
ACL 2021에서 발표된 Text Style Transfer에 관한 Google Research Paper.
Labeled Dataset 없이 학습이 가능한 점이 Key Point.
Inference에서는 Style-Labeled Data가 일부 필요하지만(Few-Shot), Data 수에 Gain이 비례하지 않아 종속적이지 않음.
Problems: Previous Methods
기존의 Text Style Transfer 기법들은 Labeled Dataset을 필요로 함.
기법들은 Label 형태에 따라 다음과 같이 구분할 수 있음.
•
Supervised
◦
각 Style에 상응하는 문장 쌍들 필요
◦
Parallel Dataset (on Translation)과 유사
•
Unsupervised
◦
각 Style별 문장들 필요
◦
Monolingual Dataset과 유사
•
Few-Shot
◦
Labeled Dataset이 필요하지 않음
◦
다만, Inference에서 일부 Labeled Data 필요
Proposed Model: TextSETTR
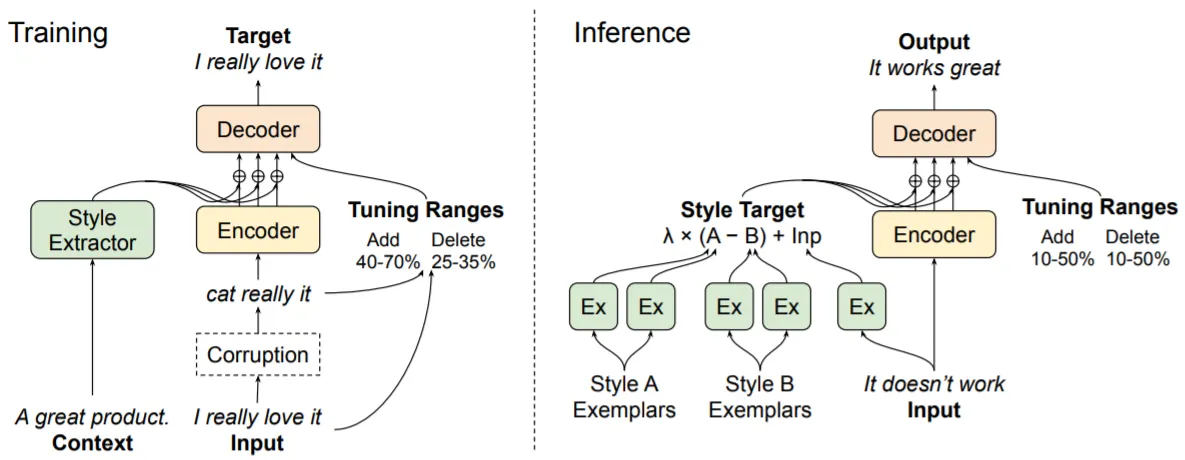
기본적으로 Lample의 (Unsupervised) 연구에서 착안함. Lample은 Facebook에서 Parallel Data 없이 Translation을 수행하는 연구들을 했던 것으로 아는데, Style Transfer가 Translation과 결이 비슷하다 보니 이에 관한 연구도 진행하지 않았을까..? 생각함.
•
(Corrupted) Input 문장의 Style 정보 (Style Vector)를 참고하여 Denoising을 수행하는 것이 학습의 핵심 아이디어
•
Style 정보는 Style Extractor를 활용하여 인접한 문장으로부터 추출: 인접한 문장은 동일한 Style일 것으로 가정
•
Pre-Trained LM이 충분한 Style Representation 능력을 학습했을 것으로 생각하여 Pre-Trained T5를 Base로 Fine-Tuning 수행
•
Style Extractor는 T5의 Encoder와 동일한 구조이며(단, 마지막에 Mean Pooling 수행), Style Vector는 Encoder의 Final Hidden States에 더해 줌
3종류의 Corruption 기법이 있으며, 각 Loss들을 더하여 Final Loss로 사용함.
•
Noise (N)
◦
단순 Noising으로 Token들을 Drop, Replace, Shuffle (각 20~60% 확률)
◦
학습 시, Token들의 Add & Delete Rate을 Decoder에 명시하며, 이는 Inference에서 Tunable (Flexible) Transfer를 가능케 함
•
Back Translation (BT)
◦
Input을 Inference Mode의 현재 LM으로 Back Translation 수행
◦
Style Vector를 추출하는 문장은 Random Sampling
•
Noisy Back Translation (NBT)
◦
Noise+Back Translation
◦
본문에서 저자는 NBT가 BT보다 Style Transfer에 적합하다고 주장하지만, 실제 실험 결과는 그렇지 못함
Inference는 다음 과정과 같음.
