
지난번, SimCSE & CPT에 이은 Sentence Encoder 리뷰 후속편.
Amazon에서 공개한 논문으로, ICLR 2022 Publications에서도 찾을 수 있음.
Unsupervised 제안 모델이 STS Benchmark에서 Supervised SimCSE에 준하는 성능을 보이길래 기대하며 읽었으나, 내용은 조금 실망스러웠음..
Last Review
Abstract
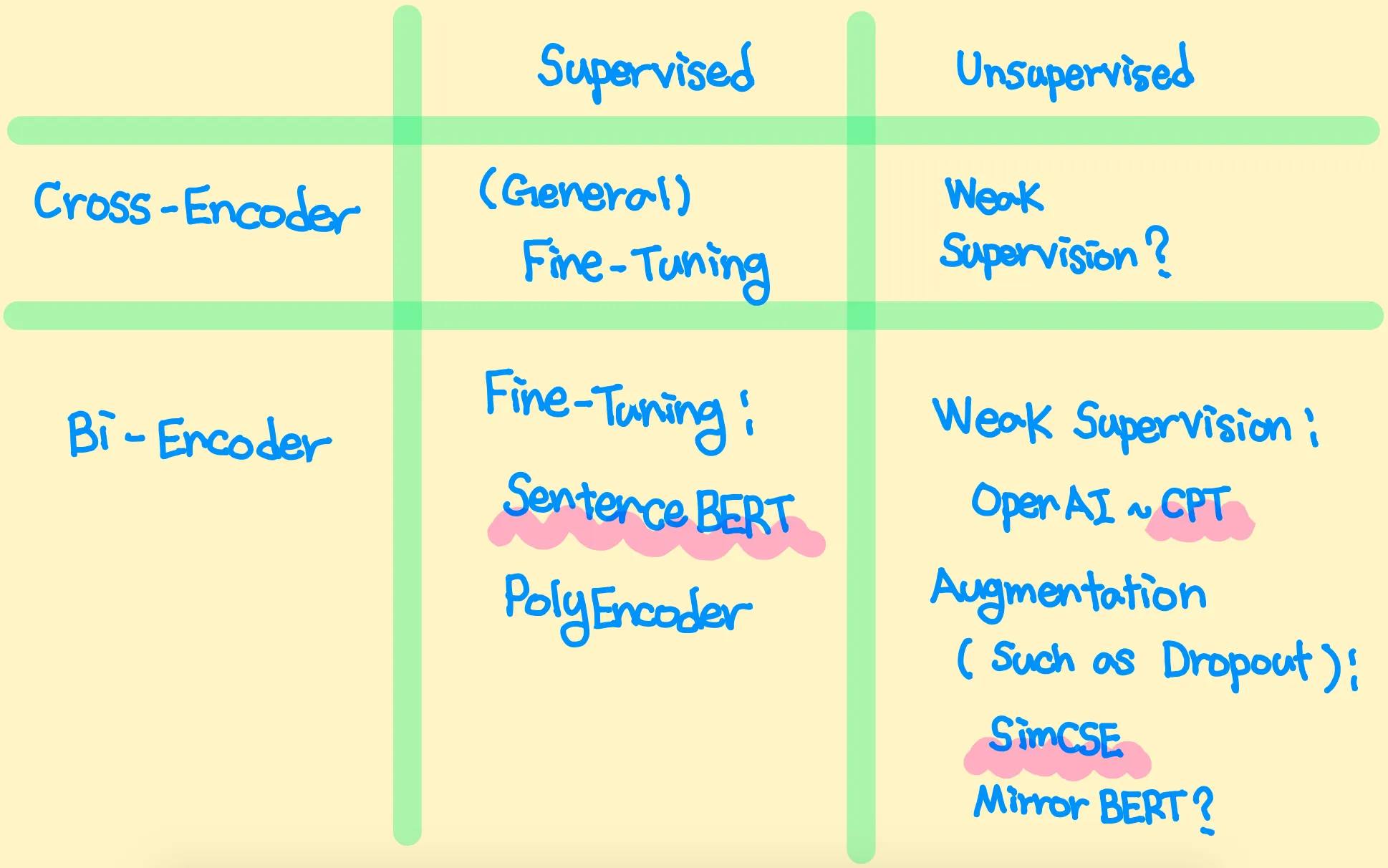
본인이 생각하는 BERT 기반 Sentence Encoder의 세부 분류는 위 그림과 같다.
Real-World Application에서는 DB 문서들의 임베딩을 미리 Caching 할 필요성이 있기에 대부분 Bi-Encoder 모델을 사용한다.
