210918 Diary GPT
나는 학부에서 CS를 전공하고, Data Mining 연구실에서 DL-based NLP를 연구한 주제에 코딩을 썩 좋아하는 편이 아니다. 최근, OpenAI에서 GPT를 GitHub Code들로 Fine-Tuning 하여, Code를 자동 완성해주는 Copilot을 공개하였다. Demo 영상을 보면 나름 복잡한 Logic의 Code들도 곧잘 구현하는 모습을 확인할 수 있는데, 조만간 나의 Code도 대신 작성해주는 모델이 나올까 정말 조금 기대하는 중이다. 나와 비슷한 기대를 하는 절친한 친구와 함께 Copilot에 사용된 모델에 관한 Paper를 간략하게 살펴보았다.
나와 비슷한 기대를 하는 절친한 친구와 함께 Copilot에 사용된 모델에 관한 Paper를 간략하게 살펴보았다.
나와 비슷한 기대를 하는 절친한 친구와 함께 Copilot에 사용된 모델에 관한 Paper를 간략하게 살펴보았다.(OpenAI, 2021) Evaluating Large Language Models Trained on Code
논문의 Contributions는 다음과 같이 크게 2가지로 정리할 수 있다.
•
GPT를 GitHub Code들로 Fine-Tuning한, Docstring으로부터 Python Code를 자동 완성하는 Codex를 제안하고,
•
모델이 작성한 Code가 잘 동작하는지 판단하는 Unit Tests(Programming Problem)를 포함한 HumanEval, 새로운 Evaluation Set을 공개한다.
HumanEval에서 기존의 GPT와 GPT-J가 각각 0%, 11.4%의 문제들만을 해결한 반면, Codex-S는 37.7%의 정답률을 보이고, 문제마다 100개의 Sample Code를 생성하면 77.5%의 문제들에서 적어도 1개 이상의 정답 Code를 포함한다고 한다.
Evaluation: Functional Correctness
Docstring에서 Python Code를 생성하는 과정은 일종의 Translation Task로 생각할 수 있지만, BLEU Score를 Evaluation Metric으로 사용하는 것은 실제 작동이 중요한 Code의 특성상 올바른 접근법이 아니다. 본 논문에서는 작성된 Code가 기능적으로 잘 동작하는지 판단하는 HumanEval, Hand-Written Evaluation Set과 pass@k Metric을 제안한다. pass@k는 하나의 문제에 k개의 Sample Code를 생성하고, 이 중 하나라도 정답이 존재하면 문제를 해결한 것으로 간주하는 방식이다. 이 수치가 Unbiased된 값을 갖도록, 저자는 다음과 같은 계산 방식을 제시한다.
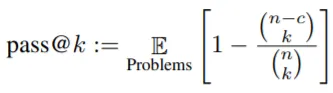
n은 k보다 큰 수이며, c는 정답 Sample의 개수이다. 해석하면, k가 5일 때(pass@5), 30개(n=30)의 Sample을 생성하고, 이들 중에 10개(c=10)의 정답이 존재한다고 가정하자. 이 경우, 30개 Sample에서 5개를 고르는 경우 중 정답이 아닌 20개의 Sample에서만 5개를 고르는(오답만을 선택하는) 확률을 1에서 빼준 값이 pass@5가 되는 것이다.
Proposed Model: Codex
모델 자체에는 특별한 점들이 있는 것 같지 않다. Pre-Trained GPT로부터 Fine-Tuning을 수행하는 것이 From Scratch로 수행하는 경우에 비해 성능상 이점이 없는데, 이는 Fine-Tuning Dataset의 크기가 방대하기 때문이라고 한다. 그럼에도 전자의 경우가 학습의 수렴이 더 빠르기 때문에 해당 접근법을 사용하였고, Code 특성상 잦은 공백의 출현을 처리하기 위해 추가 Token들을 활용하였음을 저자는 언급한다.
Experiments & Results
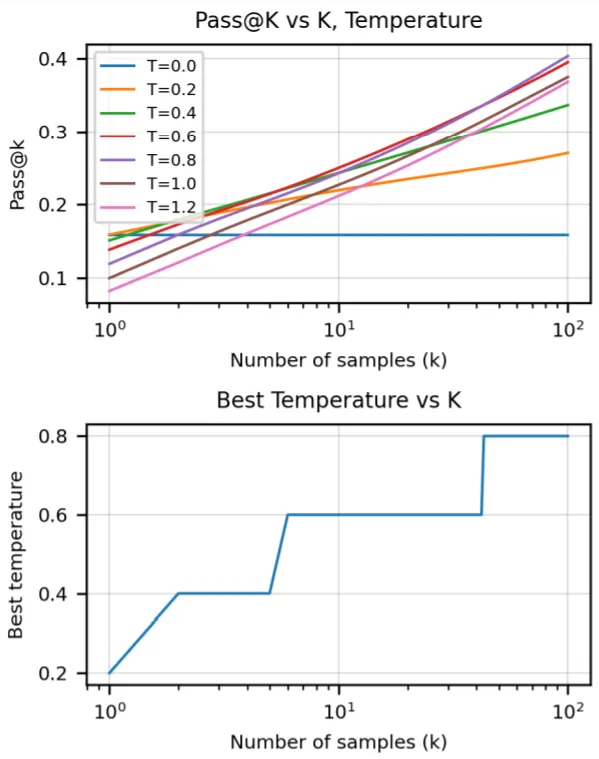
실험은 Sample Code의 수(k), Generation시 Sampling Temperature, Model Size 등을 변경하며 수행된다. 동일한 모델의 경우, 더 많은 수의 Sample Code를 생성할수록 정답률이 높아지는데, k가 증가할수록 생성되는 Sample의 Higher Diversity를 보장할 수 있는 큰 값의 Temperature를 설정하는 편이 유리하다(아래 표 참조).
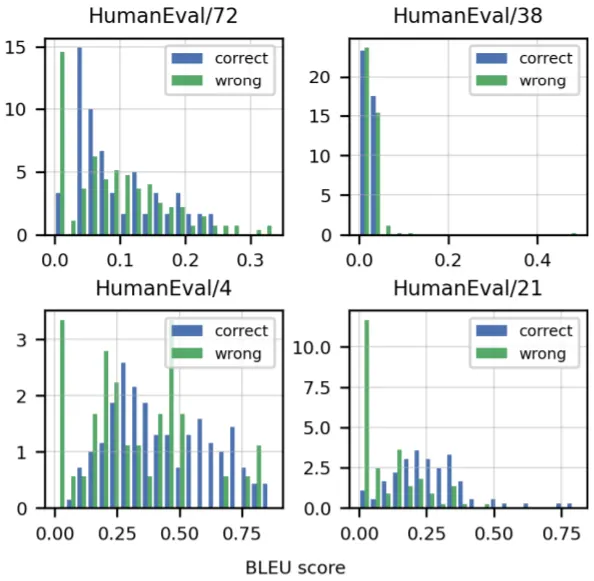
Code 생성의 경우에도 Model Size가 증가할수록 그 성능이 향상되며, 실제 서비스에서와 같이 생성된 Sample들 중 Top K를 선택해야 하는 경우, Mean Token Log Probability를 고려하는 것이 좋다고 한다. 마지막으로, 다음 표는 BLEU Score에 따른 정답+오답 Sample의 확률 밀도를 나타내는데, 특별한 상관성이 없는 것으로 미루어 볼 때, (앞서 언급했듯) Code 생성의 Evaluation Metric으로 BLEU Score를 사용하는 것은 적절하지 않다고 판단된다.