
지난 4월, Google에서 공개한 540B 초거대 언어 모델 PaLM (Pathways LM).
처음 논문을 접했을 때는 Pathways가 Mixture of Experts와 같은 방법론을 의미하나 싶었는데, 알고 보니 수천 개의 TPU 칩에서 모델을 학습시키는 ML System을 일컫는 용어였음!
(ML System 쪽은 아예 몰라서 “이런 방법이 있구나”의 느낌으로 리뷰하였음)
)최근, “구조는 간단하게(Transformer), 크기는 크게(Scaling Up)”의 NLP 트렌드에 맞게, 논문의 핵심 내용은 “Large-Scaled LM을 어떻게 효율적으로 학습(Accelerate)시키나?”이다.
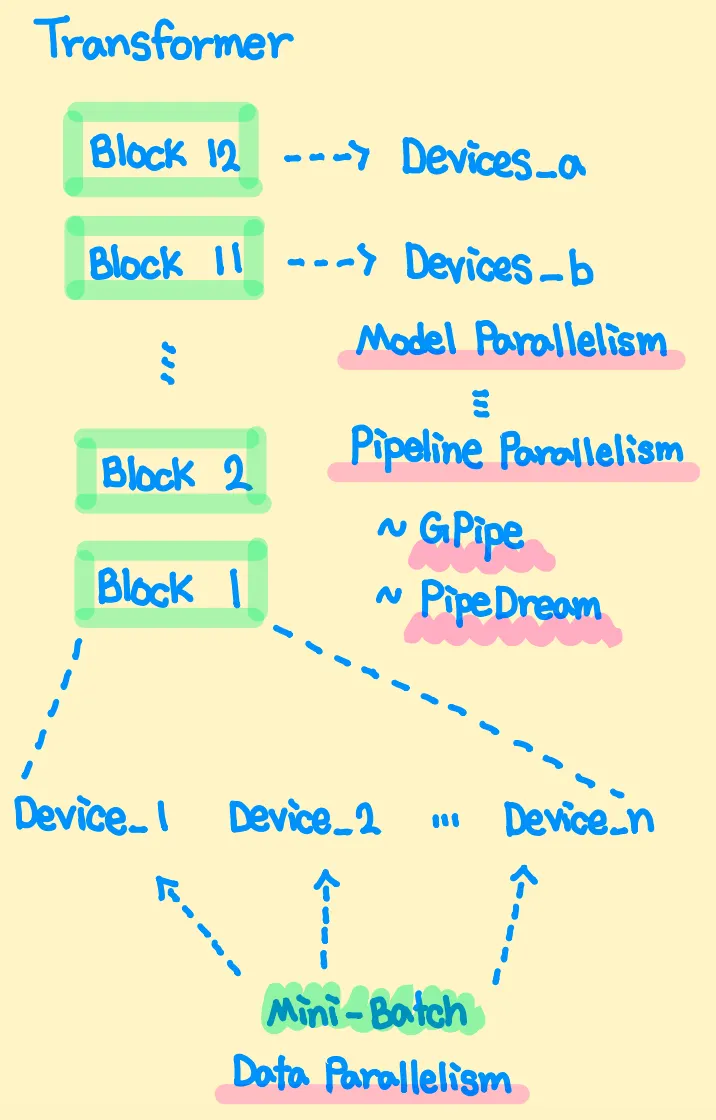
일반적으로 큰 모델을 Multi-Device (GPU, TPU) 환경에서 학습시킬 때, 다음과 같은 기법들을 사용한다.
•
각 Device에 모델을 동일하게 복사하여, Mini-Batch 일부를 독립적으로 Forward & Backward 하는 Data Parallelism (Effective Batch = n(devices) * batch_per_device)
•
각 Device에 모델의 파트들을 Load하여, Sequential하게 Forward & Backward를 수행하는 Model Parallelism
•
Model Parallelism에서 각 Layer들은 서로 순서-의존적이기 (이전 Layer의 결과를 기다려야 하기) 때문에, 학습에 비효율적인 측면이 존재하고, 이를 해결하기 위한 Pipeline Parallelism이 존재한다. 대표적으로 GPipe, PipeDream 기법들이 존재 (써본 적이 없어서 생소하다..)
