체력과 멘탈을 완전히 회복하는 데 추가로 1달이 더 걸렸다..
나름대로 많이 관리하는데도 아픈 것 보면 스트레스가 문제인가 페이스 조절을 해야겠다..
이 논문은 Long-Context Language Modeling을 위해 External Memory를 활용하는 방법을 제안한다.
External Memory라고 해서 Graves 형님의 Neural Turing Machine이 떠올랐지만 크게 상관은 없었고, Longformer나 Big Bird 이외에 이런 방법도 있구나 하면서 재미있게 읽었다!
나름대로 많이 관리하는데도 아픈 것 보면 스트레스가 문제인가 페이스 조절을 해야겠다..
이 논문은 Long-Context Language Modeling을 위해 External Memory를 활용하는 방법을 제안한다.
External Memory라고 해서 Graves 형님의 Neural Turing Machine이 떠올랐지만 크게 상관은 없었고, Longformer나 Big Bird 이외에 이런 방법도 있구나 하면서 재미있게 읽었다!Abstract
결론부터 말하면, 논문에서 하고자 하는 것은 Attention 연산을 통해 참조할 수 있는 External Memory에 Context 정보 (Key, Value)를 저장하고, 이를 Long-Context Language Modeling에 활용하여 성능을 높이는 것이다.
하나씩 살펴보면,
•
Long-Context Language Modeling
◦
Transformer는 일반적으로 좋은 성능을 보이지만 (지금은 바야흐로 Transformer의 시대), Quadratic (n^2)한 연산량 및 메모리 사용량으로 인해 Input Context Length가 제한(512)되어 있다.
◦
이는 프로그래밍 코드 (Like Copilot), 논문 등에서 Language Modeling을 수행할 때 문제가 된다.
◦
예를 들어, 우리는 코딩을 할 때 함수의 선언 및 정의를 코드의 맨 위 혹은 다른 코드에 한 후, 코드의 제일 아래 main 함수에서 주로 사용한다. 논문에서는 여러 수식들이 정의되고, 추후 수식들은 이전 수식들을 참조하여 증명을 수행한다.
◦
이렇듯 Attention 연산에서 Attend할 정보가 Context에서 멀리 떨어져 있을 때, 현재의 제한된 Input Length의 Transformer는 해당 정보를 참조할 수 없는 상황을 마주하며, 이는 성능의 저하로 이어진다.
◦
Longformer, Big Bird 등은 일종의 Pruning된 Attention 연산으로 Input Length를 증가시키지만, 그 길이는 4,096 정도이며 이전의 모든 Context 정보를 Attend 하지 않기에 궁극적인 해결책이 될까 하는 생각이 들게 한다.
•
External Memory
◦
논문에서는 모델의 Weights가 메모리로서의 역할을 일부 수행할 수 있지만 (GPT-3와 같은 거대 모델이 General한 Knowledge를 내포하는 등), 이는 오랜 학습 Step에 걸쳐 서서히 쓰이고 지워진다는 점을 지적한다.
◦
사실, Inference에서는 애초에 Weights Update가 발생하지 않기에 이를 메모리로 사용하는 것 자체가 불가능하다. 개인적으로 위 논리를 굳이 쓸 필요가 있었을까 하는 생각을 하지만, Attention 연산을 통해 참조할 수 있는 External Memory의 장점을 부각시키는 목적이라면 충분히 이해할 수 있다.
개인적으로 External Memory에 대한 이해를 위해 관련 연구들을 찾아볼 필요가 있었다.
