Meta AI의 General (Modality-Specific하지 않은) Self-Supervised Learning.
Speech, NLP, Vision의 연구 동향과 섬세한 Model Design.
Abstract
Self-Supervised Learning은 별도의 Labeling 없이 Data Representations를 학습하는 점에서 효율적이며 (Efficient), 동시에 효과적이다 (Effective).
•
NLP에서 BERT의 Masked Token Prediction (MLM)이 대표적이며,
•
증강 등을 통한 Positive Pairs가 동일한 Representations를 갖도록 이들을 Align하는 방식 (Contrastive Learning)으로 사용된다.
위와 같이 Self-Supervised Learning은 각 Modality에 따라 특화된 목적과 방식으로 수행되는데, 본 논문에서는 모든 Modality에서 공통적으로 사용할 수 있는 Framework인 data2vec을 제안한다.
•
구체적으로는 Full Input Data (온전한 Data)의 Representations를 Masked Input Data (일부가 Masked된 Data)의 Representations로부터 Prediction하는 과정을 거친다.
논문은 실험을 통해 제안한 Framework가 Text, Speech, Image에 특화된 기존의 Self-Supervised 기법들을 능가하는 모습을 보인다.
(GLUE Benchmark에서 RoBERTa를 뛰어넘는 성능..!)
Proposed Model: data2vec
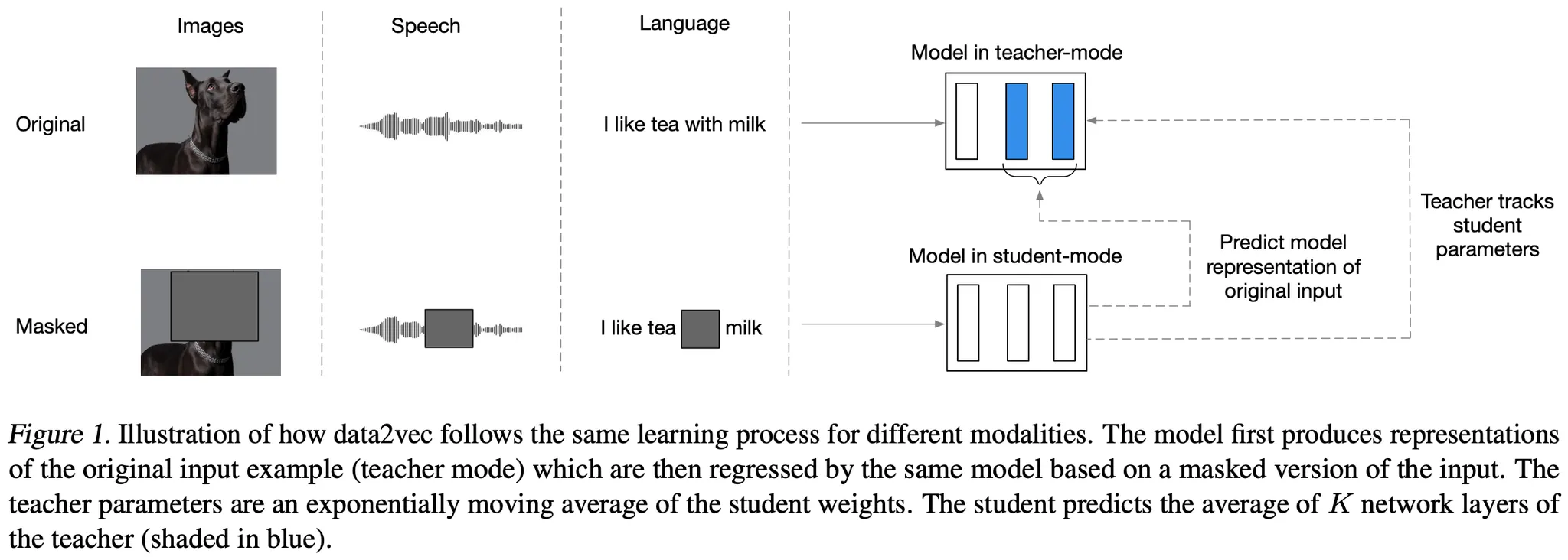
data2vec은 Transformer (Encoder) 구조를 가지며, Input Data의 종류에 따라 특화된 (기존의) Encoding, Masking 기법을 사용한다.
