
EMNLP 2021, Google
Prefix-Tuning, Control Prefixes 등 최근 활발히 연구되는 Soft Prompts 기법에 대한 Google의 (Scaling) Research
Abstract
ELMo 이후, Transformer 기반 PLM을 Downstream Task에 적용하는 대표적인 방법은 모델을 해당 Dataset으로 Fine-Tuning (논문에서는 Model Tuning이라고 명칭)하는 것이다. 그러나 이는 모델의 모든 Params를 Update하는 점에서 효율적이지 않다.
GPT-3에서는 Prompting (논문에서는 Prompt Design)을 통해 별도의 Params Update 없이 Downstream Task를 수행하지만, 기본적으로 Zero/Few-Shot Learning인 만큼 성능이 불안정하고, (Prompt) Text에 매우 예민하게 반응하는 단점이 있다.
Li and Liang이 제안한 Prefix-Tuning은 Small Learnable Params를 Input에 Prepend하여, 이들만을 Update (PLM은 Freeze)하는 방식으로 Generation Tasks를 수행한다. Prefix-Tuning은 학습 시 Memory-Efficient하며, Task에 따라 PLM을 Modular하게 사용할 수 있는 장점이 있다.
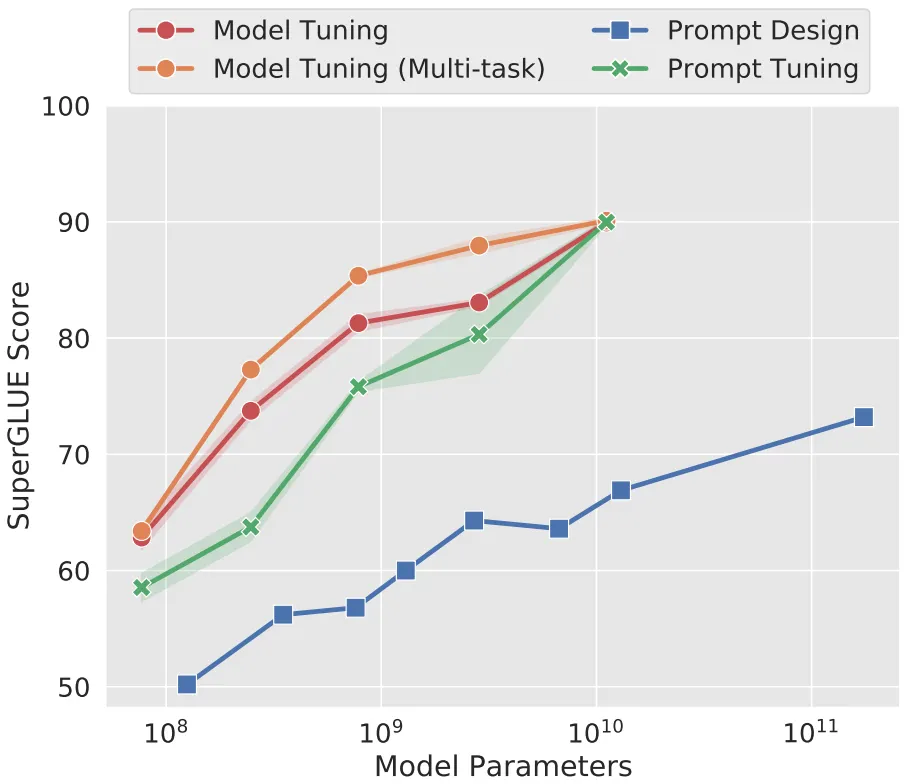
본 논문은 Prefix-Tuning의 변형 버전인 Prompt Tuning을 제안하고, 이를 T5에 적용하여 다양한 실험을 수행한다. 논문에서 핵심적으로 주장하는 Key Point는 Prompt Tuning의 성능이 PLM의 크기에 비례한다는 점이다. (아래 그림 참조)
Proposed Method: Prompt Tuning
Prompt Tuning은 Li and Liang의 Prefix-Tuning과 비교하여 크게 2가지 차이점이 있는데,
•
Encoder/Decoder의 모든 Layer Activations를 Cover하는 Prefix-Tuning과 달리, Encoder의 Input Layer Activation만을 Cover하며 (사실상 Virtual Tokens),
•
BART가 아닌 T5에서, NLU Tasks를 수행하는 점이다.
Prompt Tuning의 Design 요소로는 3가지가 존재한다.
•
Prompt Length
◦
Prefix-Tuning에 비해 Prompt Size가 작은 만큼, 더 긴 Length를 적용한다.
•
How To Initialize Prompt?
◦
Random하게 Init.
◦
Sampled Vocab을 PLM으로 Embedding.
◦
Classification Task의 경우, 가능한 Class Labels를 PLM으로 Embedding.
•
Further Pre-Training on T5
◦
Span Corruption: T5의 Pre-Training Objective는 Input Corrupted Spans의 Reconstruction이다. 특히, T5.1.1은 Corrupted 되지 않은 Natural Input을 받아 본 적이 없다.
◦
Span Corruption+Sentinel: Pre-Training Setting과 유사하게, Down Stream Task에 Sentinel을 Prepend한다.
◦
LM Adaptation: 저자는 Span Corruption이 Prompt Tuning에 적합하지 않다고 생각하여, LM Objective로 Further Pre-Training을 수행한다.
Experiments & Results
Prompt Tuning의 Default Setting은 다음과 같다.
•
Prompt Length of 100 Tokens
•
Initialize with Class Labels
•
LM Adaptation on T5.1.1 (100K Steps)
실험 결과, (맨 위 그림과 같이) Prompt Tuning의 성능은 PLM의 크기에 비례하며, 모델의 Size가 10B (Kakao KoGPT의 1.5배) 정도 되면 Model Tuning에 준하는 성능을 보인다.