Related Works
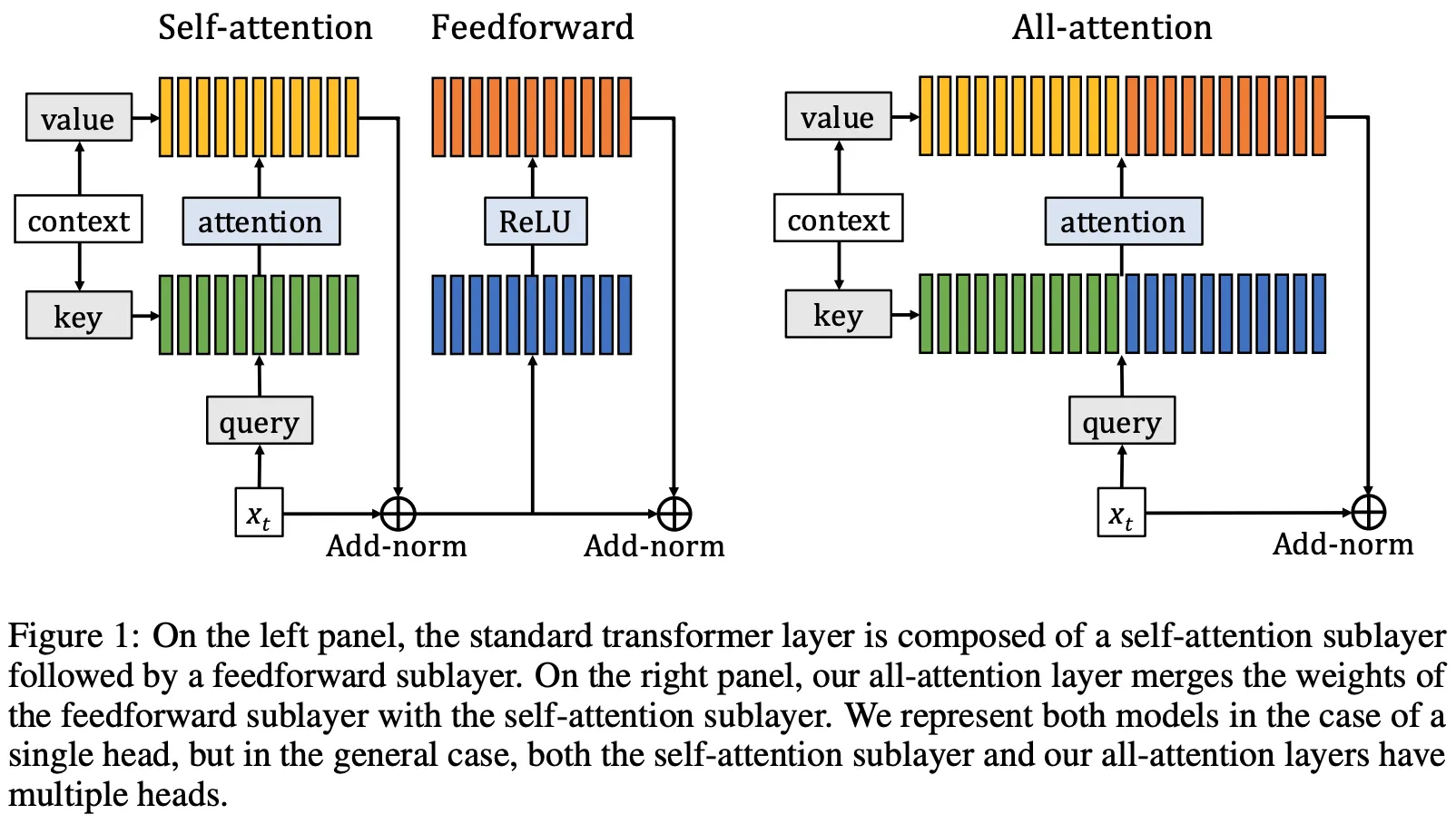
Sukhbaatar et al.은 Feed-Forward Network의 ReLU Activation을 Softmax로 치환하여, 이를 Attention 연산의 형태로 만들었다. (FFN의 두 Layer를 Key^T, Value 형태로 생각한 것)
FFN의 Weights는 Input Context에 무관하기 때문에 일종의 ‘메모리’로 생각할 수 있다.
