
EMNLP 2021에서 공개한 MS의 Controlled Table-To-Text Generation Dataset & Approach.
ToTTo의 Highlighted Cells와 달리 Written Text (Prefix)로 Content Plan을 제시하는 Natural (Practical)한 Dataset!
그리고 Table-Aware Attention과 Copy Mechanism을 활용하여 Faithful한 Text를 생성하는 Novel Approach를 제안함.
Abstract
기존의 NLG System은 Content Planning과 Surface Realization으로 구성되었으나, 최근 DL-based의 방법론들은 End-To-End로 Generation을 수행함.
특히, Pre-Trained LM 기반의 방법론들은 Data-To-Text에서 경쟁력 있는 성능을 증명함.
그러나, Gold Text가 데이터의 모든 내용을 포괄하는 WebNLG (Graphical) Dataset과 달리 데이터의 일부 내용만을 포함하는 ToTTo (Tabular) Dataset에서는 Unreliable한 결과 (Text)를 보임.
이는 "어떤 내용을, 어떤 순서로" 생성할지 결정하는 Content Planning의 부재로 인한 결과로, Controlled Text Generation 영역에서 해당 문제를 해결할 수 있음!
ToTTo는 대표적인 Controlled Text Generation Dataset으로, 주어진 Table의 특정 Cells를 Highlight함으로써 Content Plan (생성할 문장 내용)을 제시함.
저자는 ToTTo의 방식이 실용적이지 못한 점을 지적하며, Written Text (Prefix)를 통해 Content Plan을 제시하는 Natural (Practical) Dataset, TWT (Table with Written Text)를 제안함.
또한, Table-Aware Attention과 Copy Mechanism을 활용하여 Content Plan으로부터 Faithful Text를 생성하는 Novel Approach를 제안함.
TWT Dataset
TWT는 ToTTo와 TabFact Dataset의 (Metadata, Table, Target Sentence)를 추출하여 합친 구성임.
