Sentence Embedding을 위한 LM의 Contrastive Learning 방법론.
SimCSE와 OpenAI의 CPT (Contrastive Pre-Training).
간단한 방식에 좋은 성능으로 실제로 활용하기 좋아 보인다!
Abstract
현재 자연어 임베딩 모델의 SOTA는 BERT를 비롯한 Transformer Encoder 계열의 모델들로, 이들은 Downstream Tasks로의 Transfer Learning을 전제로 한다.
이는 순수한 BERT 임베딩이 그 자체로는 크게 유의미하지 않음을 의미한다.
예를 들어, 다음과 같은 3개의 문장을 BERT로 단순 임베딩하면,
a.
나는 아이스크림을 자주 사먹는다
b.
아이스크림은 내가 가장 좋아하는 간식이다
c.
요즘 아이스크림 가격이 많이 올랐다
문장 쌍 (a, b)가 (a, c)나 (b, c)에 비해 높은 유사도를 가질 것으로 기대하지만, 실제로는 3개 문장이 모두 비슷한 Vector Space에 존재하게 된다.
이는 BERT 임베딩이 Vector Space 상에 깔때기(Cone) 모양으로 심하게 편향되어 있는 Anisotropy Problem에서 비롯된 현상이다.
위 문제는 BERT의 좋은 성능에도 모델을 현실 서비스에 적용하는 것을 어렵게 만든다.
현실 서비스에서 발생할 수 있는 문제를 개조식으로 서술하면,
•
사용자의 질문에 답을 하는 챗봇이 있다고 가정하자
•
올바른 답을 하기 위해 사용자의 질문과 유사한 (정답을 포함할 확률이 높은) 문서들을 우선 DB에서 추려야 한다
•
이 때, 질문과 문서들 간 유사도를 계산하기 위해 일반적인 BERT 모델 (질문+문서를 입력으로 유사도를 출력하는 Cross-Encoder 형태)을 활용하면 n(문서) 만큼의 모델 포워딩이 필요하다
•