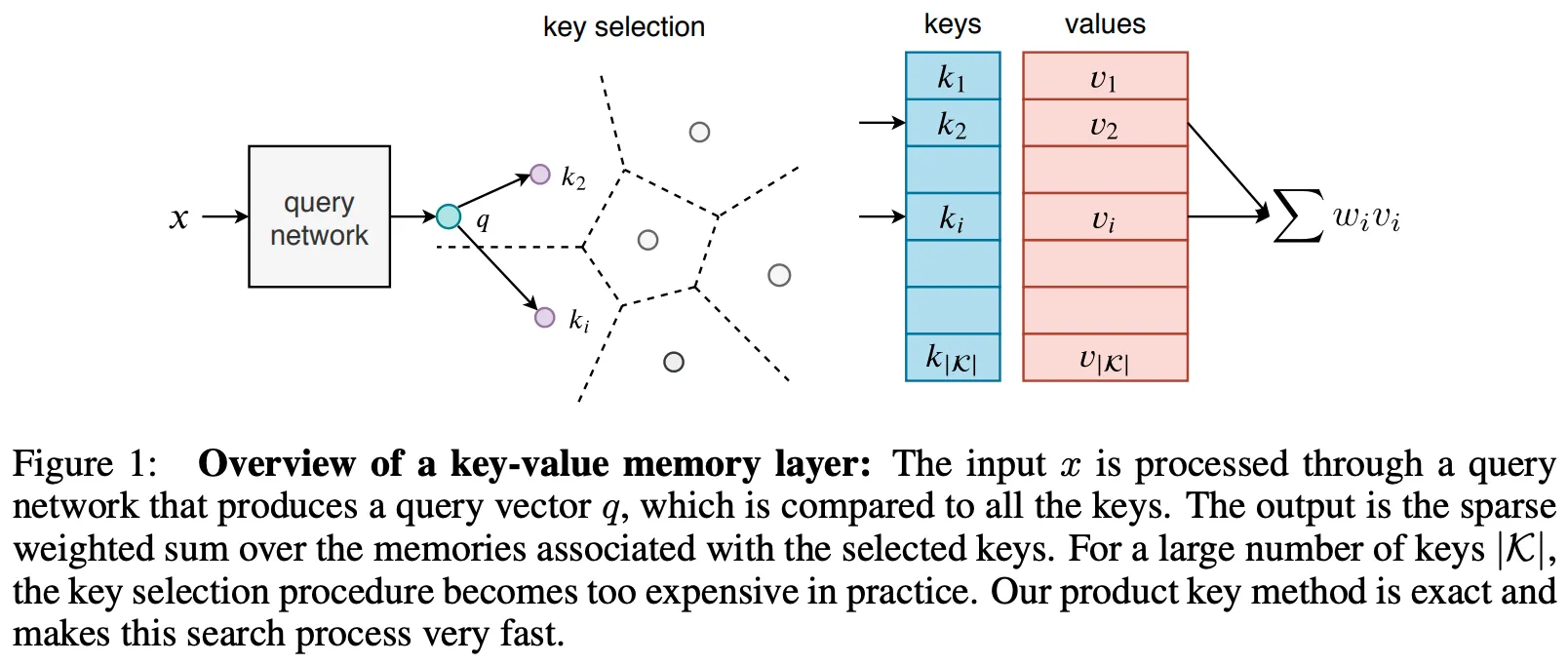
Lample et al. 역시 FFN를 Attention 연산이 가능한 Key, Value 형태의 메모리로 취급하였으며, Key-Value Lookup Table을 구축한 후, Input Query와의 KNN 연산을 통해 얻은 Top-K 개의 유사한 Key-Value Sets를 FFN의 Weights로 사용하는 방식을 도입하였다.
