
Data-To-Text가 아닌 순수 Controlled Text Generation Research.
Small Generative LMs을 Discriminator로 활용하여, Large Base LM이 Decoding시에 생성할 Next Token에 관한 Guide를 제공함. (Faster Inference)
CTRL에 이은 Salesforce의 Controlled Generation Paper로 EMNLP 2021에서 공개됨.
(arXiv에는 작년에 업로드+ICLR 2021 Reject인 듯..?)
Abstract
GPT-3와 같은 Large LMs은 대용량의 Corpus로 학습되는데, 이 과정에서 (차별, 혐오 표현 등) Toxic Contents를 함께 학습했을 가능성이 있음. 이에 Toxic한 표현들은 배제하면서, 원하는 속성의 Text만을 생성하는 Controlled Generation 연구들이 많이 수행되고 있음. 대표적으로,
•
CTRL과 같이 Control Codes (Sentiment: Positive | Negative, Topic: Economy | Sports..)를 Input에 Prepend하여 원하는 속성의 Text를 생성하는 (Class-Conditional LMs) 연구. 그러나, LM의 Fine-Tuning을 필요로 하며, 생성하지 않을 속성의 조절이 어려움
•
PPLM과 같이 Decoding시에 Last Layer's Hidden States (혹은 Candidate Tokens)을 Discriminator에 Feed하여 원하는 속성의 Text가 생성되도록 이를 재조정하는 연구. 그러나, Computational Cost가 많이 요구됨 (느린 Inference)
이에 본 논문은 Base (Large) LM은 고정시키고, Small CC-LMs으로부터 Decoding시에 생성할 Tokens의 확률 정보 (Guide)를 제공받는 GeDi 방법론을 제안함.
Proposed Method: GeDi
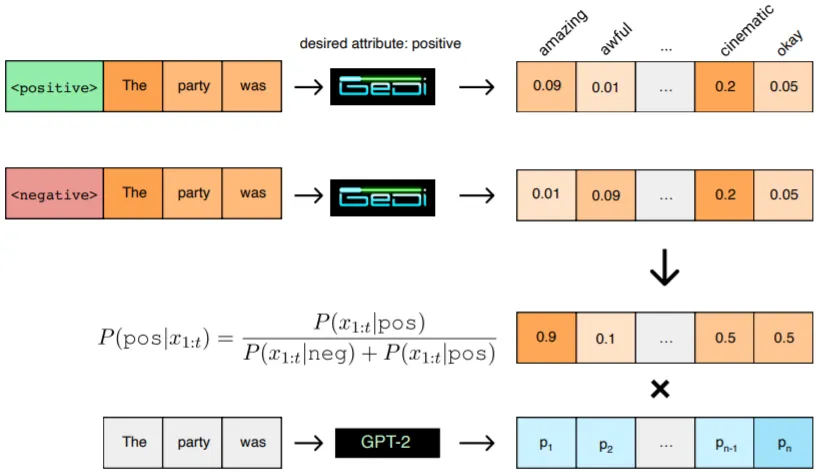
GeDi-Guided Contrastive Generation
•
GeDi의 핵심 아이디어는 그림과 같이 Desired Control Code, c와 Anti-Control Code, ~c를 갖는 상반된 CC-LMs으로부터 Candidate Tokens의 Classification Likelihood를 계산하여, 이를 Base LM의 (Next Token) 확률 분포에 반영하는 것
•
P(c | sequence s, next token t)=P(c)*P(t | s, c) / P(c)*P(t | s, c)+P(~c)*P(t | s, ~c)
(ML/DL 입문 시에 통상적으로 배우는 Discriminative (분류) vs Generative (생성) 모델 간 차이를 떠올리게 하는 내용..!)
•
Key Point는 Discriminator의 역할로 CC-LMs을 차용한 점. GPT와 같은 Generative LM은 과거 Time Step의 Hidden States를 Past Key-Values로 저장할 뿐 아니라, Unidirectional Self-Attention을 사용하기 때문에 새로운 Token이 추가되어도 BERT와 같은 Bidirectional LM에 비해 작은 Computational Cost를 요구함
•
Weighted Decoding: CC-LMs으로부터 구한 Classification Likelihood는 Base LM의 Vocab Token별 확률 분포에 곱해지는데 본 논문에서 제시한 Heuristic이 Optimal하다는 보장은 없으며, Base LM과 CC-LMs의 Vocab만 동일하다면 다른 어떤 Heuristic도 적용할 수 있음
•
Filtering Heuristics: P(c | sequence s, next token t)에 Nucleus Sampling을 적용하여, 원하는 속성에 들어맞을 확률이 높은 Candidate Tokens t 집합을 추림
GeDi Training
•
Base LM에 Generation Guide를 제공하는 CC-LMs의 학습 방법론
•
CC-LMs은 Casual LM Loss+Discriminator로서의 역할을 수행하도록 Discriminative Loss를 추가하여 학습됨
•
Discriminative Loss는 Offline Version의 P(c | sequence s, next token t)에 Negative Log-Likelihood를 취한 형태임
•
Loss(GeDi)=lambda*Loss(Casual LM)+(1-lambda)*Loss(Discriminative)
Experiments & Results
실험은 Bookcorpus의 Prompts로부터 Positive Text를 생성하는 방식으로, Positivity (Controllability)와 Book Resemblance (Linguistic Quality)를 측정함 (Human Eval).