이를 완화하기 위해 문서들을 미리 BERT로 임베딩 하였다가, 사용자의 질문이 들어오면 Cosine Similarity 등을 활용하여 문서들을 추릴 수 있으나 Anisotropy Problem으로 인해 성능이 좋지 않다
SBERT와 같은 기존의 연구들은 유사한 문장들이 Vector Space 상에 가깝게 위치하도록 하는 데(Alignment)에 집중하여 BERT를 순수한 임베딩 모델로 활용하였다.
반면, SimCSE와 CPT는 Anisotropy Problem의 직접적인 원인인 Lack of Uniformity를 해결하는 데에 집중하여 순수 임베딩 모델로서 BERT의 성능을 대폭 끌어올렸다.
CLIP과 더불어 이제는 NLP에서도 범용적인 방법론이 된 Contrastive Learning을 활용한 점이 주요 특징이다.
SimCSE
•
기본적으로 제안 모델의 구조는 Pre-Trained BERT or RoBERTa (단일 Encoder) 기반이다
•
Pooling 방법으로는 Output의 [CLS] Token을 입력 문장의 임베딩으로 사용한다
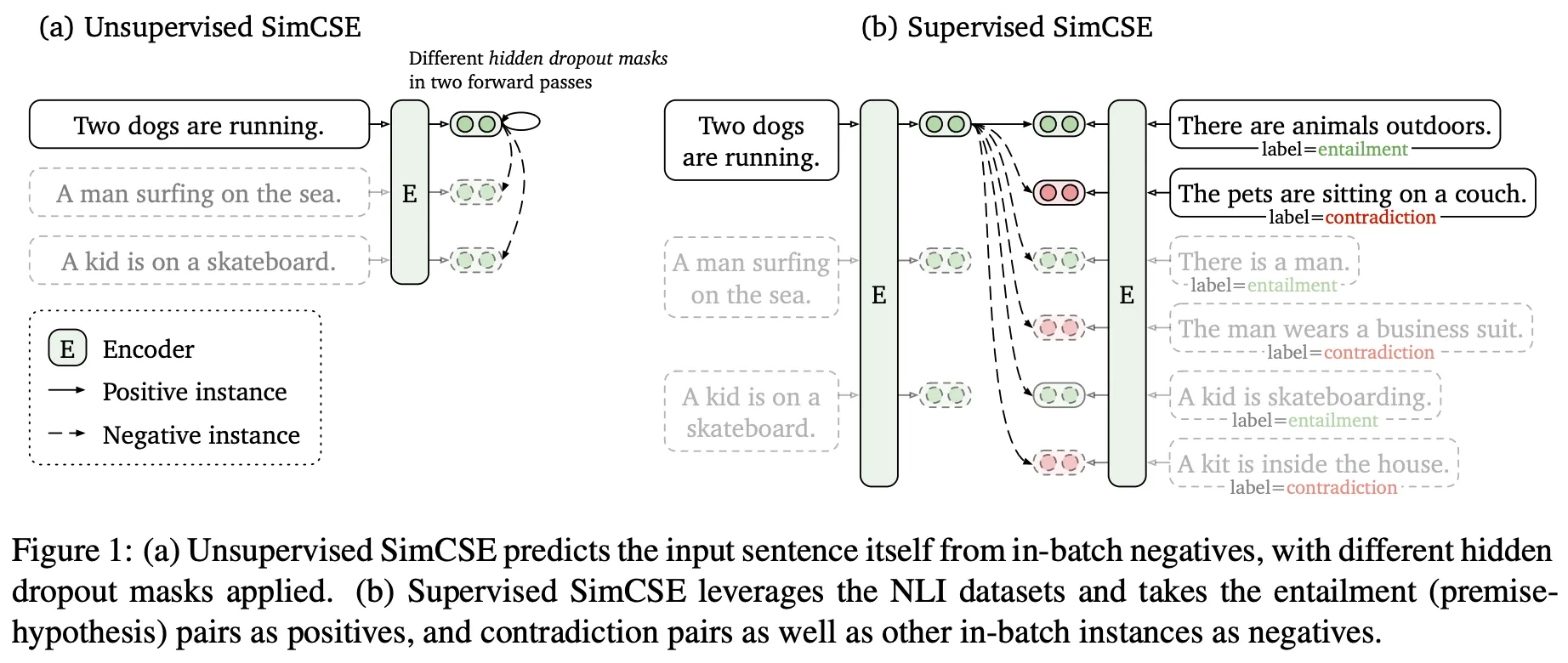
Unsupervised SimCSE
•
Wikipedia에서 샘플링한 문장들을 데이터로 사용한다
•
Positive Pair를 구축하는 방식은 단순히 동일한 Input을 모델에 2번 포워딩하는 것이다. 이 때, Dropout에 의해 서로 (약간) 다른 Output을 얻을 수 있으며, 이들이 Positive Pair가 된다 (너무나 간단한 방법)
◦
입력 문장을 단어 제거, 동의어 교체 등의 Discrete Augmentation하는 방식은 제안 방식에 비해 성능이 좋지 않다
◦
Dropout Rate 역시 BERT Default Setting, 10%로 설정하는 편이 가장 좋다
•
학습 시에는 [CLS] Token 상단에 MLP Layer를 추가하지만, Inference에서는 제거하여 사용한다