Key-Value 조합의 수는 무한정 증가할 수 있으나, Back Prop 과정에서는 K개의 Key-Value만을 Update 하기 때문에 추가적인 연산이 발생하지 않으면서 Large Weights를 활용하는 효과를 낼 수 있다.
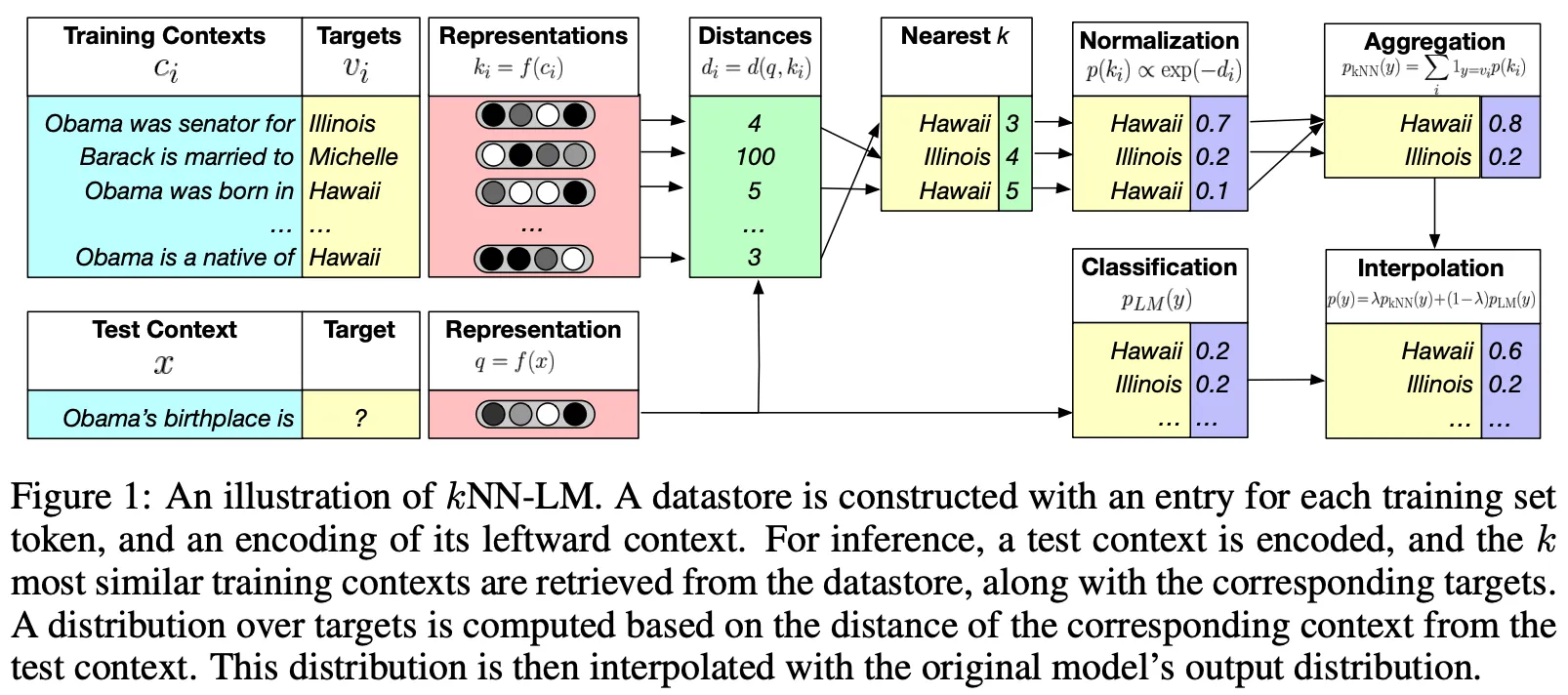
Khandelwal et al.은 LM의 Pre-Training에서 Non-Differentiable KNN Lookup을 구축한 후, Language Modeling (Next Token Prediction)에서 이를 활용하였다.
