
최근 Meta에서 공개한 BlenderBot 3와 DL/NLP에 관한 나의 생각 및 고민들..
슬럼프
요새 몇 주 동안이나 회사에서, 혹은 개인 공부에서 펜이 손에 잘 잡히지 않았다.
학회마다 논문들이 쏟아져 나오고, 모델의 크기는 계속해서 커지는데 과연 이것들이 유의미한 가치를 실현하고 있는지 확신할 수 없었다.
어쩌면 내가 소규모의 스타트업, 제대로 운영되는 서비스(프로덕트)가 부재한 환경에서 일을 하기에 고민하고 있는지도 모른다.
하지만, 적어도 새로운 서비스를 기획하는 단계에서 핵심 가치(Core Value, 개인적인+비전문적인 용어)를 정의할 때에 DL/NLP 모델들은 크게 중요한 고려 대상이 아니었다. (오히려, DL/NLP 모델을 염두에 두었을 때, 좋지 못한 결과를 얻었다.)
나는 일을 하는 데에 있어 “왜”가 중요한 사람이고, 실재 가치(고객)에 밀접한 일을 하며 살아가고 싶다.
BlenderBot 3: A 175B parameter, publicly available chatbot that improves its skills and safety over time
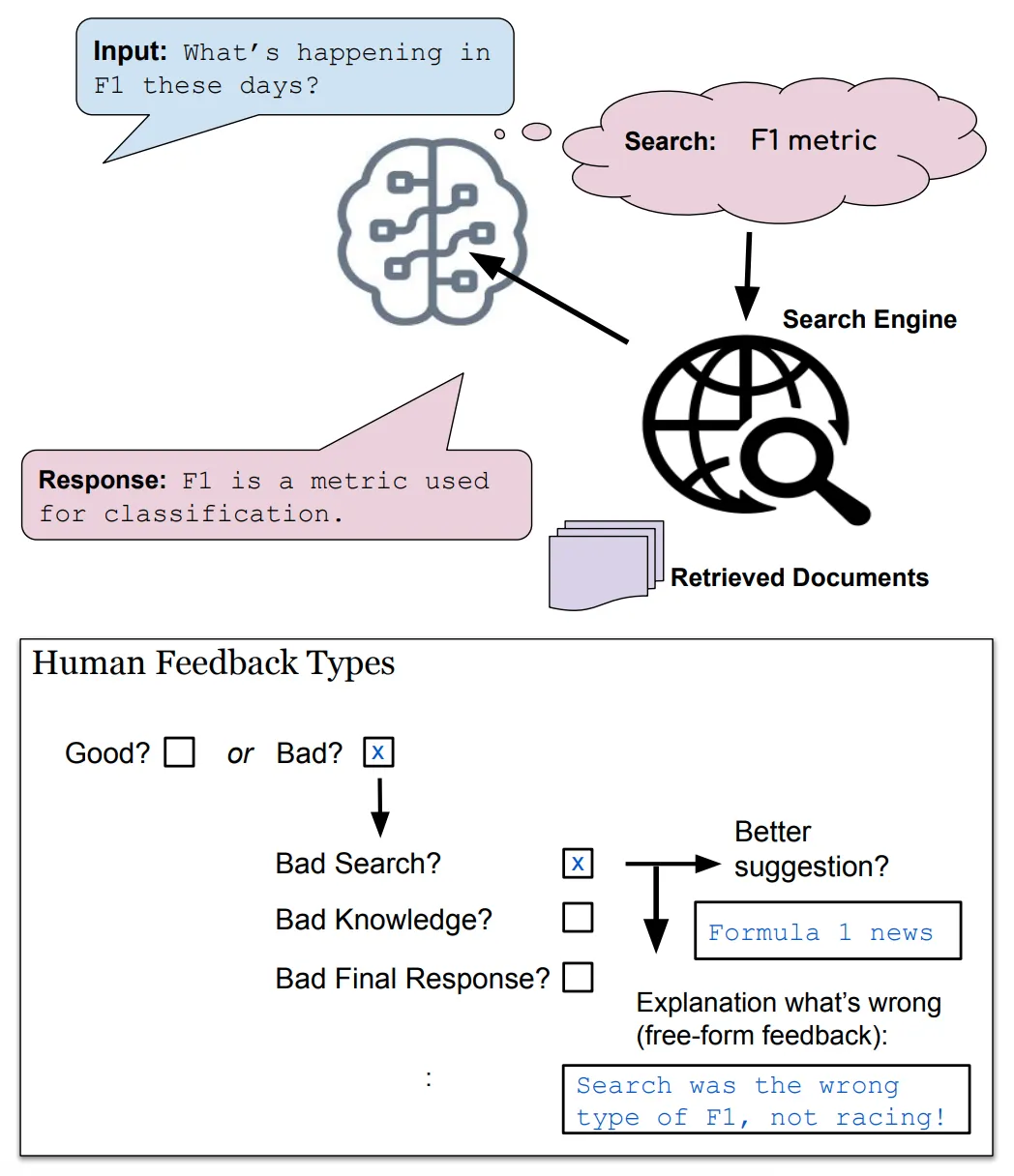
BlenderBot 3는 다음과 같은 3개의 중요한 특징을 갖는다.
