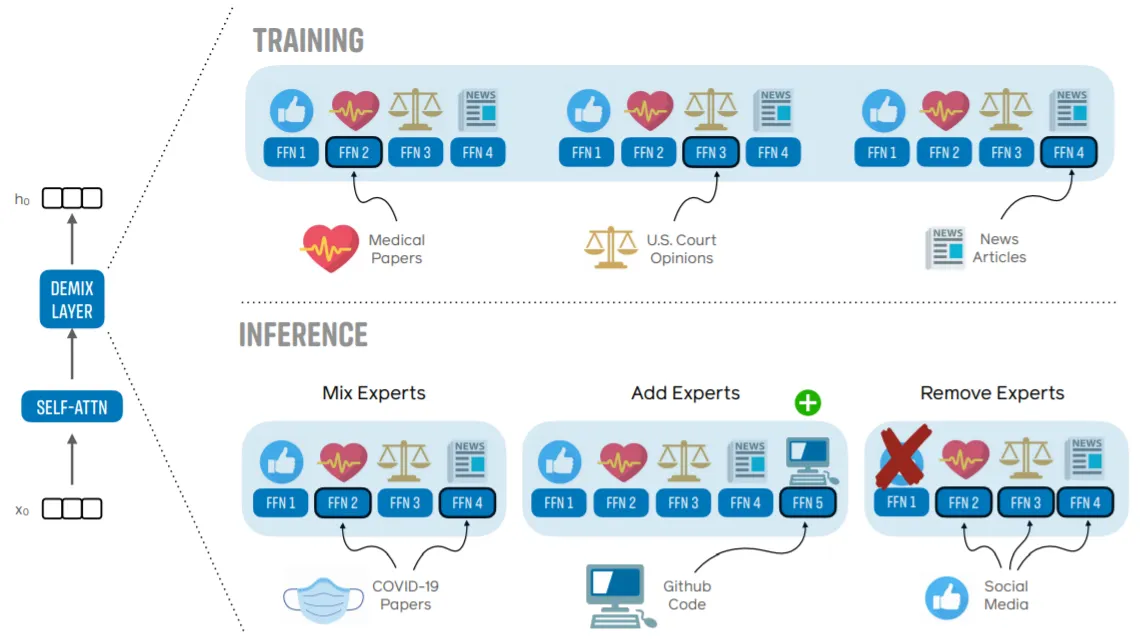
Demix Routing
기존의 Mixture-Of-Experts Transformer에서 FFN Components는 (특정 Domain으로의) Routing Function(g_n)과 Domain별 FFN Layer로 구성된다.
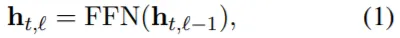
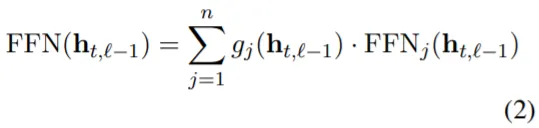
DEMIX Layer는 위 Component와 동일한 형태를 갖지만, Token Level에서 Routing이 이루어지며+Token당 최대 2개의 Domain이 부여되는 기존의 방식과 다르게, 같은 Sequence에 존재하는 Token들에 모두 동일한 하나의 Domain을 부여한다. (Domain별 Metadata 활용).
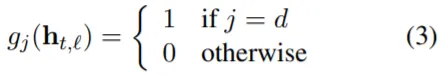
(중요: Sequence 전체에 하나의 Domain을 부여하는 것은 학습 과정에만 적용되며, Inference 과정에서는 여러 Domain 정보를 Mixing하여 사용한다.)
중요: Sequence 전체에 하나의 Domain을 부여하는 것은 학습 과정에만 적용되며, Inference 과정에서는 여러 Domain 정보를 Mixing하여 사용한다.)Demix Architecture
Transformer의 모든 FFN Layer들을 Demix Layer로 교체하며, 성능에 악영향을 주는 Shared Layer는 아예 삭제한다.
