210905 Review Sentence Embedding Contrastive Learning

이 논문은 서울대, Naver가 ACL 2021에서 발표한 논문이다. Contrastive Learning을 활용한 BERT의 Sentence Embedding 학습이 주요 내용이며, 일반적인 Data Augmentation이 아닌 BERT의 초기 Layers Representation을 사용한 점이 흥미롭다.
Problems: BERT as Sentence Encoder
BERT를 Sentence Encoder로 사용하기 위해서는 Downstream Task로 (Supervision을 활용한) Fine-Tuning을 수행하여야 한다. 만약 Labeled Data가 존재하지 않는 경우, BERT의 마지막 Layer(s)를 Mean Pooling하여 사용하는 것이 일반적인데, 이는 좋은 성능을 보이지 못한다. (아래 표 참조). 아래의 표를 통해 Pooling기법과 Pooling에 사용하는 Layer에 따라 Sentence Embedding 성능의 편차가 매우 큰 점을 알 수 있는데, 이는 현재 BERT를 활용한 Sentence Embedding이 충분히 Solid하지 않으며, BERT의 Expressive Power를 더 활용할 여지가 남아 있음을 의미한다.
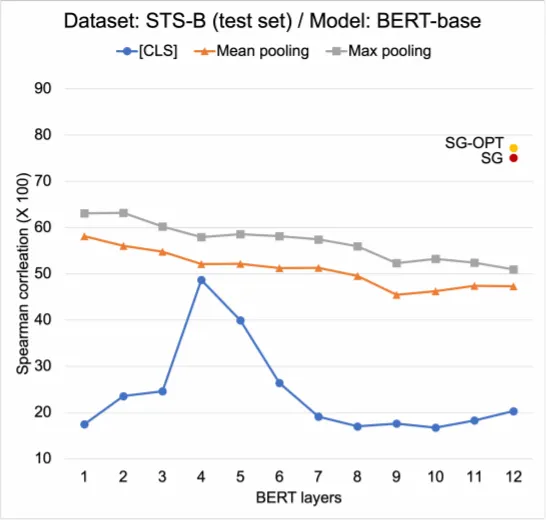
저자는 Unsupervised하게 BERT를 Sentence Encoder로 학습시키는 방안으로 Contrastive Learning에 주목하는데, 일반적인 Data Augmentation이 아닌 (위의 Intuition에 착안하여) BERT의 초기 Layer Representation을 활용하는 방식을 제안한다.
Proposed Method: Self-Guided Contrastive Learning
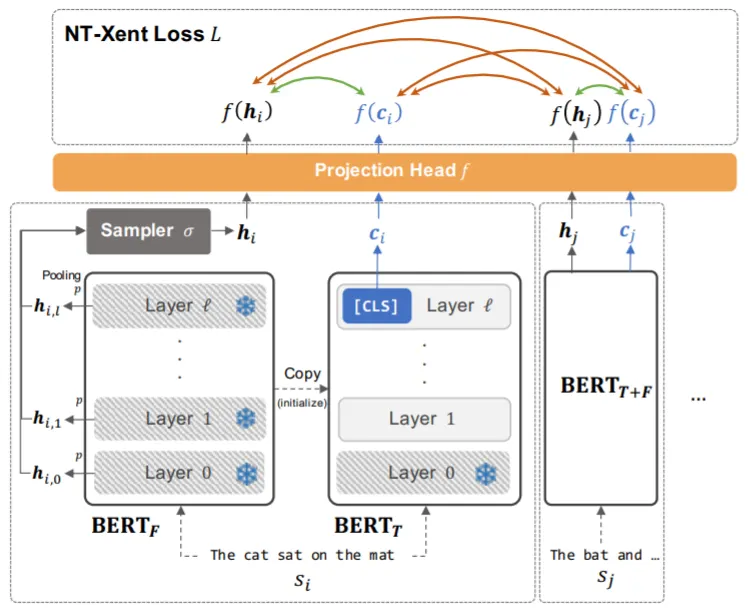
1.
BERT를 BERT_fixed, BERT_tuned 2가지 버전으로 복사.
•
BERT_fixed는 학습 시에 Training Signal(초기 Layer의 Representation)을 제공하는 고정된 Parameter의 모델
•
BERT_tuned는 Sentence Embedding을 위해 Fine-Tuning하는 모델
•
두 모델을 분리하는 이유는 학습 과정에서 BERT_fixed의 Training Signal의 성능이 저하되는 현상(BERT_fixed=BERT_tuned)을 방지하고, BERT의 여러 Layer들의 정보를 취합하자는 저자의 철학에 부합하기 때문
2.