•
둘째, 배포(Deployment) 이후 사용자들의 피드백을 학습하여 성능 및 안정성을 개선한다
◦
사용자들에게 받은 (Binary, Free-Form Text 등) 다양한 형태의 피드백을 학습하여, 기존의 Skill 성능을 개선하고+새로운 Skill을 학습한다 (위 그림 참고)
◦
Skill이란 공감, 지식 전달 등 모델이 사용자에게 제공할 수 있는 일종의 기능을 의미하며, 본래 BlenderBot의 이름이 “다양한 기능을 수행하는” Chatbot이라는 점에서 유래하였다
◦
BlenderBot 3는 “건강한 음식 만드는 법 제공”, “특정 도시에서 아이들이 놀만한 곳 추천” 등 1,100여개 세부적인 Skill을 학습하였다
◦
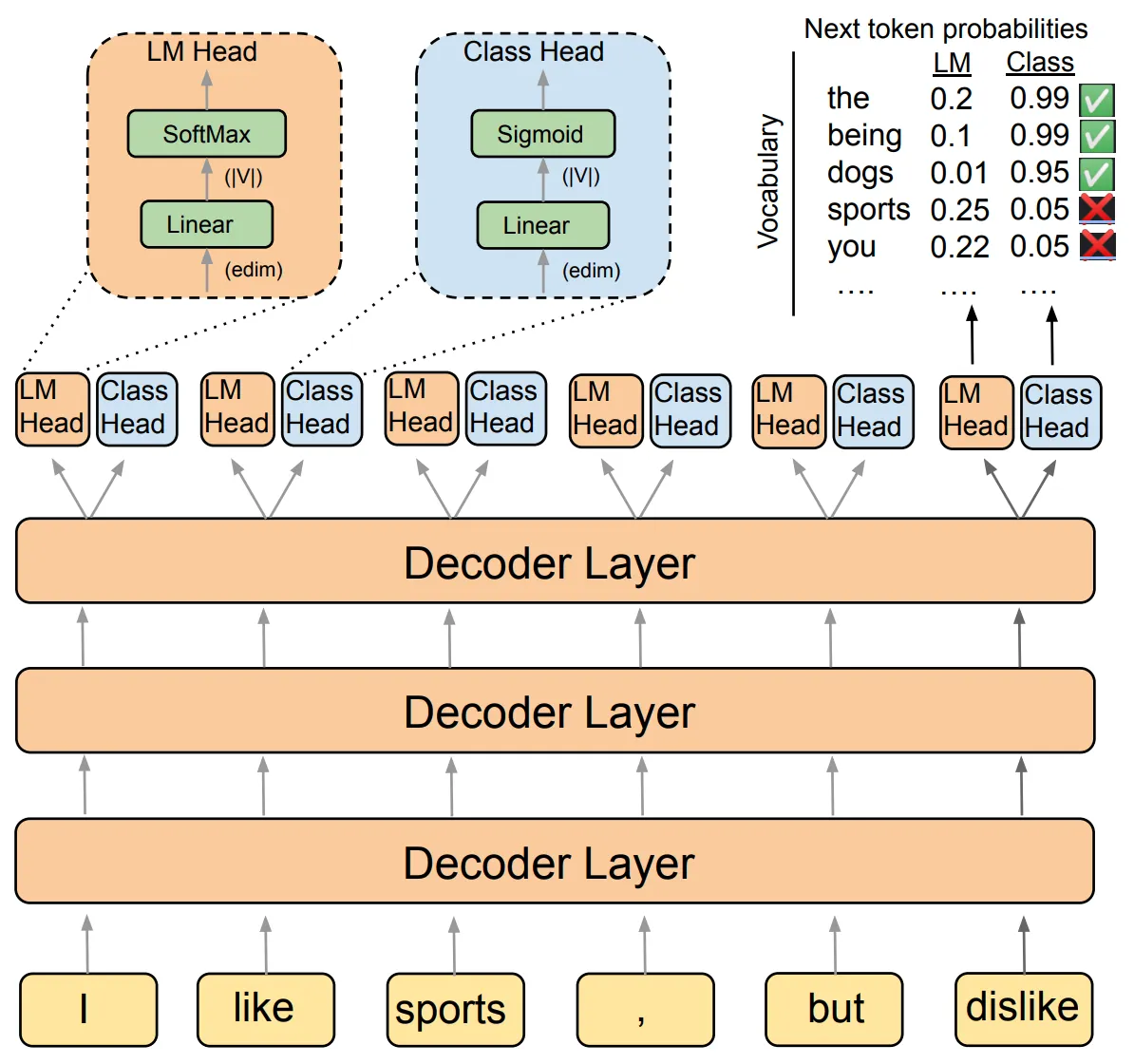
Director, 일반적인 Language Modeling과 더불어 Generated Token (혹은 문장)의 Toxicity Classification을 동시에 수행하는 알고리즘,을 활용하여 안정성을 개선한다 (아래 그림 참고)
•
셋째, 데모 시스템에서 사용자들로부터 얻은 피드백 데이터를 모두 공개한다 (공개할 예정이다)
◦
진화하는 대화형 AI 연구의 발전을 위해 데모 시스템에서 얻은 데이터를 모두 공개한다
◦
데모 역시 “우리가 이런 걸 했으니 봐라”의 목적이 아닌, 모두가 사용할 수 있는 데이터의 확보 (궁극적으로 AI의 발전)를 위해 운영한다
내가 BlenderBot 3 블로그 포스팅을 읽고 안도감을 느낀 이유는
•
Meta AI에서 연구하는 똑똑한 사람들도 DL/NLP 모델들의 실제 활용 방안에 대하여 고민하고,
•
모델, 데이터를 모두 공유하는 등 연구가 “단순 연구”로 끝나는 것이 아닌, 유의미한 가치를 만드는 데에 사용되기를 진심으로 바라는 모습에 공감하였기 때문이다
당분간 슬럼프, 연구/개발자로서의 정체성 고민은 계속되겠지만, 희망을 갖고 열심히 공부해야겠다!