
Table-To-Text Generation 관련 연구를 Searching 하던 중 발견한 Paper.
ACL 2021에서 발표된, Prefix-Tuning (Low-Cost Training)을 통한 LMs의 Downstream Tasks 수행이 Key Point인 Research.
Problems: Fine-Tuning
Downstream Tasks 수행을 위해 Pre-Trained LM을 Fine-Tuning 하는 것의 문제점.
•
Large Pre-Trained (대부분의 Recent) LM의 경우 Cost가 비쌈
•
다양한 Tasks의 수행을 위해 그 수만큼 LM을 복사하여 각각 Training시켜야 함
•
GPT-3, CTRL 등은 Input에 Task Instruction, Samples, Attribute Keywords와 같은 Text를 포함시켜 LM이 생성하는 Output을 조절함: Prompting
•
그러나 Prompting은 Fine-Grained Control을 위한 명시적인 방법론이 없음
Proposed Method: Prefix-Tuning
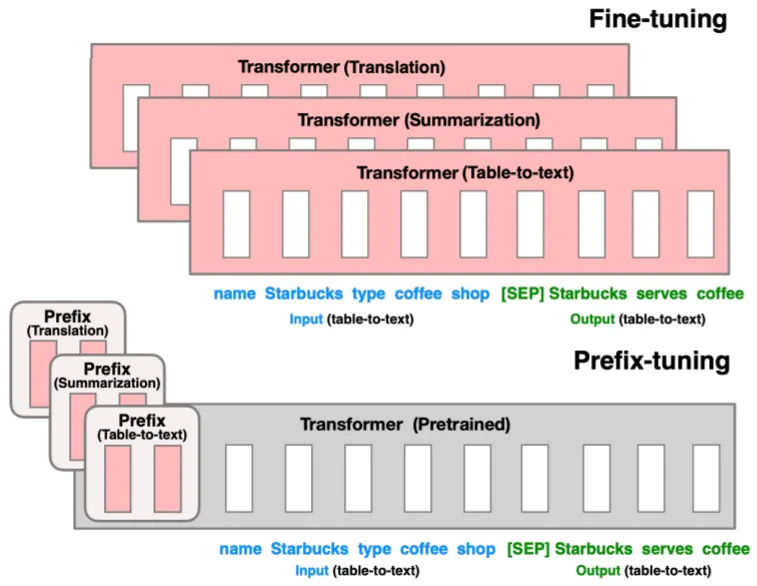
Prefix란 Input에 Prepend되는 일종의 Virtual Tokens로, Task-Specific한 정보를 포함: P_Theta
•
Continuous Vectors Shape: Discrete Prompt에 비해 더욱 Expressive함
•
Fine-Tuning 시에 LM은 Freeze하고, Trainable Prefix만 Update하기 때문에 Cost가 매우 작음
•
서로 다른 Tasks마다 Prefix만 교체함: Modular
•
Prefix를 직접적으로 Update하는 것이 성능 저하를 유발하여 Reparameterization 적용:
P_Theta=MLP(p_Theta), p_Theta: Smaller Matrix
Experiments & Results
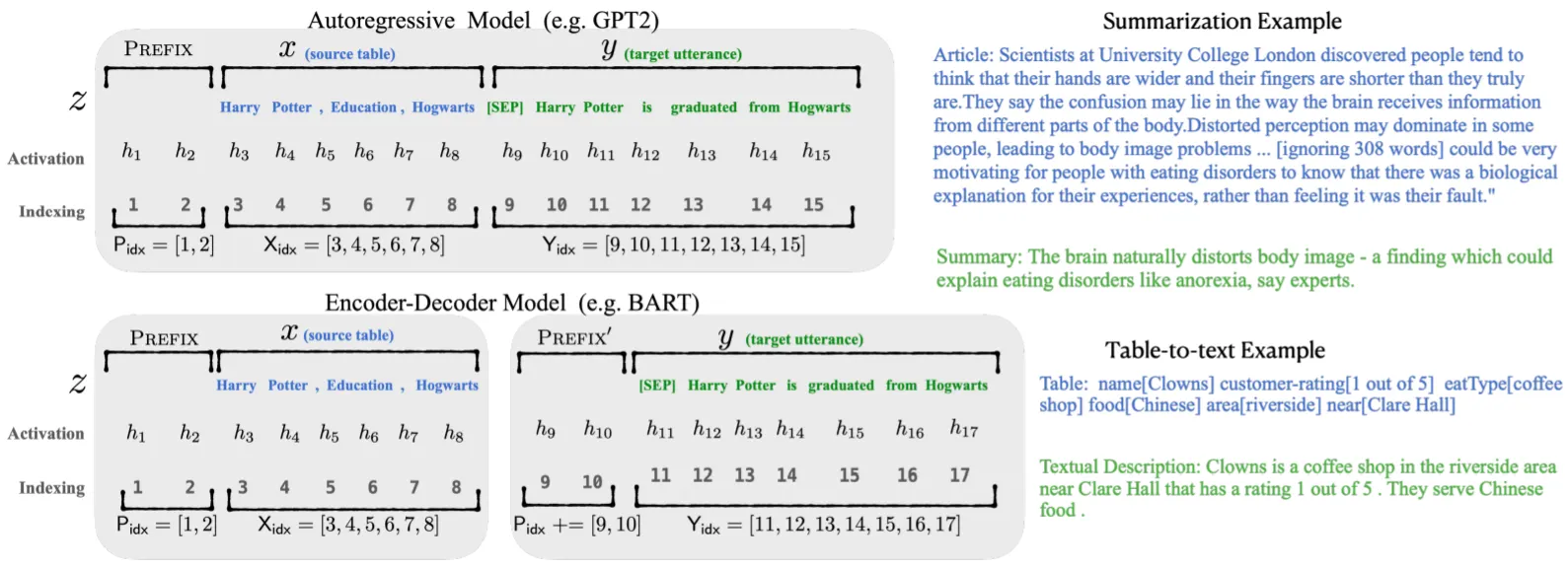
실험은 크게 2종류로, Table-To-Text Generation과 Summarization Task 수행.