그러나 Bi-Encoder는 Cross-Encoder에 비해 낮은 성능을 보이는데, 해당 논문에서는 Bi/Cross-Encoder 간 Distillation을 반복함으로써 성능 문제를 일부 해결한다.
Proposed Model: Trans-Encoder
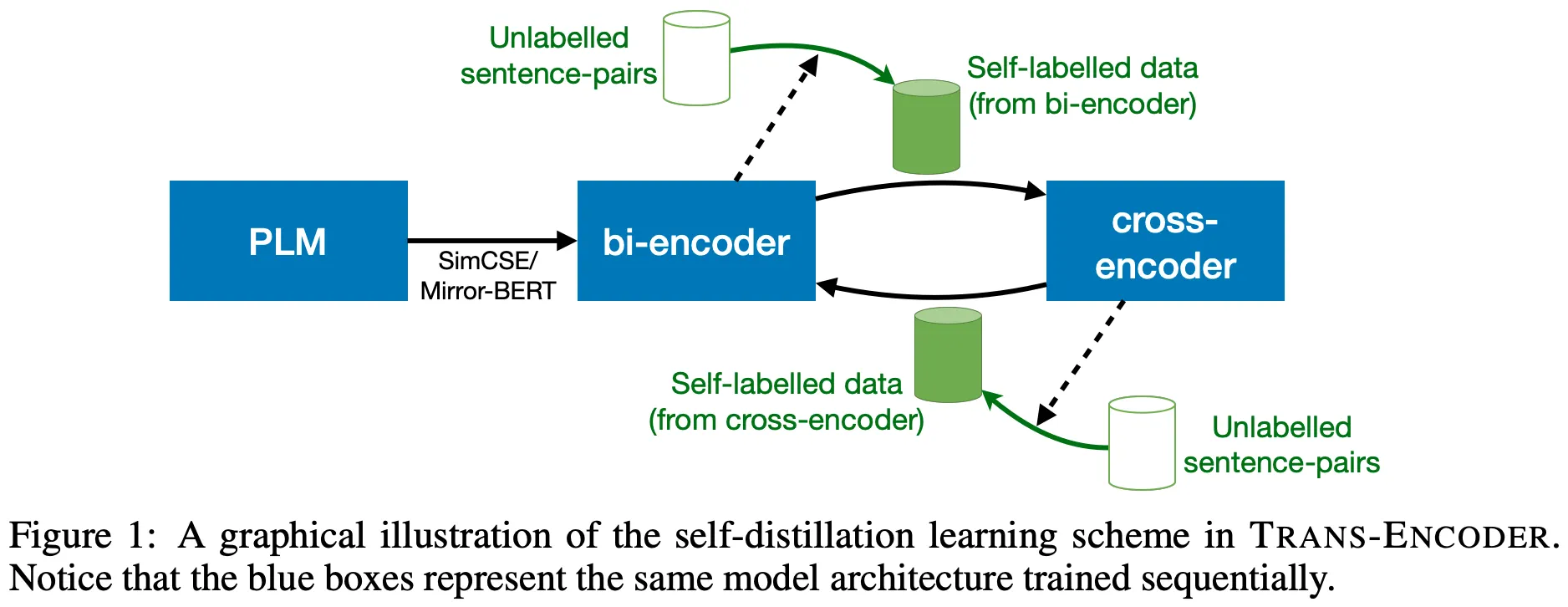
제안 모델들은 기본적으로 Unsupervised하게 학습되며, 그 과정은 위 그림과 같다.
•
일단, PLM으로부터 강력한 성능의 Bi-Encoder를 얻는다. Unsupervised Contrastive Learning을 활용하여 학습시킨 SimCSE (혹은 Mirror-BERT)를 사용한다
•
Bi-Encoder로부터 Unlabeled 문장 쌍들의 유사도 점수를 계산 (Vision에서 Noisy Student와 같은 느낌으로? Pseudo-Labeling)하고, 이를 활용하여 Cross-Encoder를 (Soft) BCE Loss로 학습시킨다
•
그리고 다시 Cross-Encoder로 Unlabeled 문장 쌍들의 유사도 점수를 계산하여, Bi-Encoder를 MSE Loss로 재학습시킨다
•
위의 두 과정을 반복한다
학습 과정의 원리는 다음과 같다.