(학습 방식은 Data 종류에 상관없이 동일하지만, Encoding과 Masking 단계에서는 Modality-Specific한 방식을 사용함)
학습은 세부적으로
•
모델로부터 Masked Input Data의 Representations를 얻는 Student Mode,
•
동일한 모델로부터 (Target) Full Input Data의 Representations를 얻는 Teacher Mode,
•
그리고 Masked Representations로부터 Target Representations를 Prediction하는 과정
으로 구성된다.
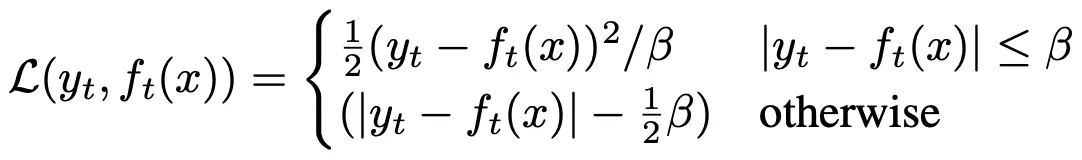
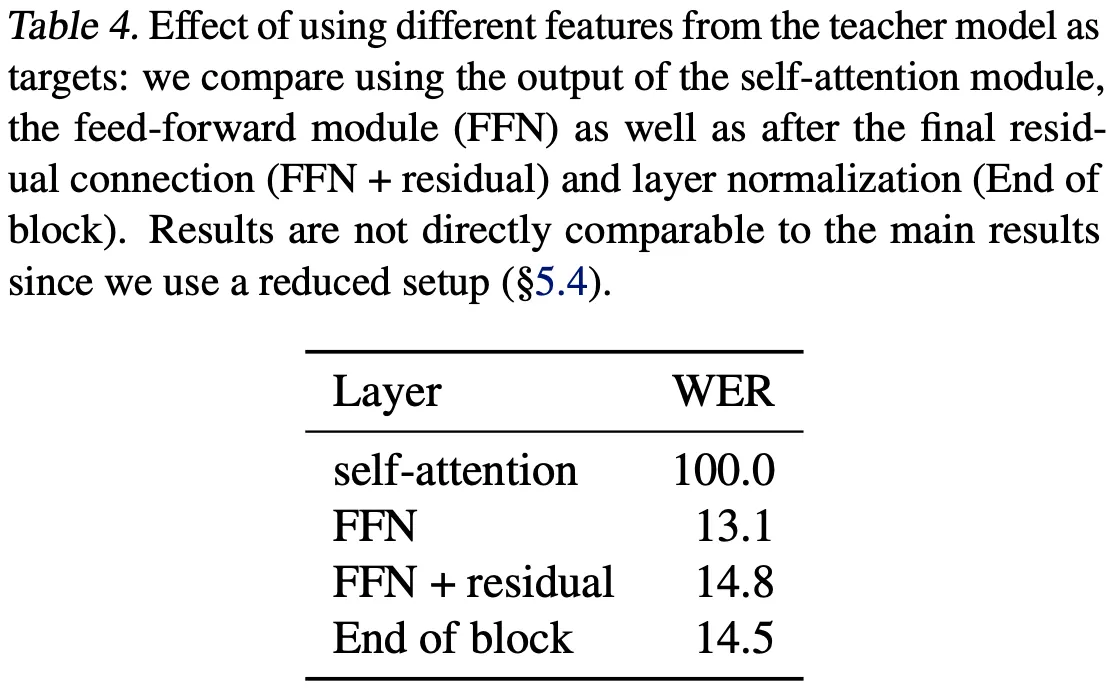
학습 과정에서 눈여겨볼 점들은 다음과 같다.