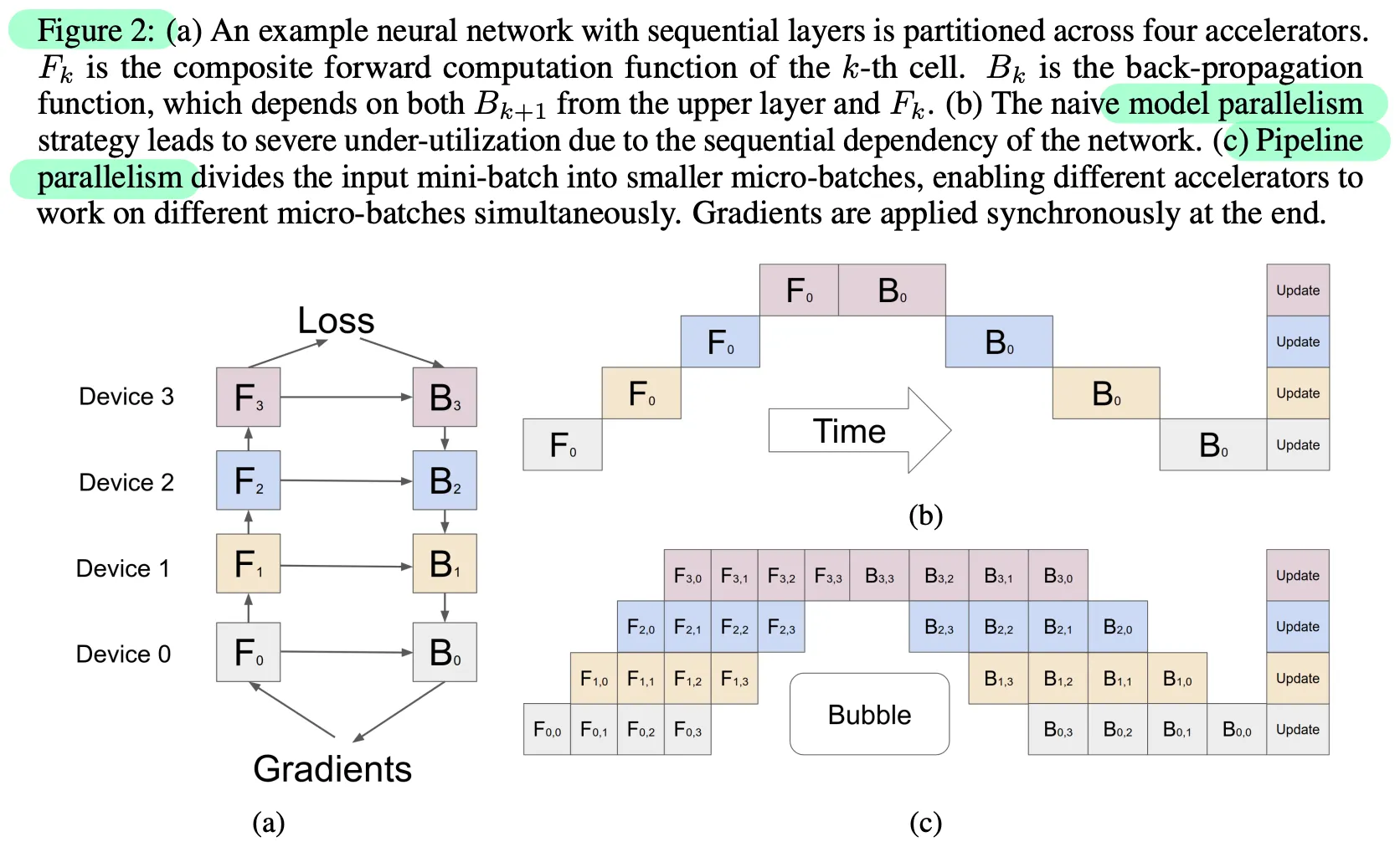
비슷한 크기의 Megatron LM은 위의 3가지 기법들을 모두 사용한 데 반해, PaLM은 Data & Model Parallelism만을 사용 (논문에서는 이를 “2D finalized”라 명명)한다.