단, Target Sentence를 Prefix (Written Text)와 Gold (Generated) Text로 분리하는 과정을 거침.

Target Sentence에는
•
Aligned Facts: Table 혹은 Metedata와 Target Sentence에서 동시에 출현하는 단어 집합 혹은 절 (#1, #2의 Generated Text)
•
Inferred Numbers: Table과 Metadata에 존재하지 않지만 추론을 통해 얻을 수 있는 숫자들 (#3의 4 years, #4의 second)
가 존재하는데, 이들이 Prefix와 Gold Text를 분리하는 기점이 됨.
Proposed Method (Model)
TWT Dataset에서 Faithful한 (Content Plan의 내용에 부합하는) Text를 생성하는 방법론 (모델)을 함께 제안함.
모델은 Transformer Enc-Dec 구조의 Pre-Trained LM을 Base로 사용함.
Linearized Metadata+Table을 Enc Input, Prefix를 Dec Input으로 하여 Generation 수행.
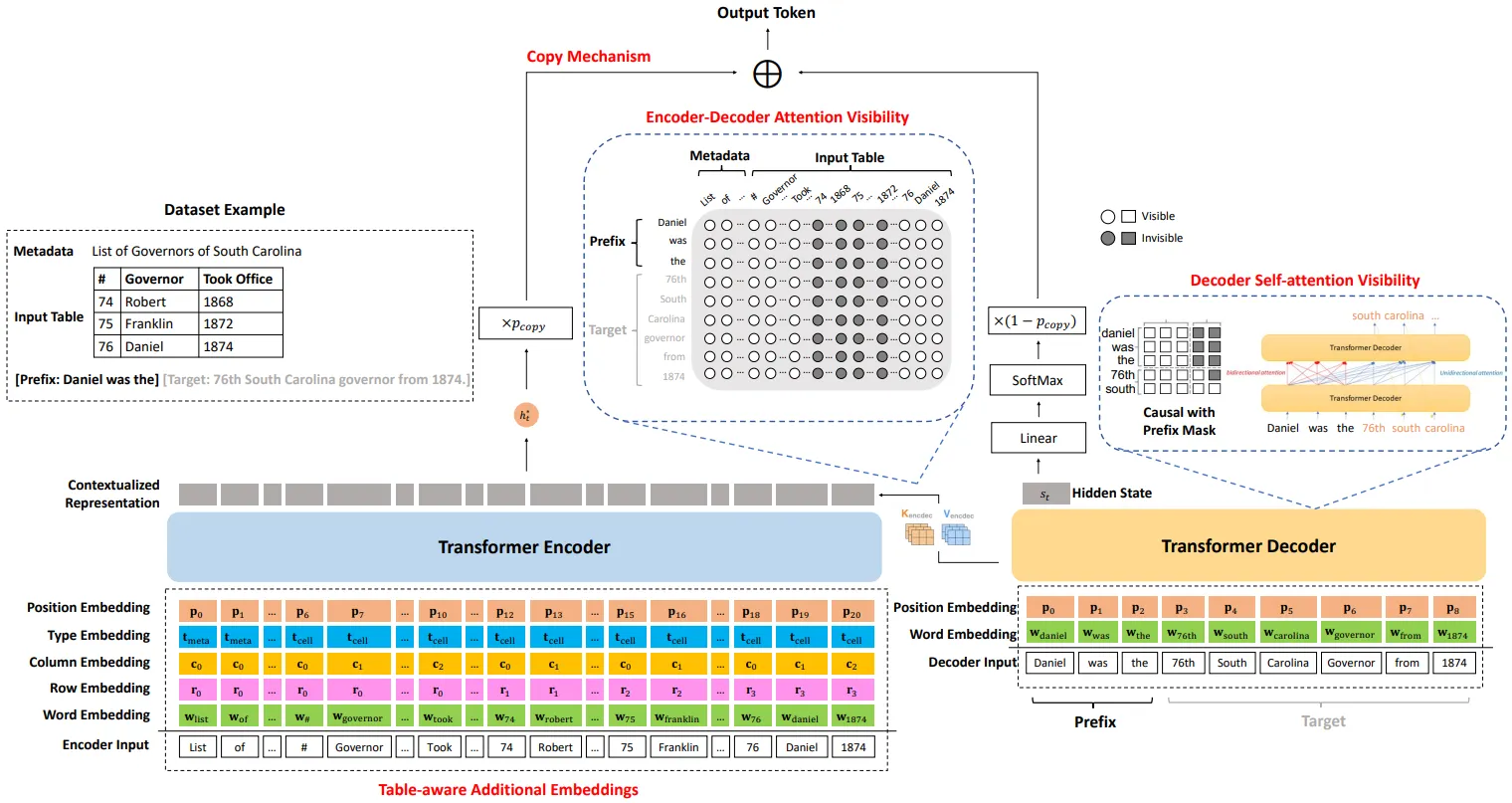
모델은 다음과 같은 4가지 기법을 적용하여 Text를 생성함.
1.
Table-Aware Additional Embeddings
a.
기존 Word+Positional Embedding에 Row & Column & Type Embedding을 추가한 Input을 Enc에 Feed
b.
Tabular Data를 다루는 Transformers에서 일반적으로 사용하는 기법
2.
Enc-Dec Attention Visibility
a.
Prefix에서 Aligned Facts를 추출한 후, 해당 Row+Column만을 Enc-Dec Attention Mask에서 Visible 처리
b.
TWT 예시 그림의 #2, Daniel was가 Prefix로 주어지면 Daniel이 포함된 Row만을 참조
3.
Dec Self-Attention Visibility
a.
T5 Paper의 Prefix LM과 같이 Dec의 Prefix 부분에 Bi-Directional Attention 적용
4.