Demix Layer의 FFN Layer는 일반적인 Transformer에서와 동일한 차원의 2-Layer MLP이다.
Demix Training
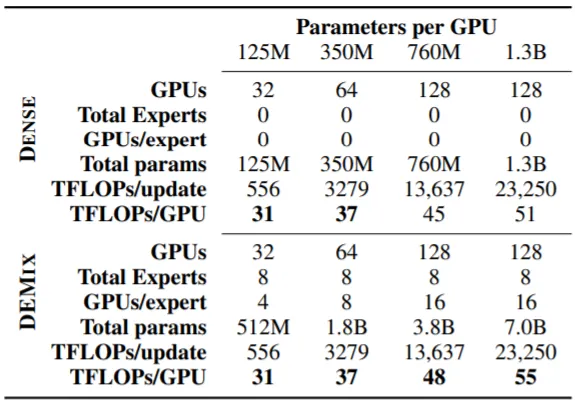
Demix Layer는 LM의 총 Parameter 수를 증가시키지만, 학습 Runtime은 증가하지 않으며, 오히려 Higher Throughput을 갖게 한다.
e.g.) 일반적으로 PyTorch DDP(Multi-GPU)를 사용할 때 동일한 모델을 복사하여 각 GPU에 할당하고, Synchronization을 수행한다. Demix Training에서는 (전체 GPU 수: 32, Expert 수: 8 일 때) Expert를 n(GPU)/n(Expert)=4 만큼 복사하여 이들을 Synchornize한다(⇒Throughput 증가). 이를 위해 Batch도 하나의 Domain으로 구성하며, Larger Batch Size를 적용한다고 한다.
In-Domain Performance
Training Data의 Test Set에서 Perplexity를 측정하며, 실험에 사용한 Baseline LM은 다음과 같다.
•
DENSE: 일반적인 Dense Training으로 학습
•
DENSE (Balanced): Dense Training+Domain별 Data의 수가 동일하게 학습
•
+DOMAIN-TOKEN: DENSE (Balanced)+Sequence 앞에 Domain을 나타내는 Token을 붙여 학습
•
DEMIX (naive): Test Data의 Domain을 아는 경우, 해당 Expert를 사용
•
DEMIX (cached): 추후에 설명할 Experts-Mixing을 In-Domain Data에 적용
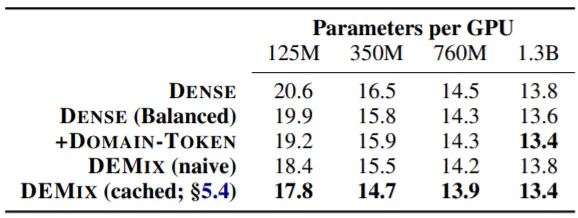
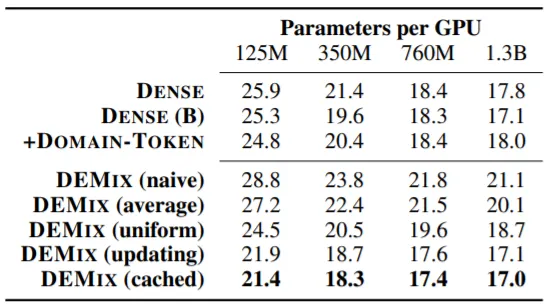
실험 결과를 살펴보면 크기가 ~760M인 LM들에서는 DEMIX (naive)가 DENSE 계열 LM들에 비해 좋은 성능을 보이는 것을 확인할 수 있다. 하지만 1.3B LM에서는 성능이 개선되지 않았는데, 이는 LM의 크기가 커지면 Dense Training을 통해 Domain-Specific한 정보를 충분히 학습할 수 있음을 증명한다.