Mini-Batch 문장들의 Hidden Representation Sampling.
•
Mini-Batch에 포함된 b개 중 i번째 문장의 k번째 Layer Representation: H_i,k
•
각 Layer Representation의 Pooling(논문에서는 Max Pooling) 수행: h_i,k=pooling(H_i,k)
•
Pooling된 Representation들 중 Sampling(논문에서는 Uniform Sampler) 수행: h_i=sampler({h_i,k | 0≤k≤num(BERT_fixed's Layers)})
3.
BERT_tuned로부터 Sentence Embedding 추출.
•
마지막 Layer의 CLS Token만을 Sentence Embedding으로 사용: c_i
•
X={x | {c_i} U {h_i}}
4.
Loss(NT-Xent Loss) 계산!
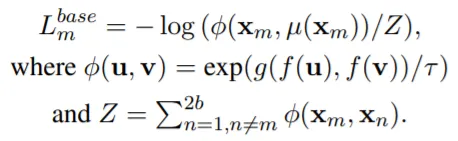
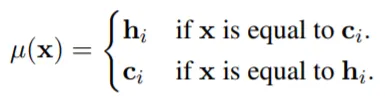
•
Sampling된 초기 Layer Representation, h_i와 Sentence Embedding, c_i는 각각 Projection Head(f)를 거친 후, 다른 벡터들과의 Cosine Similarity(g) 계산에 활용된다.
•
학습은 같은 문장의 h_i와 c_i의 유사도가 다른 문장들과의 유사도보다 큰 값을 갖도록 수행된다: L^base.
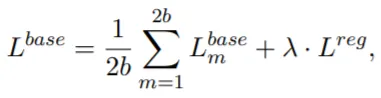
•
최종 Loss의 형태는 위와 같으며, Regularization항은 BERT_fixed와 BERT_tuned가 너무 다른 값을 갖지 않도록 조정하는 역할을 한다.
5.
Learning Objective Optimization!
•
L^base는 두 문장 s_i, s_j의 유사성을 4가지 요소들을 고려하여 정의한다.
(a) c_i →← h_i: (동일 문장) Sentence Embedding과 초기 Layer Representation의 유사성.
(b) c_i ←→ c_j
(c) c_i ←→ h_j
(d) h_i ←→ h_j
•
저자는 (a)요소만이 필수적이고, 하여 (a)에 특히 집중하기 위해 다른 요소들을 제거하는 방향으로 L^base를 수정한다.
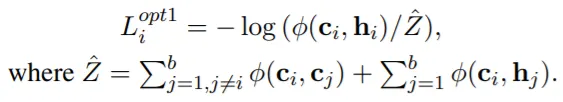
•
Option1: (d)제거.
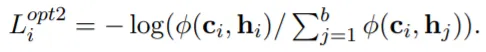
•
Option2: (b)제거.
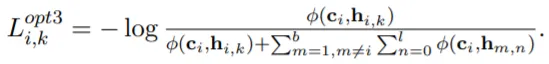
•
Option3: c_i와 h_i(or h_j)를 더 많은 관점(다양한or복수의 초기 Layer들의 Representation)에서 비교하기 위함.
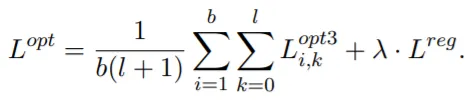
•
최종 Loss의 형태는 위와 같다: L^opt.
Experiments & Results
실험은 7가지 STS Datasets에서 수행되며, BERT+SBERT(-base, -large)에 기존 Sentence Embedding Method들과 제안 기법을 적용한 결과를 비교하여 성능을 평가한다. Baseline으로 사용하는 Method들에는 다음과 같은 것들이 있으며,
•
CLS Pooling
•
Mean Pooling
•
WK Pooling
•
Flow
•
Contrastive (BT: Back Translation)
제안 기법에는 L^base로 학습한 SG, L^opt로 학습한 SG-OPT가 있다.