Table-To-Text Generation
•
GPT-2 사용
•
E2E, WebNLG, DART Dataset
•
Full & Few-Params Fine-Tuning 기법들과 성능 비교
Summarization
•
BART 사용
•
XSUM Dataset
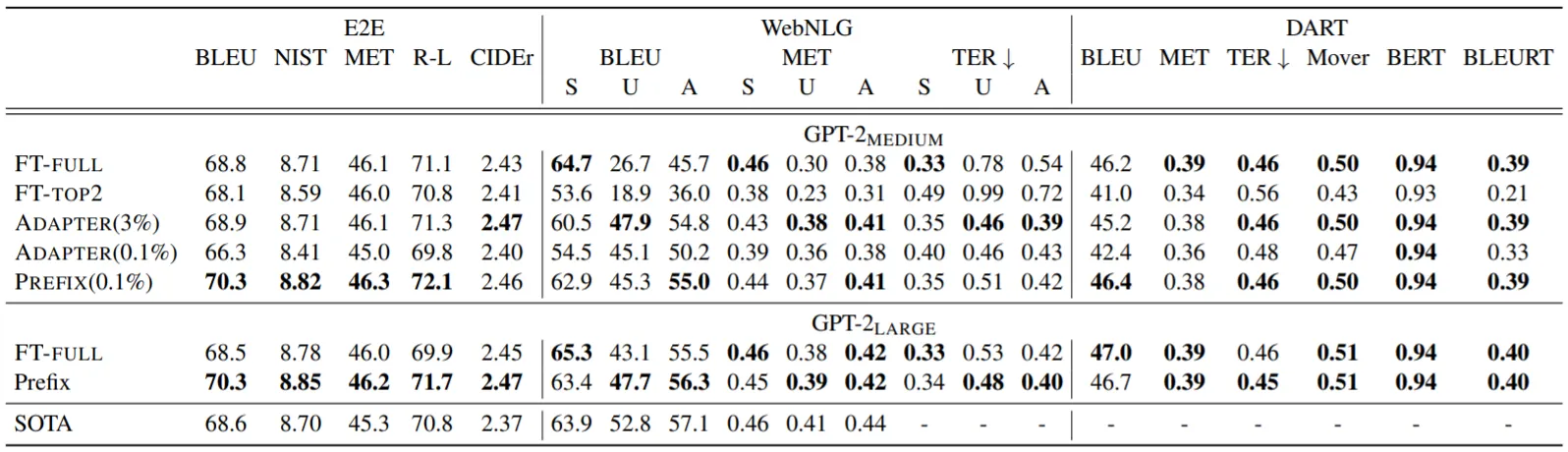
주요 실험 결과를 정리하면,
•
Table-To-Text Generation에서 Prefix-Tuning은 더 많은 Params를 Update한 기법들을 능가하는, Full Fine-Tuning에 준하는 성능을 보임
•
그러나 Summarization에서는 분명한 성능 저하가 발생함. 이는 XSUM Dataset Size가 크고, 내용이 길고 복잡하기 때문이라고 유추
•
실제로 Prefix-Tuning은 Low-Data Setting에서 강점을 보임
•
또한, Out-Of-Domain Data에서도 Solid한 성능을 보임
•
특정 지점까지 Prefix의 Length가 증가할수록 성능도 개선되지만, 이후에는 완만히 저하됨
•
Low-Data Setting에서 Prefix를 Random하게 초기화하기보다는 실제 단어로 설정하는 편이 나음