
[DetectGPT 논문 리뷰]
AI가 생성한 글을 탐지하는 Stanford의 Zero-Shot Machine-Generated Text Detection 기법
최근, ChatGPT를 비롯한 Instruction-Following 모델 사용의 보편화
→ AI 생성 검출에 대한 수요 증가.. 과연 성능은?
Introduction
•
ChatGPT를 활용한 간단한 코드, 문서 작성.. Instruction-Following 모델의 등장으로 업무 효율성 증진
•
그러나, 일부 분야 (ex. 교육 현장 등)에서는 무분별한 ChatGPT 사용이 문제가 됨
→ AI가 생성한 글을 탐지하는.. Machine-Generated Text Detection 기술의 필요성!
•
기존의 Detection 기법: Binary Classification vs Zero-Shot 존재
•
Binary Classification
◦
사람이 작성한 글/AI가 생성한 글을 분류하는 Binary Classifier 학습
▪
Bag-of-Words+Logistic Regression, Fine-Tuned RoBERTa 등 존재
◦
학습에 활용하는 데이터셋 (특정 Target LM 검출)에 과적합 (Overfitting)되는 문제 발생
▪
ex. ChatGPT를 검출하는 Classifier를 Bing Chat 검출에 사용할 수 없음
◦
기존 방법론들에 관한 Survey 논문들

•
Zero-Shot
◦
Key Idea: AI가 생성한 글은 LM이 생성할 확률이 높은 Token들로 구성될 것
◦
검사하는 문장의 각 Token을 Target LM이 생성하는 확률 (Log Probability) 활용
Detection 예시
◦
Binary Classifier의 과적합 문제 해결
◦
대표적인 방법론으로 GLTR 존재 → Visualization Tool (웹 사이트) 제공

▪
Target LM이 해당 Token을 생성하는 확률 (Probability), 순위 (Rank) & Target LM의 Token 생성 확률 분포의 Entropy 값 활용
▪
검사하는 문장을 구성하는 Token들의 생성 확률, 생성 순위가 높을수록 & Entropy 값이 낮을수록 AI가 생성한 Text일 가능성이 높음
Tool 사용 예시
▪
전반적으로 좋은 성능을 보이지만, 개별 Token (좁은) 단위에서 Detection을 수행하는 한계 존재
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
•
본 논문은 주어진 문장을 개별 Token이 아닌, 전체 문장 (더 넓은) 단위에서 분석하는 DetectGPT라는 Detection 기법을 제안
•
Key Idea: AI가 생성한 문장은 높은 Log Probability 값을 가질 것이므로, 해당 문장의 일부분을 수정하여 얻은 문장은 상대적으로 작은 Log Probability 값을 가질 것이다
→ 반면, 사람이 작성한 글은 (Target LM 입장에서) 높은 Log Probability 값을 갖는 것이 보장되지 않기 때문에, 문장 일부분을 수정하여도 Log Probability 값이 오를 수도 or 내릴 수도 있을 것이다 (아래 그림 참조)
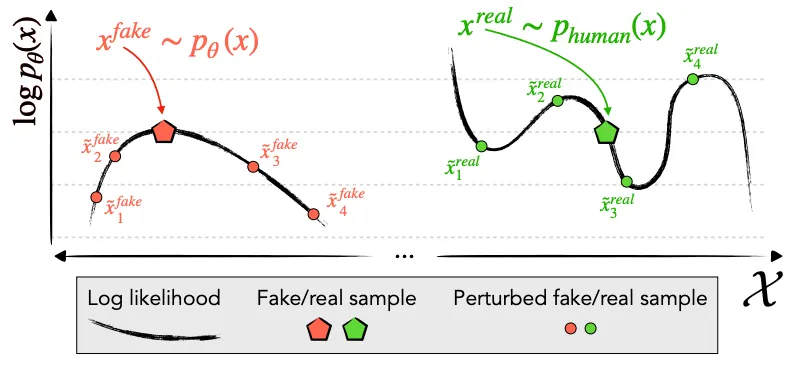
Proposed Method

