
9월 즈음 Google에서 공개한 Audio Generation 모델, AudioLM.
AudioLM으로 생성한 샘플들, 특히 Piano Continuation 샘플을 들었을 때 강한 흥미를 느꼈음! (생각보다 좋은 성능!)
AudioLM Paper를 가볍게 읽고 정리한, 미래에 살펴볼 Audio Domain Paper 리스트.
Google AI Blog Post

Generated Samples
AudioLM: a Language Modeling Approach to Audio Generation
•
기존의 Audio Generation 모델들은 (심지어 WaveNet을 비롯한 강력한 모델들도) Supervision 없이 좋은 성능을 낼 수 없었음
◦
Supervision이란, Speech에서 Transcriptions, 음악에서 MIDI Representations 등을 일컬음
◦
(본인은 대본이나 악보, 음계와 같은 느낌으로 이해함!)
•
Supervision의 제약을 극복하기 위하여 Transformer를 활용한 Textless NLP 연구가 수행되었으나, 생성한 Audio Quality가 좋지 않았음
◦
Sequence Modeling에 강점이 있는 Transformer를 활용하기에 Coherent한 Audio를 생성할 수는 있으나, 음원의 품질이 떨어지는 (Low Fidelity) 한계가 존재함
•
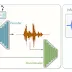
AudioLM은 Coherent+High-Quality Audio 생성을 위해 Semantic & Acoustic Token을 각각 Modeling하는 2개의 모델로 구성된 Hybrid Architecture를 제안함
◦
Semantic Token은 MLM으로 학습된 w2v-BERT로부터 얻을 수 있으며,
◦
NLP에서 BERT 계열 모델들과 유사하게 고차원의 Context 정보를 내포하므로 Coherent한 Audio를 생성하는 데에 기여한다고 생각할 수 있음
◦
단, 생성한 Audio의 Quality는 장담할 수 없음
◦
Acoustic Token은 Neural Audio Codec, SoundStream으로부터 얻을 수 있으며,
◦
Audio Quality에 직접 관여하므로 Semantic Token과 상호보완적임
•
AudioLM은 Coarse한 Semantic Tokens을 우선 Modeling한 후, 이를 기반으로 Fine-Level Acoustic Tokens을 Modeling함
Papers
•
Representative
◦
Wavenet: A generative model for raw audio
•
Adversarial Generation
◦
MelGAN: Generative adversarial networks for conditional waveform synthesis
◦
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis
◦
High fidelity speech synthesis with adversarial networks
•
Differentiable Quantization
◦
End-to-end optimized speech coding with deep neural networks
◦
Cascaded crossmodule residual learning towards lightweight end-to-end speech coding
◦
Harp-net: Hyper-autoencoded reconstruction propagation for scalable neural audio coding
•
Self-Supervised: Contrastive Learning
◦
Representation learning with contrastive predictive coding
◦
wav2vec 2.0: A framework for self-supervised learning of speech representations
◦
Contrastive learning of generalpurpose audio representations
◦
Data augmenting contrastive learning of speech representations in the time domain
•
Self-Supervised: MLM
◦
vq-wav2vec: Self-supervised learning of discrete speech representations
◦
Hubert: Self-supervised speech representation learning by masked prediction of hidden units
◦
w2vbert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training
•
Textless NLP
◦
The Zero Resource Speech Challenge 2021: Spoken language modelling
◦
On generative spoken language modeling from raw audio
◦
Text-Free Prosody-Aware Generative Spoken Language Modeling
◦
textless-lib: a library for textless spoken language processing