•
Source & Target Style-Labeled 문장들을 (대략 100개씩) Sampling하여 각 Style Vector들을 Averaging: v_src, v_trg
•
Input 문장의 Style Vector (v_x)를 추출하고, Source ->Target 방향으로 Style Vector 정의:
v_x+lambda*(v_trg-v_src)
Experiments & Results
Sentiment Transfer 실험을 통해 TextSETTR의 성능을 보임.
•
Amazon Reviews의 다중 문장 Data 사용
•
Fine-Tuned BERT Classifier로 Sentiment Transfer Accuracy 측정
•
SacreBLEU로 self-BLEU (Content Preservation) 측정
•
통합 성능으로 G-Score 사용
•
Noise(Drop+Replace)+Noisy Back Translation으로 학습한 Baseline
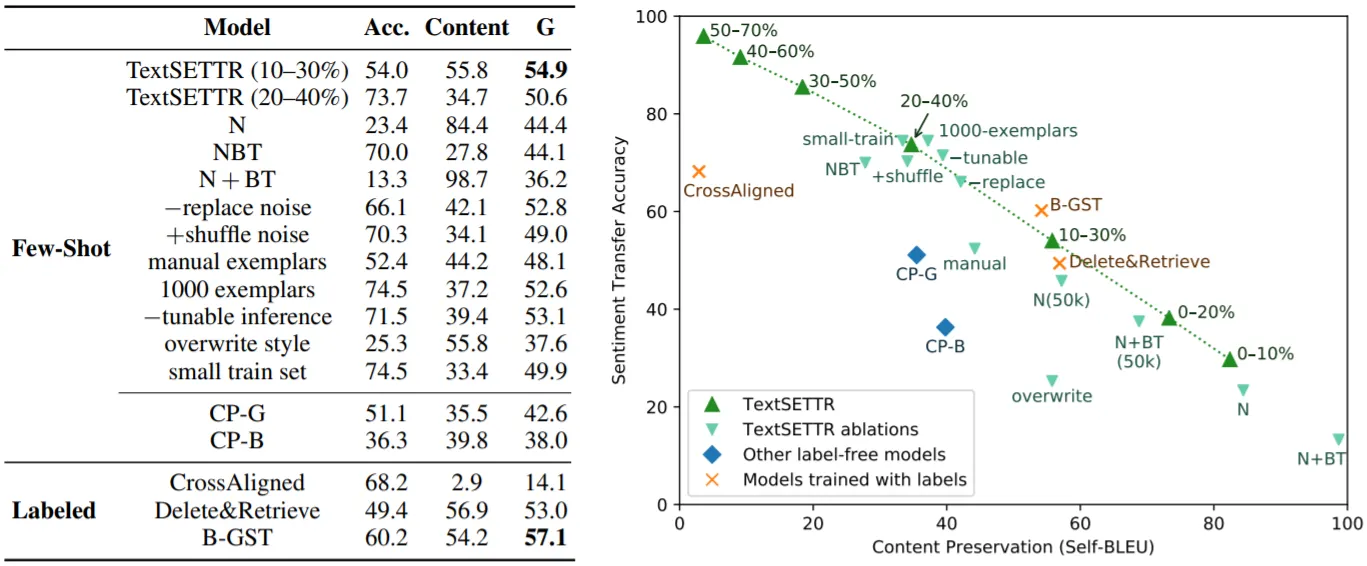
주요 실험 결과를 정리하면,
•
Sentiment Accuracy와 Content Preservation은 Trade-Off 관계
•
TextSETTR는 기존의 Few-Shot 기법들보다 좋은 성능을 보이며, Labeled Data로 학습한 기법들에 준함
•
표에서 N+NBT가 N+BT에 비해 좋은 성능을 보이지만, 주석에 따르면 Tunable Inference를 통해 N+BT의 성능을 N+NBT 이상으로 향상시킬 수 있음
•
Inference에서 더 많은 문장들을 Sampling하여도 Gain이 크지 않음
•
Small Dataset으로도 잘 동작함