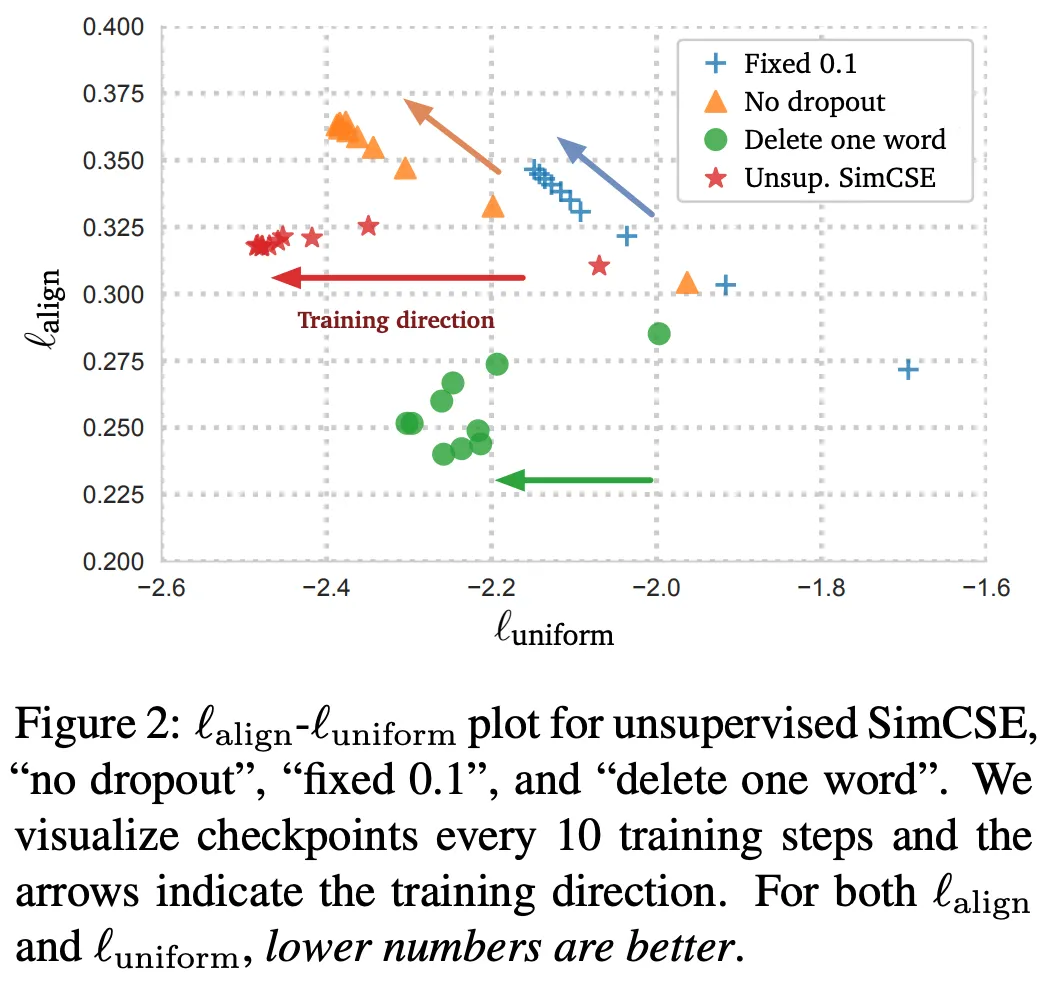
•
(아래 그림) 제안 방식이 가장 좋은 성능을 내는 결정적인 이유가 Uniformity 확보임을 알 수 있다
Supervised SimCSE
•
NLI Dataset에서 주어진 문장과 Entailment 관계인 문장을 Positive Pair, 다른 문장들을 Negative Samples로 사용한다
◦
NLI Dataset은 Lexical Overlap이 적으면서 의미적으로 유사한 (Entailment) 문장을 포함하기 때문에 퀄리티가 좋으며, SNLI+MNLI를 합쳐 사용한다
◦
주어진 문장과 Contradiction 관계에 있는 문장을 Hard Negative로 다른 Negative Samples에 비해 큰 가중치를 줄 수 있으나 성능 상 큰 의미가 없다
•
Unsupervised Case와 달리 MLP Layer를 사용하지 않는다
CPT
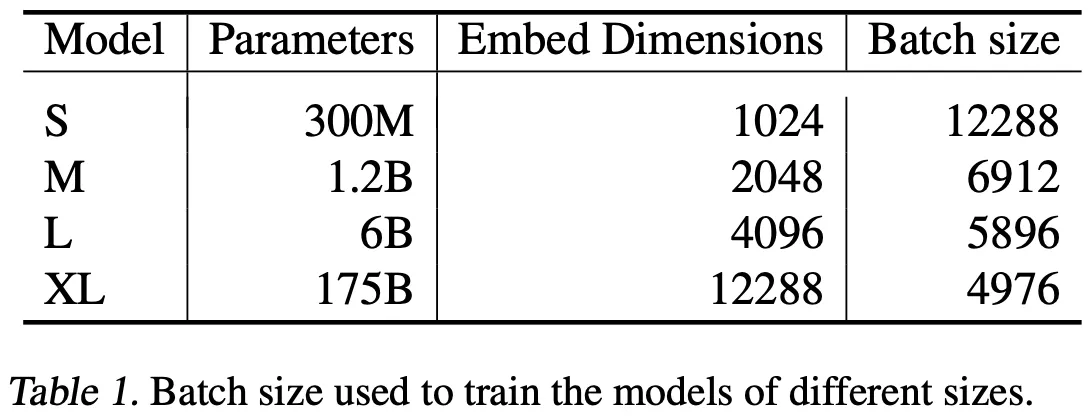
•
OpenAI 연구답게 모델의 크기를 매우 크게하여 실험을 수행한다
•
독특한 점은 기본 모델로 Pre-Trained GPT, Codex (생성 모델)를 사용한다
•
생성 모델 (Uni-Directional Attention)을 사용하기 때문에 필연적으로, Output의 [EOS] Token을 입력 문장의 임베딩으로 활용한다
•
Unsupervised Setting에서는 인터넷에서 수집한 데이터의 인접한 문장들을 Positive Pair로 구축한다
•
Supervised Setting에서는 NLI Dataset의 Contradiction 문장들을 Negative Samples로 추가한다
Experiments & Results
두 논문의 실험 결과를 모두 기록하기에는 양이 방대하여, 서로 비교했을 때 의미가 있는 내용들만을 정리한다.