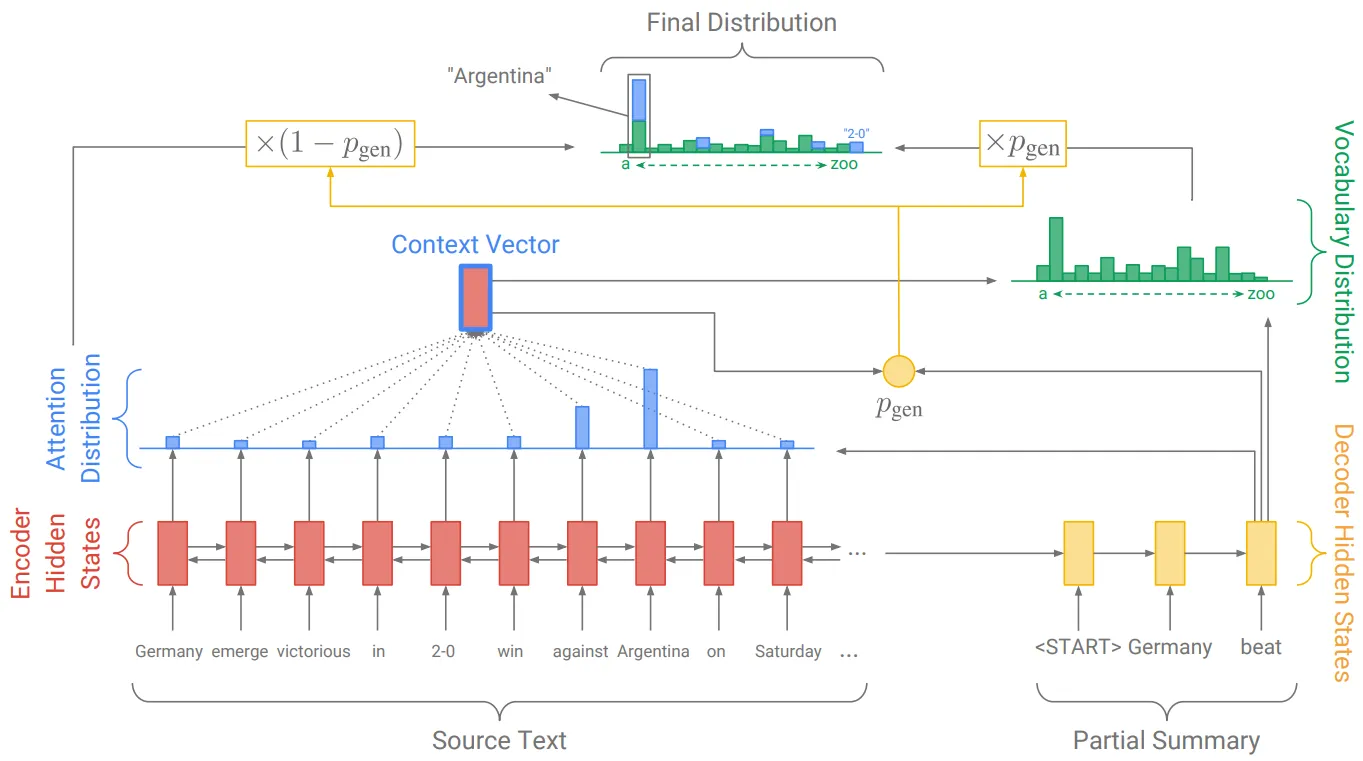
Copy Mechanism
a.
Decoding Step에서 Last Hidden State의 단어 (Vocab) 확률 분포가 아닌, Input Text (Table)에 등장하는 단어들에서 Next Word를 선택 (Copy)하는 방식
b.
i.
Decoder의 Input & Last Hidden State & Context Vector로부터 Copy확률 (p_copy) 계산
ii.
Attention Distribution을 Input Text의 단어들이 갖는 확률 분포로 생각하여, 최종 단어들 (Vocab+Input Words)의 확률 분포 도출
c.
Copy Mechanism은 본래 OOV 문제를 처리하기 위해 사용하지만, 본 모델은 Generated Text의 Faithfulness를 향상시키기 위해 사용
d.
모델은 Casual LM Loss를 낮추고, Gold Text의 Aligned Facts에 해당하는 단어들의 Copy확률을 높이는 방향으로 학습
Experiments & Results
실험은 TWT Dataset으로 수행하며, 다음과 같은 Models를 사용함.
•
BERT2BERT
•
T5
•
Proposed Model (BERT2BERT, T5)
사용하는 Evaluation Metric은 다음과 같음.