PaLM의 주요 특징으로는 다음과 같은 점들이 있다.
•
Pipeline Parallelism을 사용하지 않음 (Because..)
◦
Pipelining Bubble이 발생함
◦
Mini-Batch를 Micro-Batch로 분해하는 방식으로 인하여, Higher Memory Bandwidth가 요구됨
•
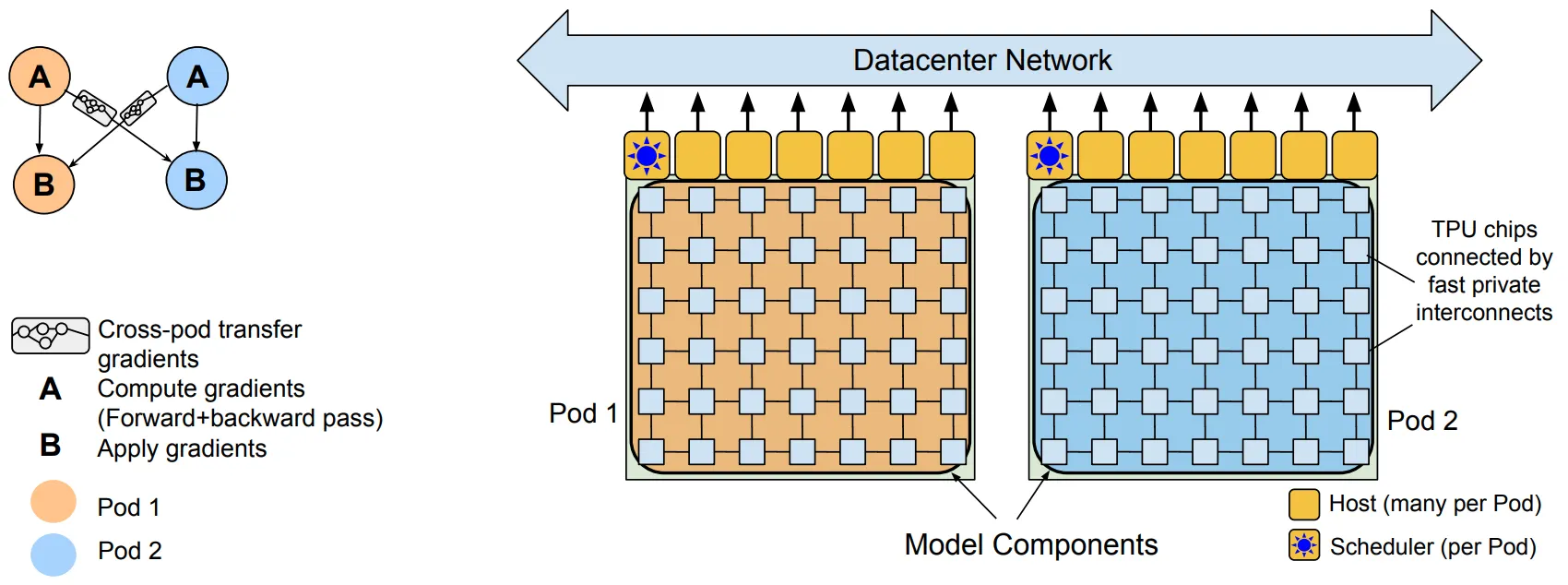
Pathways System을 사용함
◦
총 6,144개의 TPU를 2개의 Pod으로 나누어, 독립적으로 Forward & Backward 수행
◦
Datacenter Network (DCN)를 통한 Pods 간의 Gradient Transfer
결과적으로, 단일 Pod을 사용하는 경우에 비해 2배 정도의 Throughput을 보인다!