•
기본적으로 Cross-Encoder가 Bi-Encoder에 비해 고차원적인 문장 간 정보를 캐치하기 때문에, Bi → Cross Distillation으로 Teacher 모델보다 좋은 성능의 Cross-Encoder를 얻을 수 있다
•
이 때, MSE Loss가 아닌 (Soft) BCE Loss를 사용하는 이유는 어느 정도의 유사도 오차를 허용함으로써, Bi/Cross-Encoder 모델 간 Discrepancy를 유지하기 위함이다. 그렇지 않다면 Cross-Encoder가 과적합되어 Bi-Encoder와 동일한 결과를 내뱉게 된다
•
Cross → Bi Distillation에서는 위와 같은 문제가 발생하지 않는데, 주어진 두 문장을 각각 포워딩하는 Bi-Encoder의 특성상 과적합이 발생할 확률이 낮기 때문이다. MSE Loss 사용!
•
여러 번의 Cycle을 통해 결과적으로 개선된 성능의 Bi-Encoder 모델을 얻게 된다
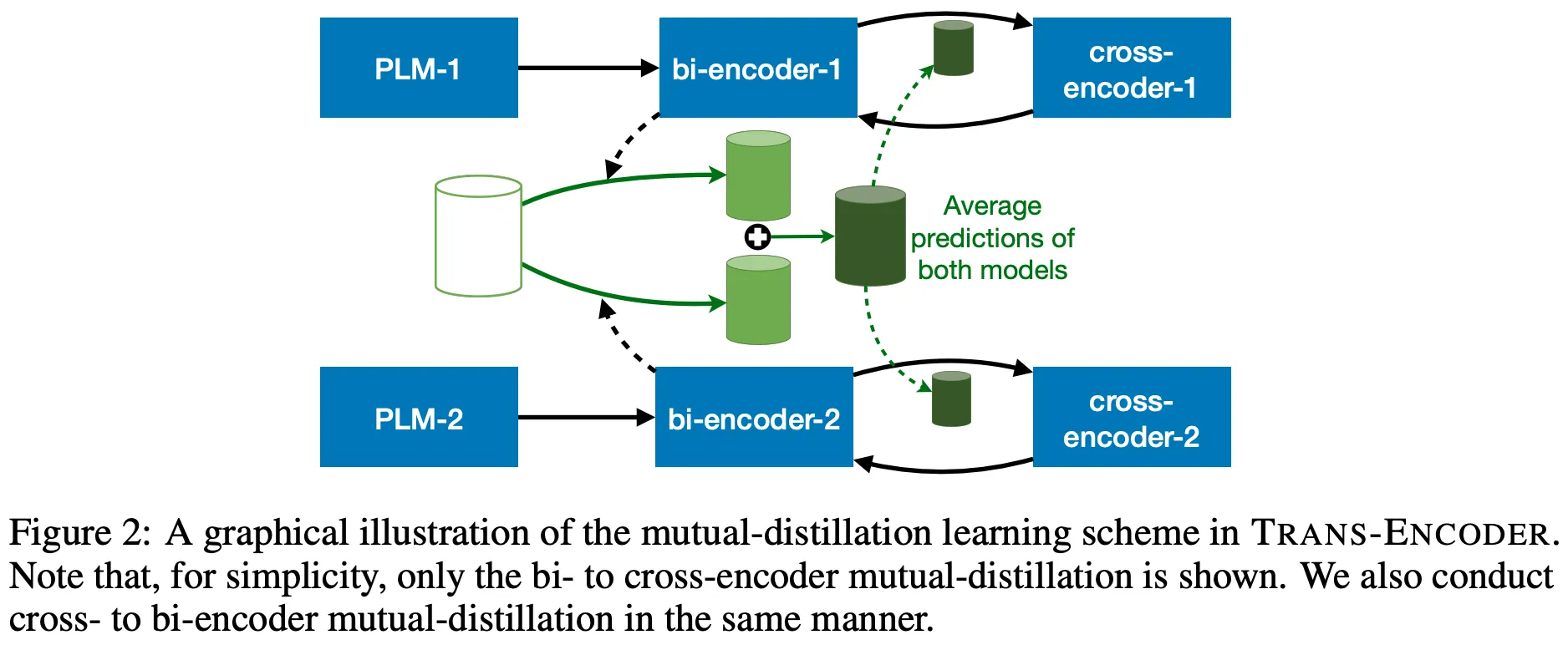
위 그림과 같이 2개의 서로 다른 PLM을 활용한 방식, Mutual-Distillation,을 추가로 제안한다.
(일종의 Ensemble로, 핵심 내용은 아니라고 판단하여 참고 정도만 하였다)
Experiments & Results
실험은 STS & 주어진 두 문장의 관계를 파악하는 Binary Classification Datasets에서 수행되는데, STS 결과만을 살펴보도록 하겠다.