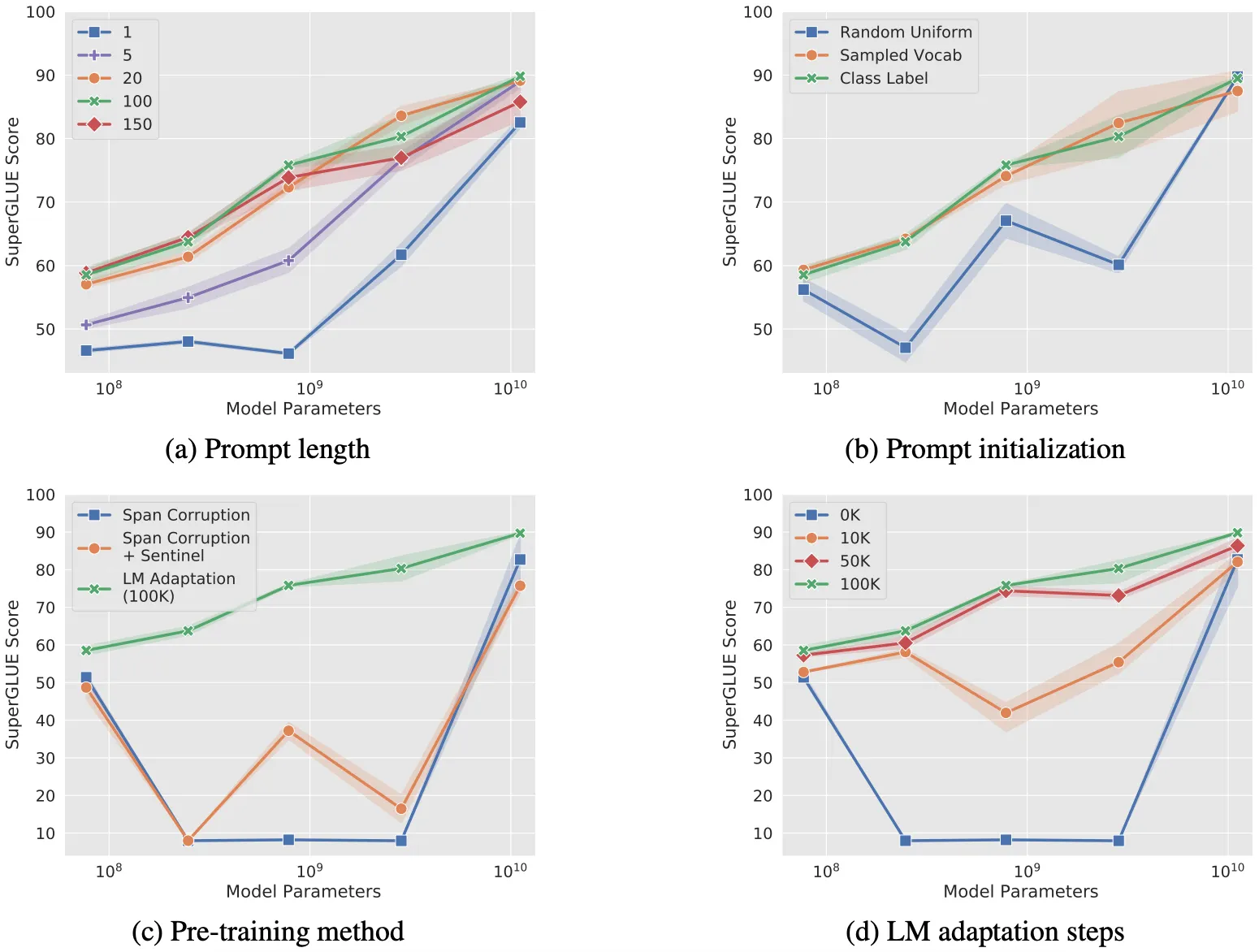
(바로 위 그림) Ablation Study를 통해 위 경향을 더욱 명확히 확인할 수 있다.
•
Prompt Length가 20 이하인 경우, 반대 경우에 비해 성능이 많이 떨어지지만, PLM의 크기가 10B이 되면 그 차이가 거의 사라진다.
•
Initialization 방법론에 따라 성능 차이가 발생하지만, 역시 PLM의 크기가 10B인 경우 성능 차이가 존재하지 않는다. Prefix-Tuning에서 Random Init이 좋은 성능을 보인 것과 다른 경향을 보이는 점이 흥미롭다.
•
Pre-Training Method & LM Adaptation Steps의 경우, 일부 Case에서 PLM의 크기가 증가할 때 오히려 성능이 큰 폭으로 떨어지는 경향을 보이지만, PLM의 크기가 10B이 되면 성능 차이가 결국 사라진다.
Ablation Study를 통해 Prompt Tuning의 성능은 PLM의 크기에 비례하는 것을 넘어, 크기에만 영향을 받는다고 (조금 과장하여) 생각할 수도 있겠다.
사실, 이러한 결과를 조금 당연하게 생각할 수 있는 것이, Prefix-Tuning에서도 Domain-Specific Generation 성능이 감소하는 대신 Generalization 성능이 오르는데, 이는 PLM의 Params를 고정시키면서 General한 능력을 확보할 수 있기 때문이다. 그러므로, PLM의 크기와 함께 Generalization 능력이 좋아지며, 결과적으로 성능이 증가하게 되는 것이다.
Prompt Tuning의 Generalization 능력, Modular한 점을 활용한 Domain Shift, Prompt Ensemble 성능도 좋은 편이며, Prompt의 의미를 Token Level에서 해석한 점 (Section 7) 역시 흥미롭다.