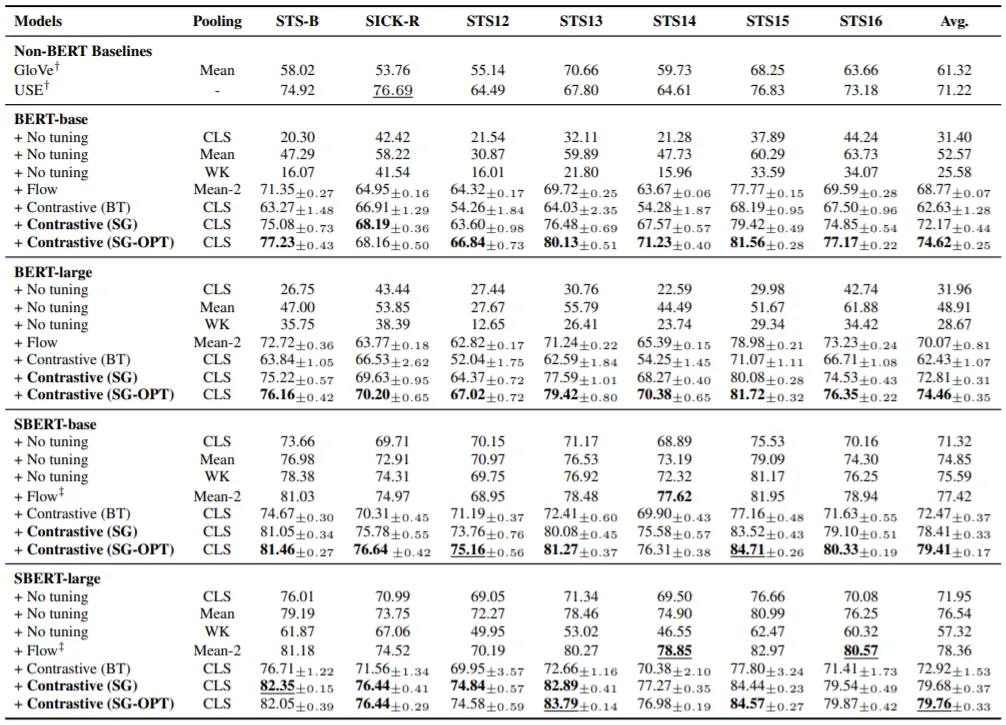
실험 결과는 위 표와 같은데, SBERT에서의 일부 Case를 제외하면, 제안 기법이 Baseline Methods에 비해 좋은 성능을 보임을 알 수 있다. 특히, SG-OPT가 SG의 성능을 능가함으로써 Learning Objective Optimization의 효과를 확인할 수 있다.
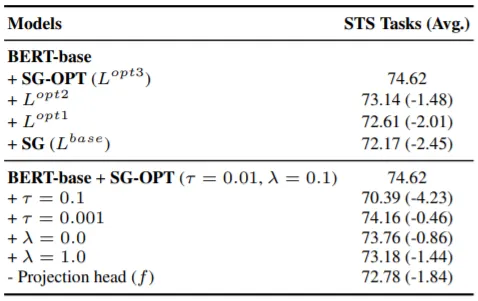
Learning Objective Optimization의 효과는 Ablation Study를 통해서도 증명된다. 위의 표 상단에 Loss를 변경하며 학습을 수행한 결과가 포함되어 있다. 표 하단을 통해 Hyperparameter값들도 성능에 큰 영향을 미침을 알 수 있다. Projection Head의 유무가 성능에 큰 차이를 만드는 점이 주목할 만하다.
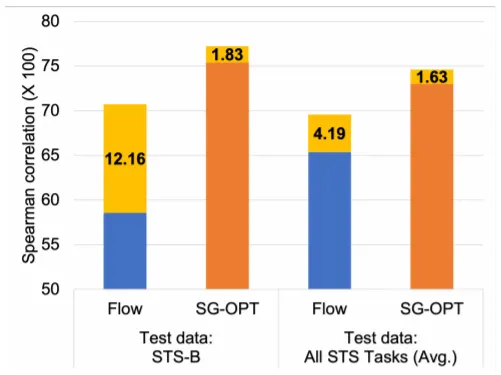
위 그래프는 BERT-base 모델을 NLI(or STS-B) Dataset으로 학습시키고 STS Datasets에서 테스팅 한 결과를 보인다. SG-OPT가 Flow에 비해 기본적인 성능도 좋고, In-Domain & Out-of-Domain 학습의 성능 차이가 작음을 확인할 수 있다: Robust to Domain Shifts.