문장 임베딩으로는 [CLS] Token을 사용하며, STS는 3 Cycle, Binary Classification은 5 Cycle 학습을 반복한다.
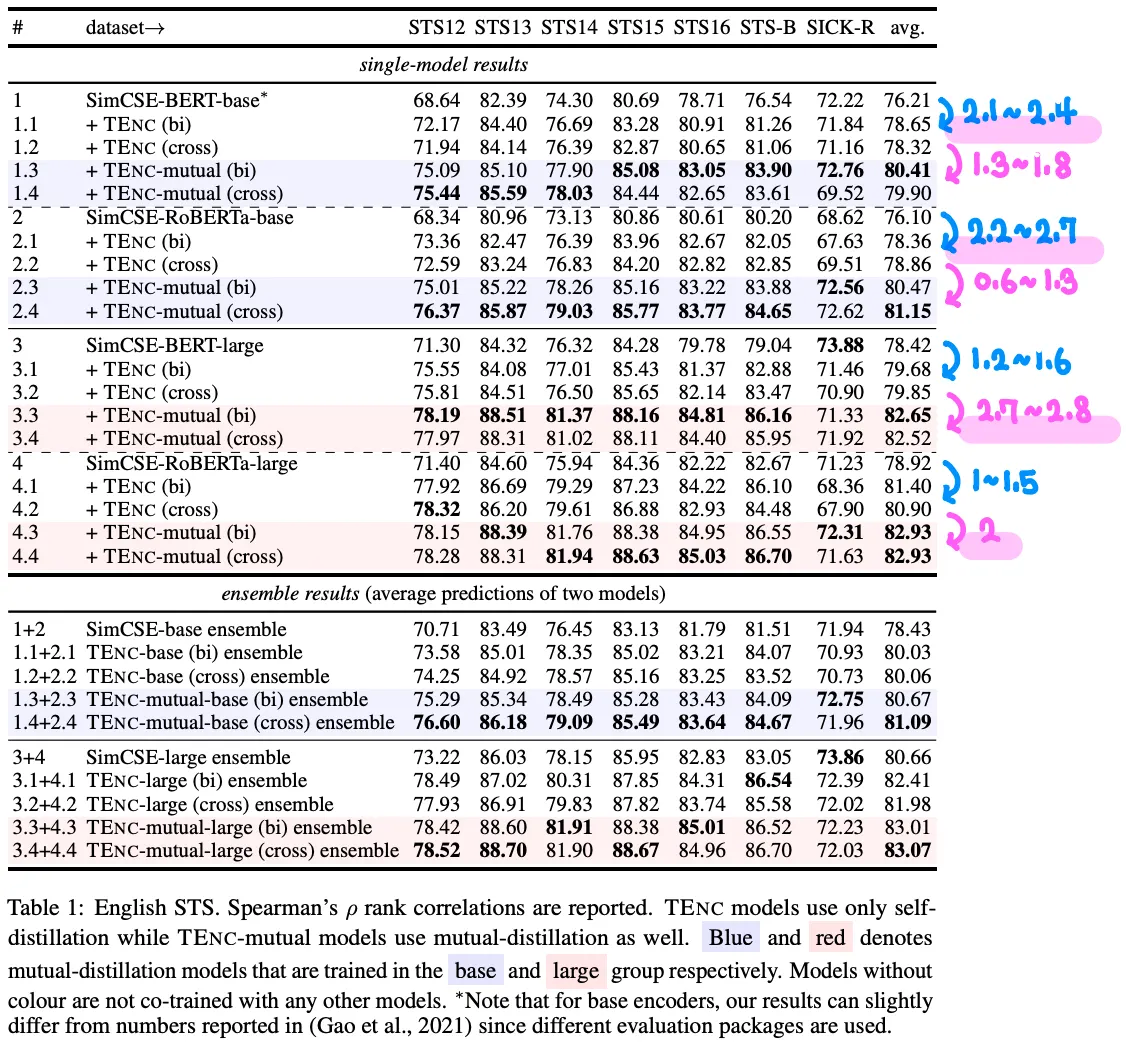
SimCSE와 비교한 메인 실험 결과는 위 그림과 같다.
기본적으로 성능이 엄청나게 향상되는데, 본인은 실험 환경이 공정하지 못하다고 생각한다.