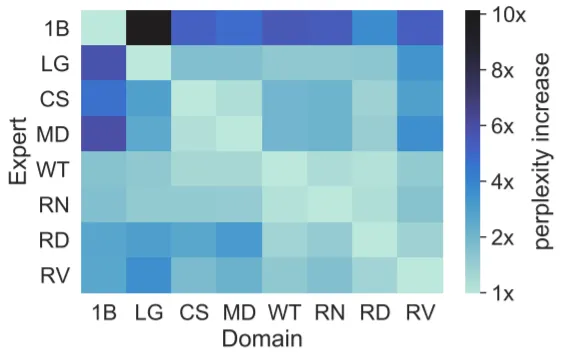
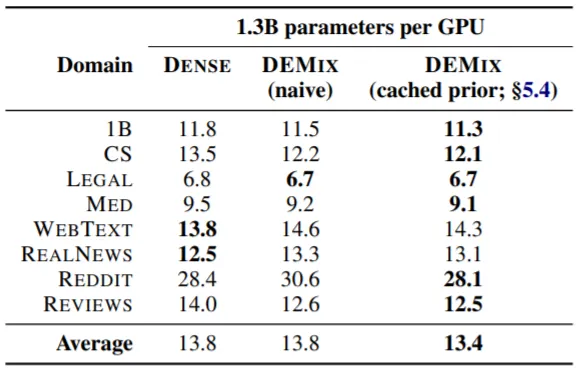
1.3B LM의 8개 Expert를 다른 Domain에 적용했을 때 결과이다. Web Text와 Real News의 경우 다른 Domain Data에서도 PPL이 크게 증가하지 않음을 알 수 있다. 즉, 두 Domain은 다른 Domain과 겹치는 부분이 많다는 뜻으로, Web Text와 Real News에서 (결과적으로 비슷한 Data를 더 많이 학습하게 된 형태의) DENSE가 가장 좋은 성능을 보이는 이유가 설명된다.
Mixing Experts (Novel-Domain Performance)
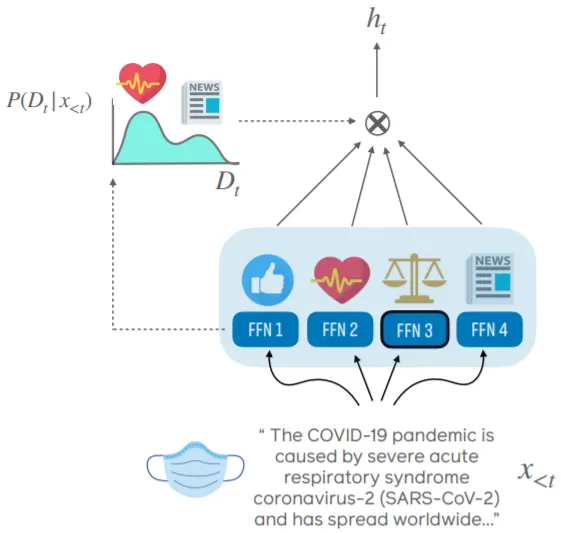
실제 Inference 과정에서는 Input Data가 학습한 Domain들 중 하나에 분명하게 포함되지 않는 경우가 존재한다. 이 때에는 Expert들의 정보를 Mixing하여 Inference를 수행하는데, 이를 위해 Input Data가 기존의 Domain들과 Overlap되는 정도를 계산할 필요가 있다.
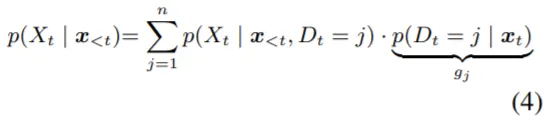
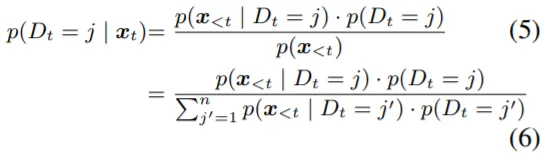
논문에서는 Inference 과정을 식(4)와 같이 표현하는데, P(D_t=j)는 Timestep t에서의 Token이 Domain j에 속할 확률을 의미한다. 식(4)에서 Likelihood는 Expert들로부터 얻을 수 있고, Prior를 계산해야 하는 문제가 남는다. 이는 앞서 언급했던 Routing Function(g_n)을 정의하는 것과 연관이 있다. 논문에서는 Prior를 정의 (Posterior로 변환) 하는 방법으로 총 3가지를 소개한다.