•
Target Representations는 모델 Params의 Exponentially Moving Average (EMA-Blog)로부터 얻어지는데, 학습 초기에는 Teacher Network가 자주 Update되고, 이후에는 (충분히 좋은 Params가 학습되었으므로) 덜 빈번하게 Update된다.
•
Student, Teacher Network는 동일한 Feature, Positional Encoder를 사용하는 편이 좋다.
•
Teacher Network의 Top-K Transformer Blocks를 단순 Averaging하여 Target Representations를 얻어도 (기존 Contrastive Learning에서 Projection Layer를 활용하는 것과 비교하여) 성능에 큰 문제가 없다.
•
단, Averaging 이전 Normalization을 거치는데, Speech는 Instance Norm, Text와 Image는 Layer Norm을 사용한다.
•
또한, Transformer Block으로는 FFN 이후 ~ 마지막 Residual Connection 이전 값을 사용한다.
•
Training Objective는 Outlier에 덜 민감하게 위 그림 (수식)과 같이 정의한다.
Experiments & Results
(실험 결과, 모든 Modality에서 data2vec이 가장 좋은 성능을 보이며, 본인은 NLP 및 Ablation Study 결과만을 확인함)
NLP의 Baseline은 BERT와 RoBERTa (단, BERT와 동일한 실험 환경)이며, GLUE Benchmark에서 성능을 측정한다.
data2vec은 50K의 Vocab (일반적인 Case, 35K에 비해 조금은 큰 느낌), 256 Batch, Max 512 Seq_Len, BERT의 Masking Strategy를 사용한다.
data2vec에는 추가로 wav2vec 2.0의 Span Masking Strategy를 적용해본다.
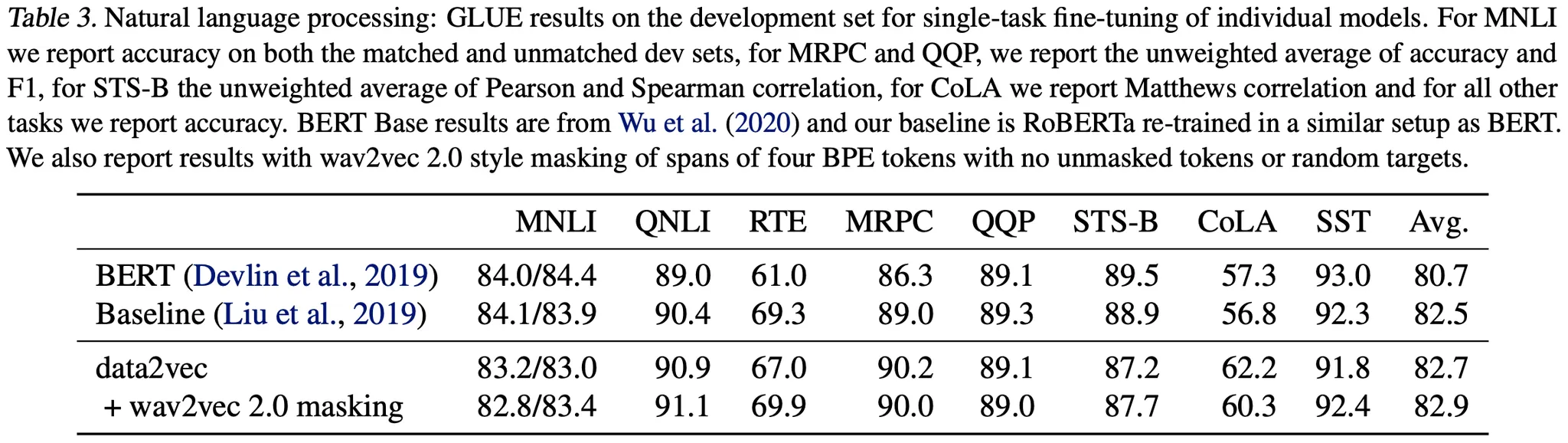
실험 결과, 위 그림과 같이 data2vec이 가장 좋은 성능을 보인다.