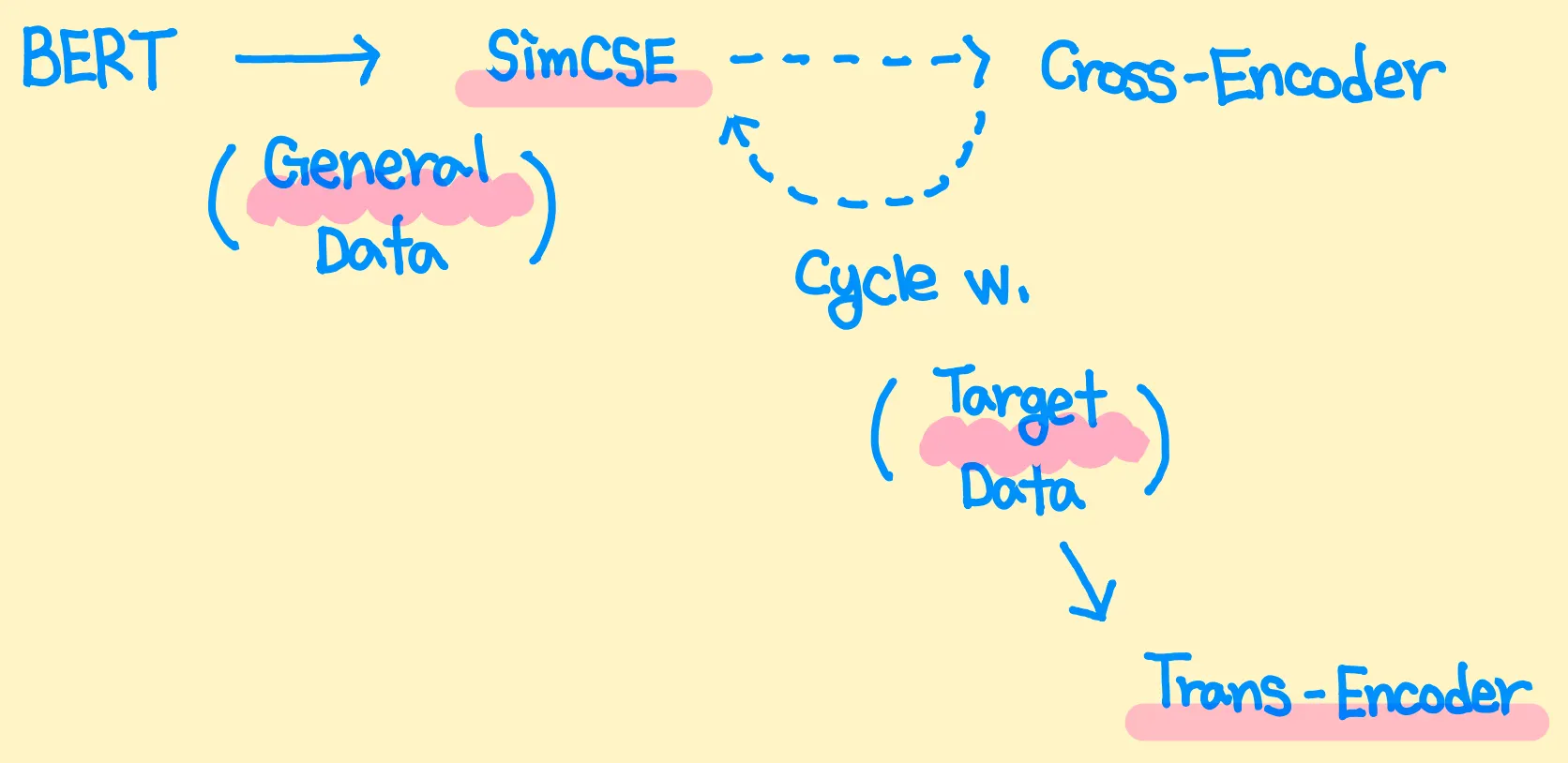
SimCSE와 Trans-Encoder의 학습 과정을 도식화한 그림이다.
SimCSE의 학습 과정을 General Data (Wikipedia)를 활용한 Pre-Training이라고 본다면, Trans-Encoder의 학습 과정은 일종의 Task-Adaptive Further Pre-Training으로 생각할 수 있다.
(Target Data는 STS Datasets의 Train Set이다. 비록 Label은 학습에 사용되지 않지만, Test Set과 동일한 Style의 Data를 본다는 점이 약간의 Cheating으로 생각된다)
만약, SimCSE 역시 Target Data로 (본래 Dropout을 활용하는 방식) Furether Pre-Training 시킨 후, 성능을 비교하였다면 조금 더 납득이 가지 않았을까 생각한다.
이와 비슷한 내용이 Binary Classification 결과 분석란에서 언급되긴 하지만, 충분한 논리가 제시되지 않았다고 생각한다.