기본적으로 SimCSE, CPT 모두 다음 2가지 Tasks에서 성능을 평가한다.
•
SentEval Linear Probe Classification
◦
학습한 문장 임베딩으로부터 분류기를 추가 학습하여 감성 분석 등을 수행
◦
문장 임베딩의 퀄리티를 측정하는, 그렇지만 본래 목적과는 약간 다른 Task
•
STS (Sentence Semantic Similarity)
◦
주어진 두 문장의 (내용적) 유사한 정도를 판단
◦
본래 목적과 부합한 Task
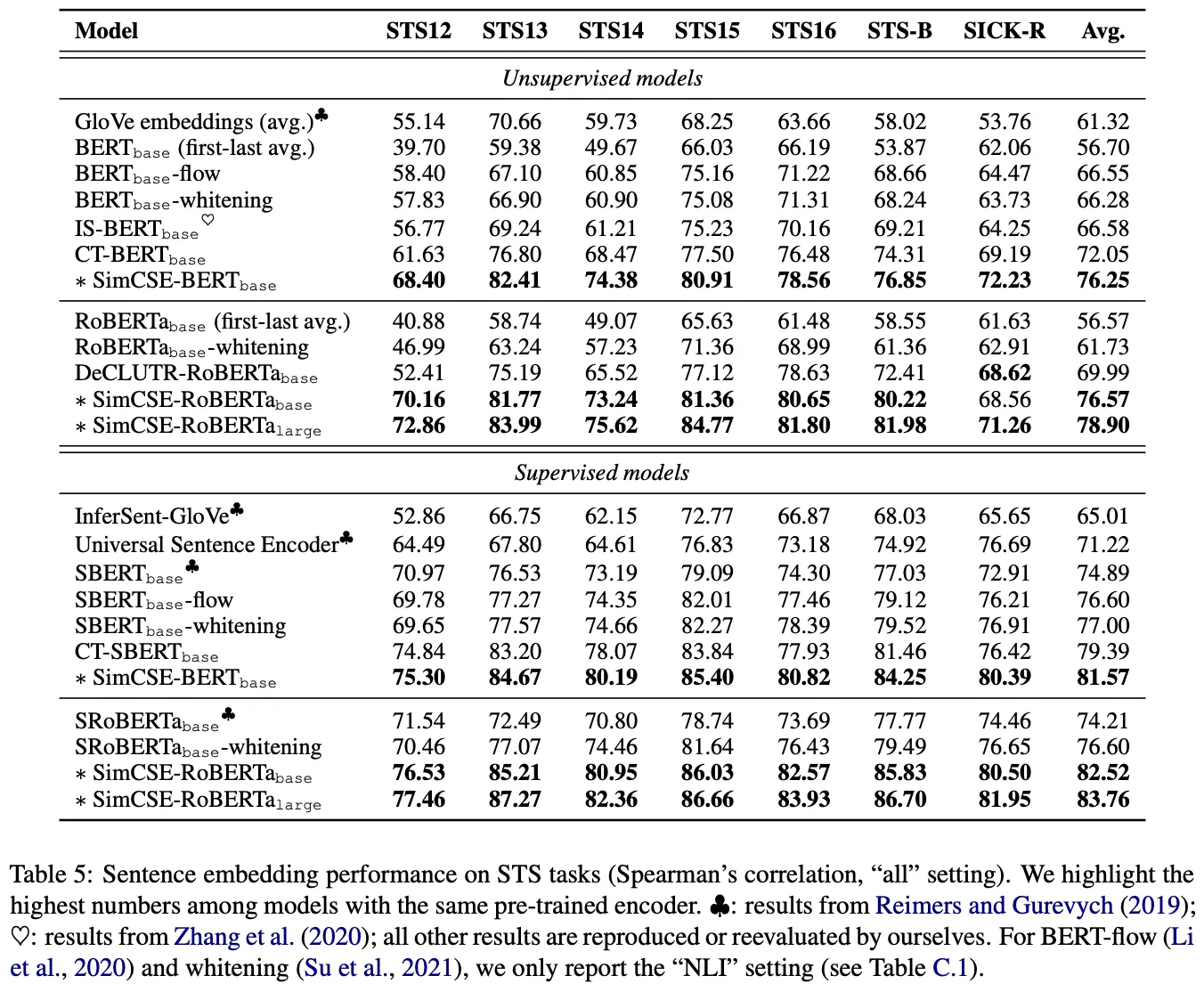
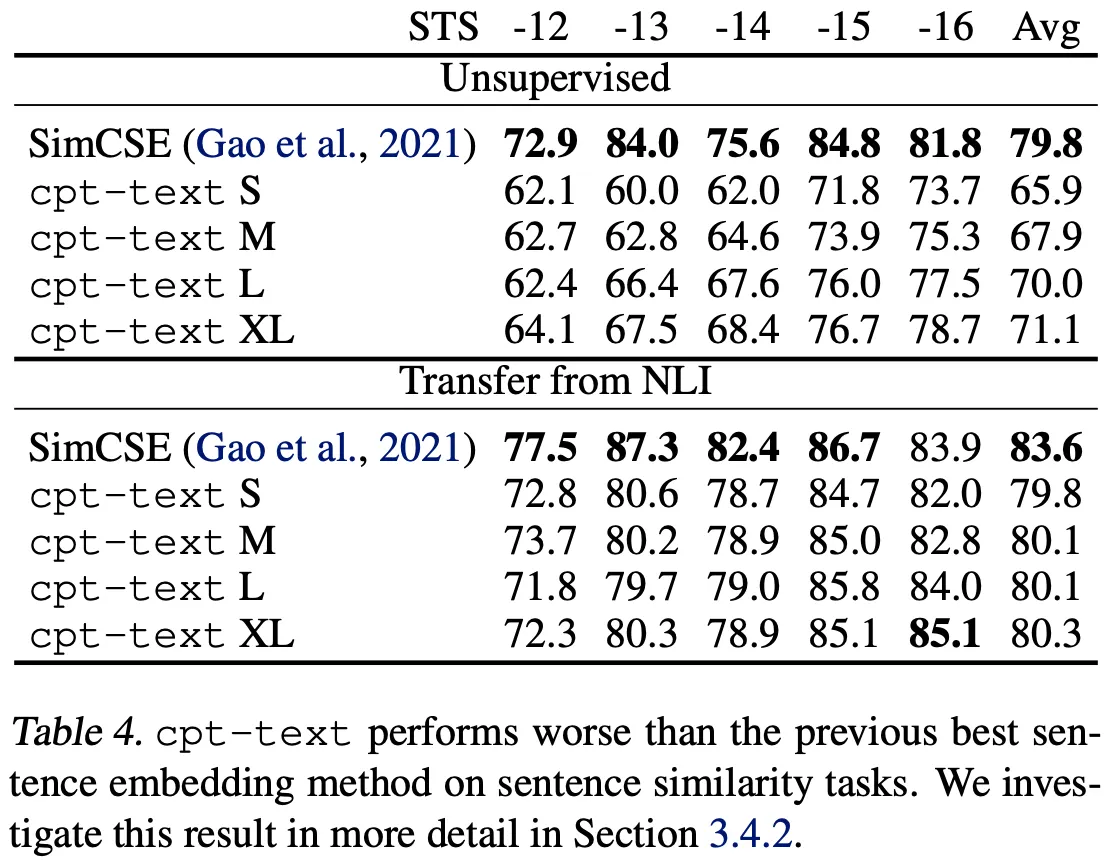
실험 결과, SimCSE는 STS에서, CPT는 SentEval에서 서로를 능가하는 성능을 보인다.