•
Uniform: Domain별로 모두 일정한 값을 가짐
•
Updating: 앞선 Timestep에서의 Posterior값을 반영 (Moving Average)
•
Cached: 미리 일부 Data를 추출하여 Posterior를 구하고, 이를 고정
Novel Data에서 PPL을 측정한 결과, Cached 방식으로 Prior를 정의하여 Mixing할 때 가장 좋은 성능을 보임을 알 수 있다. In-Domain 실험 때와 마찬가지로 Performance Gain이 LM의 크기가 작을 때 두드러지는 것으로 보아, DEMIX Layer 자체가 Small LM에서 의미가 있다고 생각할 수 있겠다.
Adding+Removing Experts
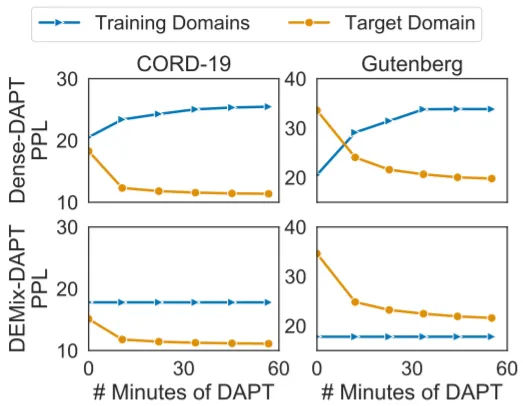
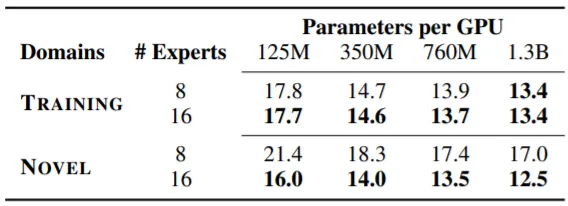
새로운 Domain을 추가로 학습시키는 경우이다. Dense-DAPT란 Dense Training으로 학습된 모델을 추가 Pre-Training(DAPT)시키는 것이고, DEMIX-DAPT는 새로운 Expert를 구축하는 것을 말한다. DEMIX-DAPT시에는 새로운 Expert를 새로운 Domain과 가장 유사한 기존 Domain의 Expert Parameter로 초기화한다. 위 실험 결과를 보면, 두 경우 모두 Target(새로운) Domain의 PPL이 감소하지만, Dense-DAPT는 다른 Domain의 PPL을 증가시킴을 알 수 있다. 반면, DEMIX-DAPT는 다른 Domain의 PPL 변화 없이 Dense-DAPT와 맞먹는 혹은 더 좋은 성능을 보임을 확인할 수 있다. 아래의 표는 Experts-Mixing보다 Expert를 새로 구축하는 편이 더 많은 성능 향상을 이끌어냄을 증명한다.
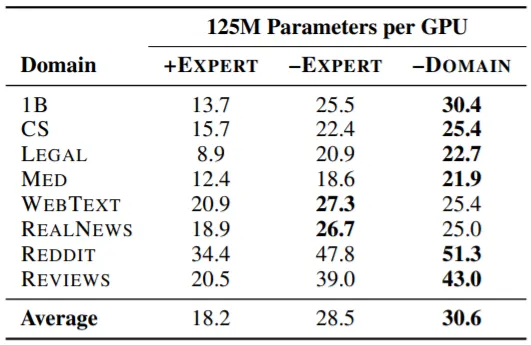
반대로 기존 Domain을 삭제하는 경우이다. +EXPERT는 모든 Expert가 활성화 된 경우, -EXPERT는 해당 Expert를 비활성화 시킨 경우, -DOMAIN은 LM을 해당 Domain Data를 제외하고 From Scratch로 학습시킨 경우이다.