1.
주어진 문장의 일부분을 수정한 변형 문장을 n개 생성한다
•
이 때, T5와 같은 별도의 LM을 사용하여 일부 단어들을 변경하는 방식을 활용
•
ex. 나는 달콤한 초콜릿 아이스크림이 좋아 → 나는 달달한 초콜릿 아이스크림이 좋아
2.
변형 문장 n개와 원본 문장과의 (Target LM 입장에서) Log Probability 값 차이를 계산한다
ex. (주어진 문장이 AI로부터 생성되었을 경우)
원본 문장 | 변형 문장1 | 변형 문장2 | 변형 문장3 | 변형 문장4 | 변형 문장5 | |
Log Prob | 0.8 | 0.65 | 0.6 | 0.85 | 0.7 | 0.65 |
Diff | - | 0.15 | 0.2 | -0.05 | 0.1 | 0.15 |
(주어진 문장이 사람으로부터 작성되었을 경우)
원본 문장 | 변형 문장1 | 변형 문장2 | 변형 문장3 | 변형 문장4 | 변형 문장5 | |
Log Prob | 0.8 | 0.85 | 0.7 | 0.65 | 0.9 | 0.85 |
Diff | - | -0.05 | 0.1 | 0.15 | -0.1 | -0.05 |
3.
위에서 구한 Log Probability 차이 값 n개의 평균, 표준편차를 계산한다
ex. (주어진 문장이 AI로부터 생성되었을 경우) 평균 0.11, 표준편차 0.009
(주어진 문장이 사람으로부터 작성되었을 경우) 평균 0.01, 표준편차 0.012
4.
평균/표준편차 값이 일정 수준 (Hyperparam, Threshold) 이상일 경우 AI (Target LM) 생성으로, 이하일 경우 사람 작성으로 판단한다
ex. (주어진 문장이 AI로부터 생성되었을 경우) 12.22, (주어진 문장이 사람으로부터 작성되었을 경우) 0.83
•
AI가 생성한 문장의 경우, 원본 문장과 변형 문장들 간의 Log Probability 값 차이가 대부분 양수이므로, 상대적으로 큰 평균 값, 작은 표준편차 값을 가짐
•
반면, 사람이 작성한 문장은 음수~양수의 차이 값을 가지므로, 상대적으로 작은 평균 값, 큰 표준편차 값을 가짐
Experiments & Results
•
실험에서는 XSum, SQuAD, Reddit WritingPrompts, WMT16, PubMedQA 5개의 Human-Written 데이터셋 사용
◦
데이터의 앞 부분 (30 Tokens)을 Prompt로 활용하여 Machine-Generated Text 생성
•
생성에 사용하는 (제안 기법이 검출해야 하는, Target) 모델로는 1.5B~20B 크기의 LM 선정
◦
GPT-2, OPT-2.7, Neo-2.7, GPT-J, NeoX 등
•
변형 문장을 생성하는 모델로는 T5-3B (큰 Target LM 검출에는 T5-11B) 채택
•
제안 기법 or Baseline 기법들의 성능 측정에는 AUROC 지표 사용
(실험 결과는 유의미한 것들 위주로 기록)
•
Target LM의 크기, 데이터셋에 관계 없이 DetectGPT가 기존의 Zero-Shot 방법론들에 비해 좋은 성능을 보임
•
Target LM의 크기가 작을 때에는 DetectGPT가 Fine-Tuned RoBERTa에 준하는 성능을 보이지만, 175B GPT-3를 Target LM으로 사용했을 때에는 좋지 못한 성능을 보임
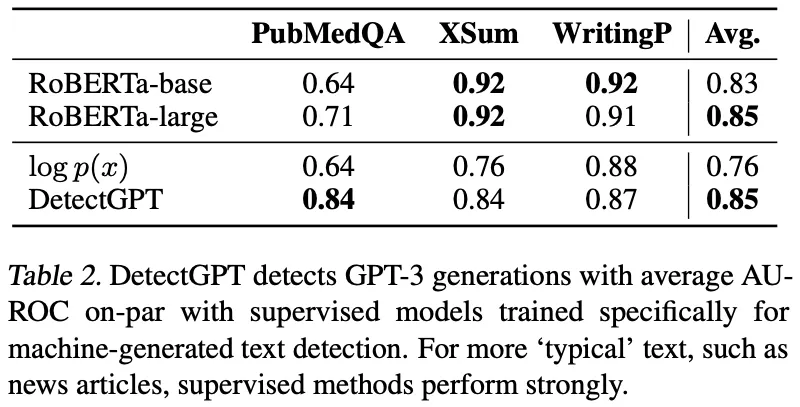
◦
Fine-Tuned RoBERTa는 General Dataset을 학습했기 때문에 PubMedQA에서는 성능이 필연적으로 감소
◦
Real-World Application에는 아직 Binary Classifier가 적합할 수도..
•
Target LM이 생성한 문장을 편집할수록 검출 성능이 감소함
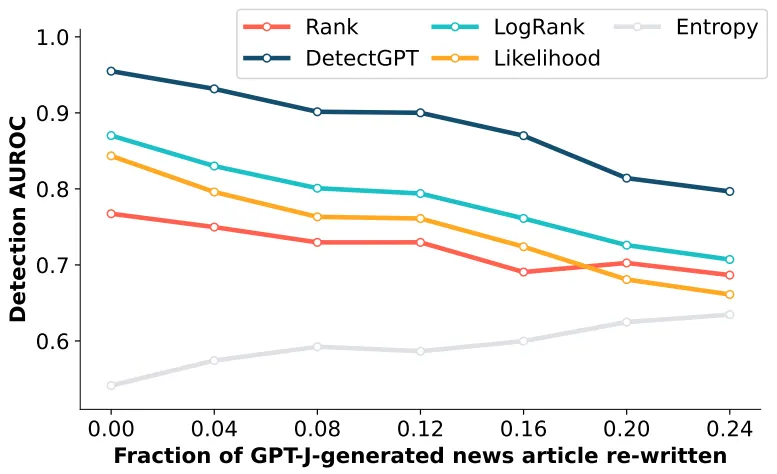
◦
대부분의 사람들이 AI가 작성한 글을 그대로 사용하지는 않을 테니.. → Real-World Application에서 고려할 점
•
DetectGPT는 기본적으로 Token/문장의 Log Probability를 필요로 함
◦
Target LM의 Parameter에 접근 가능하거나 or API를 사용할 경우 Log Prob 값을 반환받을 수 있는 환경 (White-Box Setting)에서만 활용 가능
◦
그렇지 않은 환경 (Black-Box Setting)에서는 Target LM을 대체할 다른 LM들을 Ensemble하여 활용할 수 있음