•
(위 그림-상) SimCSE는 STS에서 기존의 모델들에 비해 훨씬 개선된 성능을 보인다
•
(위 그림-하) SimCSE는 심지어 CPT보다도 좋은 성능을 보인다
•
(아래 그림) 반면, SentEval에서는 CPT가 SimCSE와 다른 모델들을 능가한다
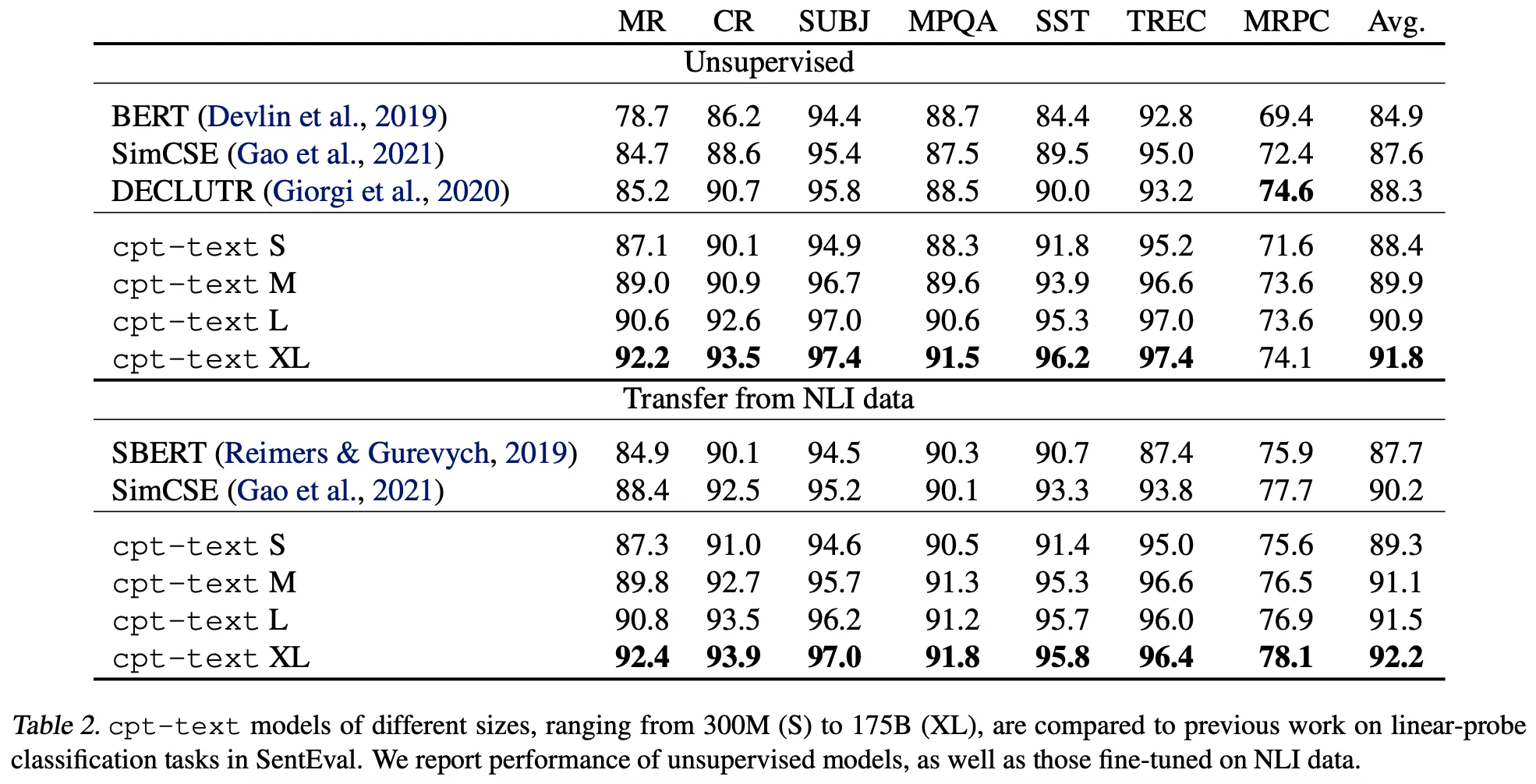
위 실험 결과를 이해하기 위해서 SimCSE와 CPT의 차이를 생각해보면,
•
Batch Size
◦
SimCSE는 64~512
◦
CPT는 천~만 단위의 Large Size
•
Confidence(?) of Positive Pair
◦
SimCSE는 동일한 문장을 2번 포워딩하여 내용적으로 거의 동일
◦
반면, CPT는 인접한 문장으로 구축하기에 연관성이 상대적으로 낮다고 볼 수 있음
SimCSE가 CPT에 비해 작은 Batch에서 상대적으로 연관성이 큰 문장들을 Align하므로, 상세한 Semantic Feature를 더 잘 캐치하는 것이 아닐까..? 생각한다.