제안 모델의 장점으로, 특정 Discrete Token을 예측하는 기존 모델들과 달리, Self-Attention을 통한 Contextualized Latent를 예측하도록 학습하는 점을 생각할 수 있다.
wav2vec 2.0의 Masking 기법이 추가 성능 향상을 이끌어낸다.
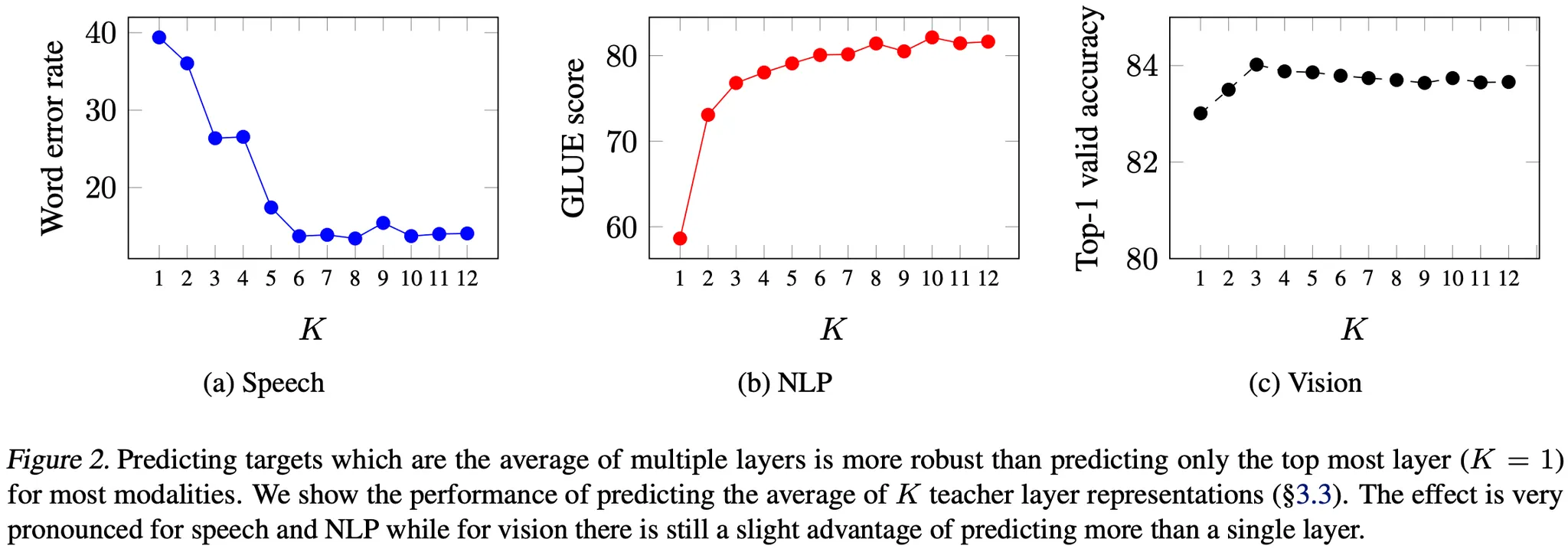
Target Representations를 얻는 데 활용하는 Transformer Block 수를 달리했을 때의 결과는 위 그림과 같다.
Speech, NLP에서는 더 많은 Blocks를 사용하는 편이 성능상 유리하다. (각 Transformer Block이 학습하는 정보가 모두 다르기 때문으로 생각할 수 있음)
Transformer Block으로 Self-Attention 직후 값을 사용하는 것은 성능에 큰 저하를 일으킴. (아래 그림, 다른 Time-Step에 편향된 Feature를 갖기 때문)