•
(Formal) BLEU, BLEURT, BERTScore
•
(Faithfulness) Fact Coverage, PARENT
•
(Writing Suggestion: 유저가 사용할 시에 도움이 되는 척도) EM@N, Chars Saved
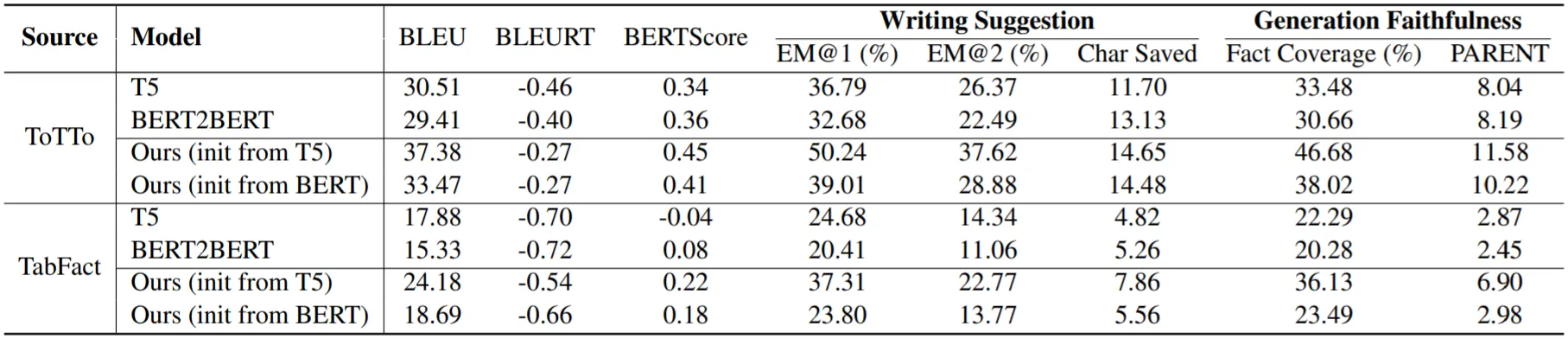
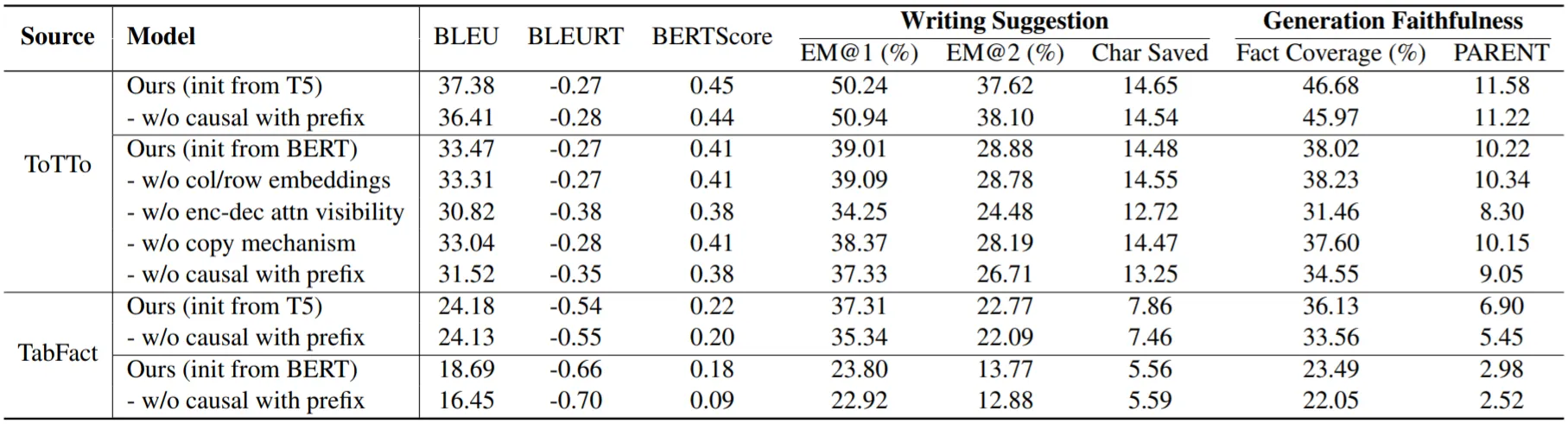
실험 결과,
•
모든 Metric에서 제안 모델 (on T5)이 가장 좋은 성능을 보임
•
특히, Faithfulness 향상이 도드라짐
•
Ablation Study를 통해 Enc-Dec, Dec Self-Attention의 수정이 성능 향상을 이끌어냄을 알 수 있음
•
반면, 다른 모델들도 많이 사용하는 Table-Aware Embedding의 효과는 미미한 수준임
•
OOV 문제가 거의 없는 TWT Dataset의 특성상 Copy Mechanism의 효과 역시 크지 않음
•
Case Study를 통해 제안 모델이 Inference가 필요한 Generation에 약점이 있음을 보임