추가적으로, CPT의 저자들은 위 실험 결과에 대해 다음과 같이 항변한다.
•
STS는 애초에 불완전한, 현실 서비스와 무관한 Task이다
•
예를 들어, ‘나는 강아지가 좋아’, ‘나는 강아지가 싫어’라는 두 문장은 STS에서 유사하지 않지만, 강아지라는 주제에서 연관(Relevant) 되었다고 볼 수 있으며, 오히려 후자가 현실에서 필요한 Task이다
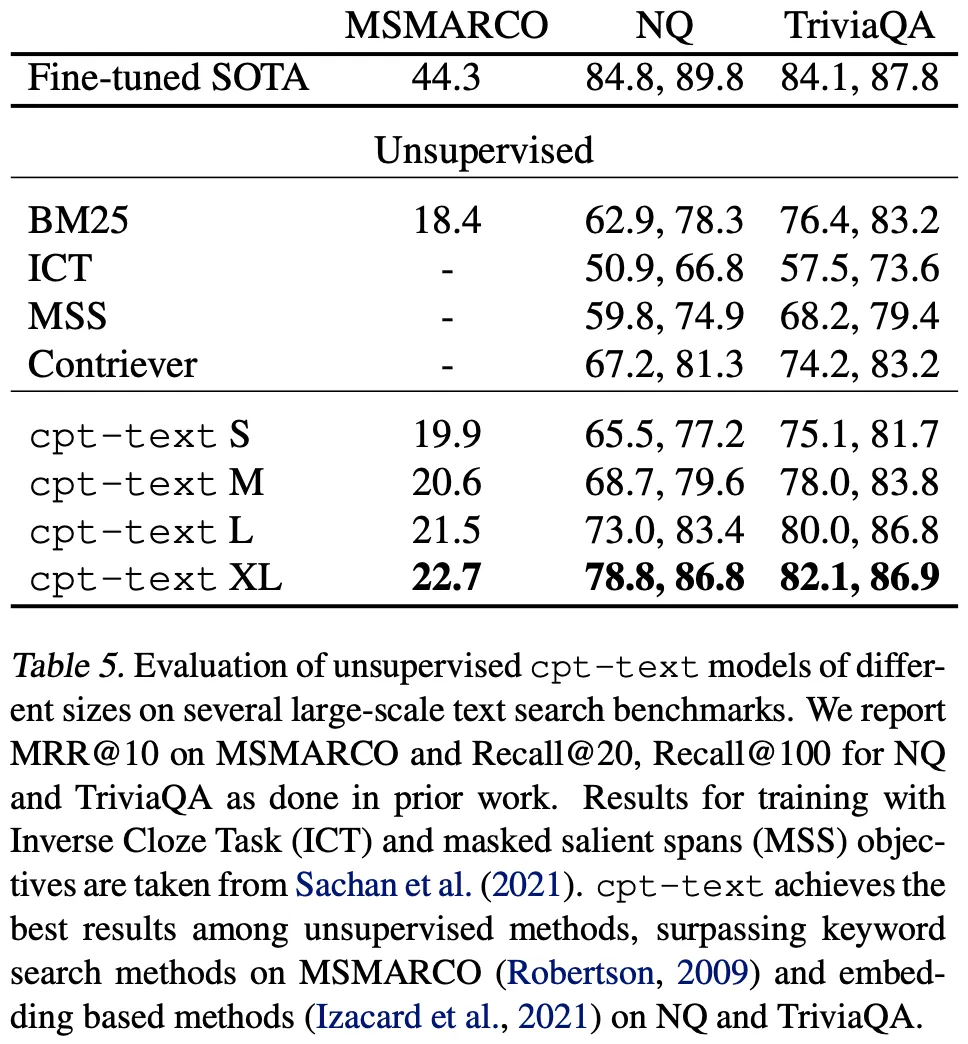
•
실제로 아래 그림에서 CPT가 좋은 Large-Scale Text Search 성능을 보임을 확인할 수 있다
•
결국, CPT가 SimCSE보다 조금 더 큰 주제의 Semantic Feature를 캐치하는 것이라고 본인은 생각한다