Base LM은 GPT2-XL, CC-LMs은 GPT2-Medium 활용. CC-LMs은 IMDB Reviews로 Fine-Tuning.
CC-LMs은 Generative Training (lambda=1), GeDi Training (lambda<1)의 2버전이 존재. Generation 기법으로는 LMs으로부터 Directly Generation, GeDi-Guided Generation 2가지가 존재.
결과적으로 실험에 사용한 모델은 다음과 같은 13종류.
•
CC-LMs 2버전 X Generation 기법 2가지 X Positive/Negative, 총 8종류
•
CTRL, PPLM 각 Positive/Negative, 총 4종류
•
(Base) GPT2-XL
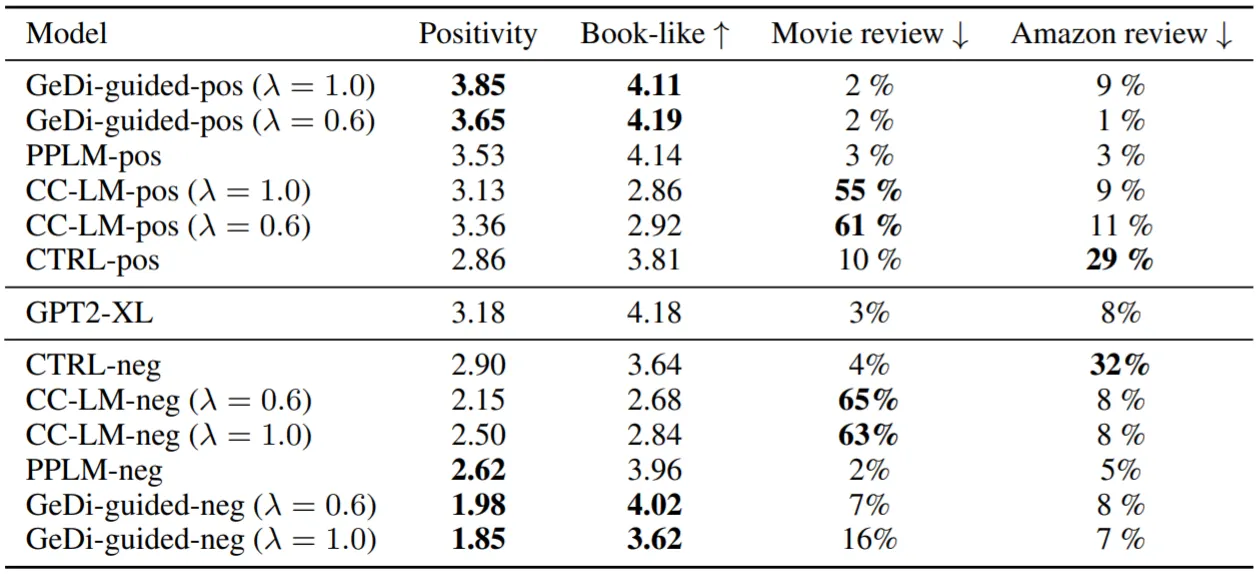
실험 결과,
•
GeDi-Guided Generation의 성능이 가장 좋음
•
개인적으로 GeDi Training 버전의 CC-LMs이 Generative Training 버전에 비해 높은 Controllability, 낮은 Linguistic Quality를 보이지 않을까 예상하였으나, 반대의 결과를 보임
•
CC-LMs (Training Set)과 Task의 Domain이 일치하지 않아도 자연스러운 Text를 생성함 (Domain Transfer)
•
또한, PPLM에 비해 30배 빠른 Inference가 가능함
•
(논문에서는 GeDi를 활용한 Multi-Class Topic Control을 보이는데, 현재 회사에서 연구하는 내용과 유사하여 추후에 개인적으로 분석할 예정!)