Proposed Model: Memorizing Transformers
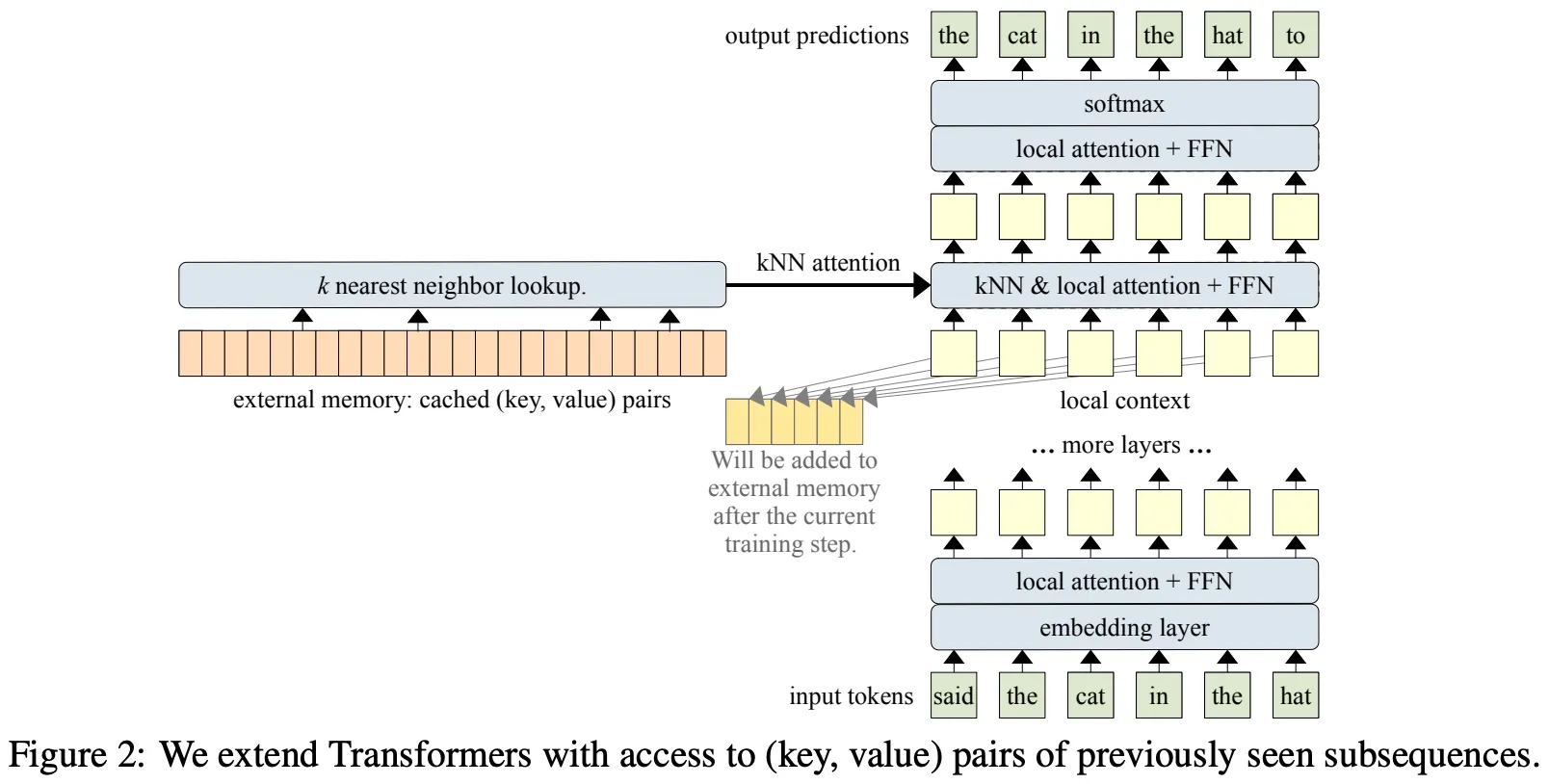
제안 모델의 특징을 살펴보면,
•
External Memory를 활용하지만, FFN를 치환하는 방식은 아님
•
Decoder-Only Transformer로, Transformer-XL 스타일의 Cache를 사용
•
Context의 Key, Value를 별도의 변형 (Linear Projection 등) 없이 그대로 External Memory에 저장
◦
Key, Value가 Memory에 저장되는 방식은 선입선출 (FIFO)로, 최근 M(Memory Size)개의 Context 정보를 저장하고 있음
◦
Non-Differentiable하기 때문에 Memory Size를 매우 크게 설정할 수 있음 (Scalability)
◦
단, Memory Size가 클 경우, 학습 과정에서 앞 & 뒷부분의 Key, Value Distribution이 달라질 가능성이 있음 (Weights가 계속해서 Update 되기 때문) → 이를 위해 Normalization 수행
•
Input Query와 KNN 연산을 통해 External Memory에서 참조할 Key, Value를 검색
◦
Transformer 중간 Layer (실험에서는 9번째 Layer)에서 내부 Self-Attention과 External Memory와의 Self-Attention을 결합
◦
내부 & 외부 Attention 조합 비율을 결정하는 Learnable Scalar Parameter가 존재하며, Head 별로 학습이 수행됨
◦
일반적인 Self-Attention과 다르게 Query Token별로 Attend하는 Key, Value가 달라짐
•
T5의 Relative Position Embedding을 사용하며, External Memory에는 이를 적용하지 않음
•
아래 그림과 같은 Batching을 사용

◦
동일한 문서의 Subsequences가 이어지지 않는데 왜 Transformer-XL Cache를 사용했을까?!
Experiments & Results
실험에 사용한 데이터는 Long-Context를 갖는, External Memory의 장점을 활용할 수 있는 Corpus들로 구성된다.
•
arXiv Math
•
Github
•
Formal Math (Isabelle)
•
C4 (Filtered)
•
PG-19
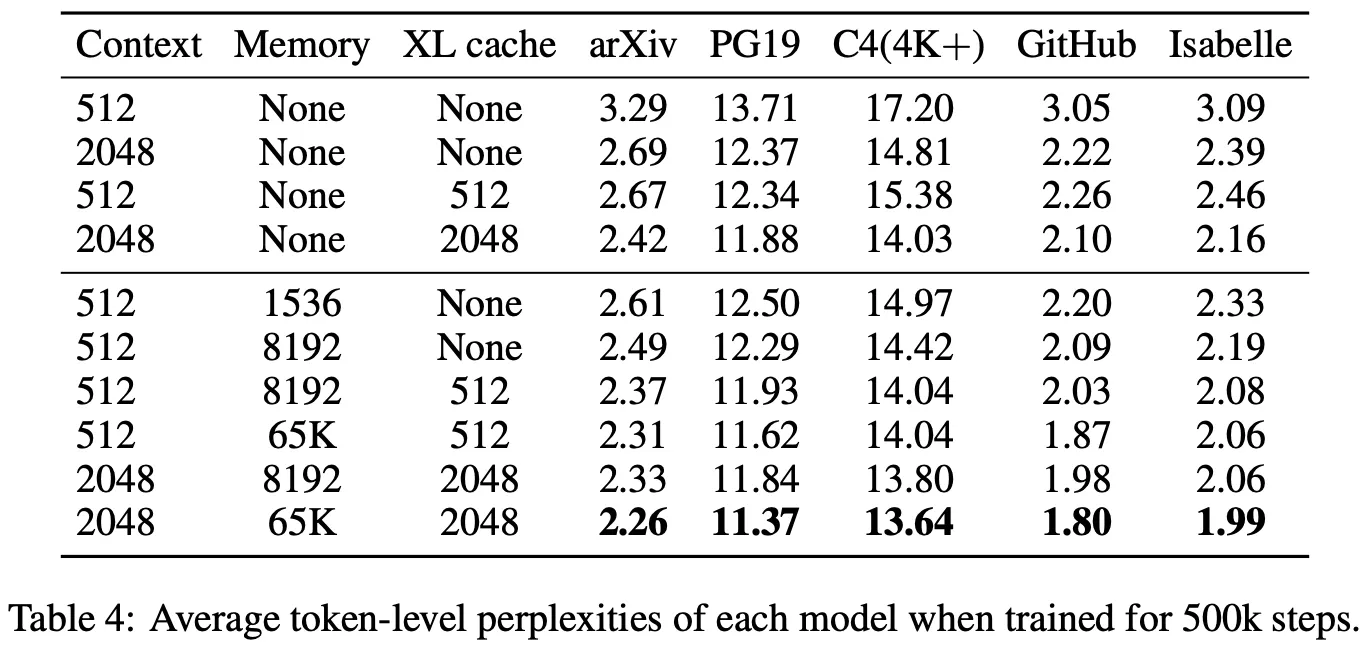
실험 결과는 매우 자명하고, 다양한 Setting에서 성능이 Consistent하게 향상되기 때문에 간략히만 설명한다.
•
데이터셋과 모델의 구조와 상관없이 External Memory를 활용하면 성능이 향상된다.
•
Memory Size가 증가하는 만큼 성능이 추가 향상된다.
•
모델의 크기가 증가하여도 External Memory의 효과는 유지되며, 모델 크기에 비해 성능 향상 효율이 좋다.
•
Pre-Training 시에 작은 Memory Size를 설정한 후, Fine-Tuning 시 Size를 증가시켜도 성능이 향상된다.
◦
아예 External Memory 없이 Pre-Trained 된 모델도 Fine-Tuning 시 성능이 향상된다.
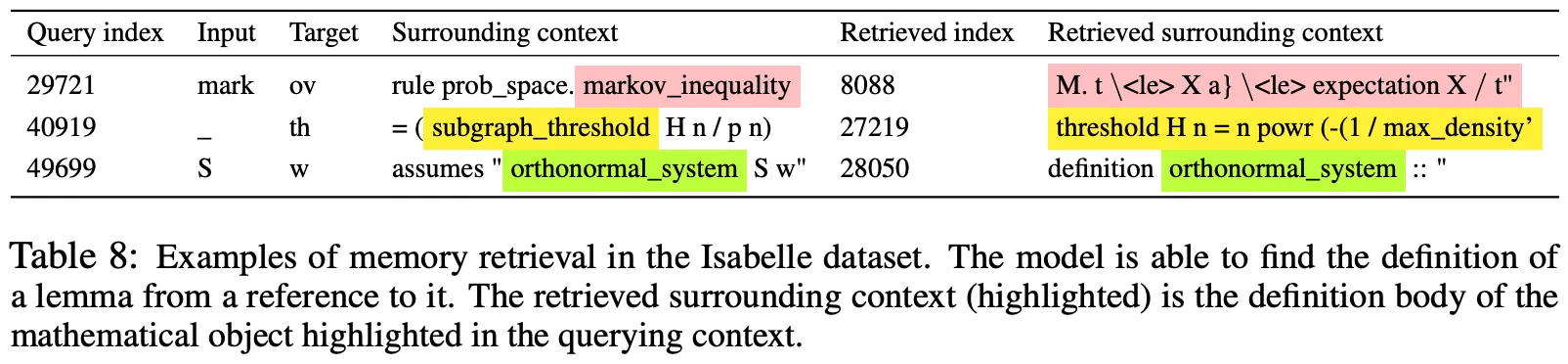
•
아래 그림 (실제 Case)에서 Input Query에 연관된 Context를 External Memory로부터 참조하는 모습을 확인할 수 있다.