
Web Search API와 GPT-3를 활용하여 Open-Domain 질의응답을 수행하는 OpenAI의 Research.
Behavioral Cloning을 통해 모델이 사람처럼 검색, 스크롤, 클릭 등을 수행하도록 함.
정말 흥미롭게 리뷰한, OpenAI스러운 Paper!
논문에서 중점적으로 다루는 문제는 Long-Form Question-Answering (LFQA)이다.
LFQA란 Open-Domain 질문에 단락 (Paragraph) 수준의 긴 답변을 생성하는 Task로, 질문에 대한 정답을 포함하는 문서를 검색 (Retrieval)하고 이로부터 답변을 생성 (Synthesis)하는 과정으로 구성된다.
(본인은 챗봇과 상당히 유사한 Task 혹은 System이라고 생각한다.)
논문은 현실에서 이미 훌륭한 성능을 보이는 Web Search API (Microsoft-OpenAI답게 Bing API )를 통해 검색을 수행하고, 본인들의 모델인 GPT-3로 생성을 수행한다.
)를 통해 검색을 수행하고, 본인들의 모델인 GPT-3로 생성을 수행한다.Key Point는 Imitation Learning을 통해 GPT-3가 사람이 Web Browser에서 검색, 스크롤, (링크) 클릭 등을 수행하는 것을 그대로 재현할 수 있도록 학습시키는 점이다.
아래 그림은 GPT-3 입장에서 보는 Web Browser 형식 (Input Text) 및 수행할 수 있는 Command 목록이다.
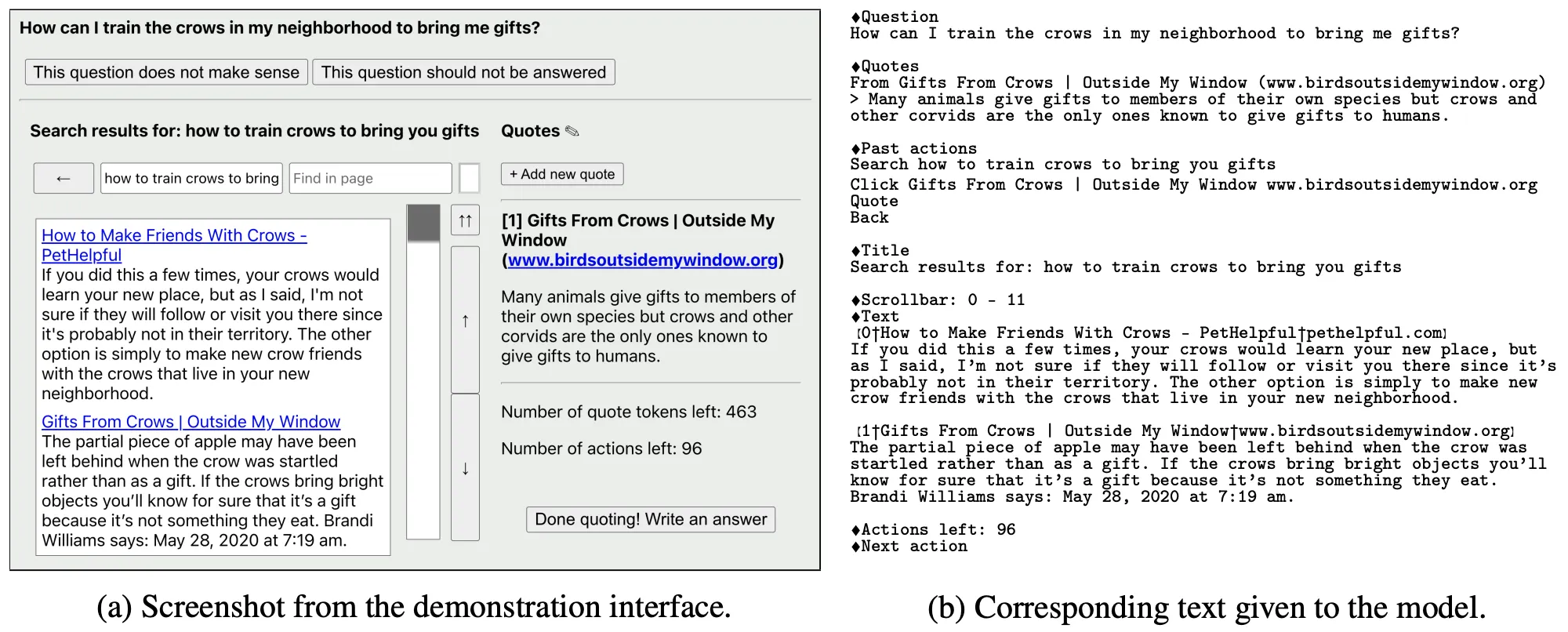

학습을 위해 수집하는 데이터는 다음과 같이 2종류가 존재한다.
•
Demonstrations: 질문에 답변을 하기 위해 사람이 Web Browser에서 검색을 수행하는 일련의 과정들
•
Comparisons: 동일한 질문에 모델이 생성한 답변들 중 사람이 더 선호하는 것을 고른 결과
GPT-3는 기본적으로 Demonstrations+Behavioral Cloning을 통해 학습된다. (BC)
BC 모델을 Comparisons로 학습시켜 Reward Modeling을 수행하도록 하고 (RM), RM 모델을 활용하여 강화학습을 추가로 수행하기도 한다 (RL).
BC 혹은 RL 모델이 생성 (Sampling)한 답변들은 RM 모델이 가장 높은 점수를 부여한 것을 제외하고 버려진다. (이상 Rejection Sampling)
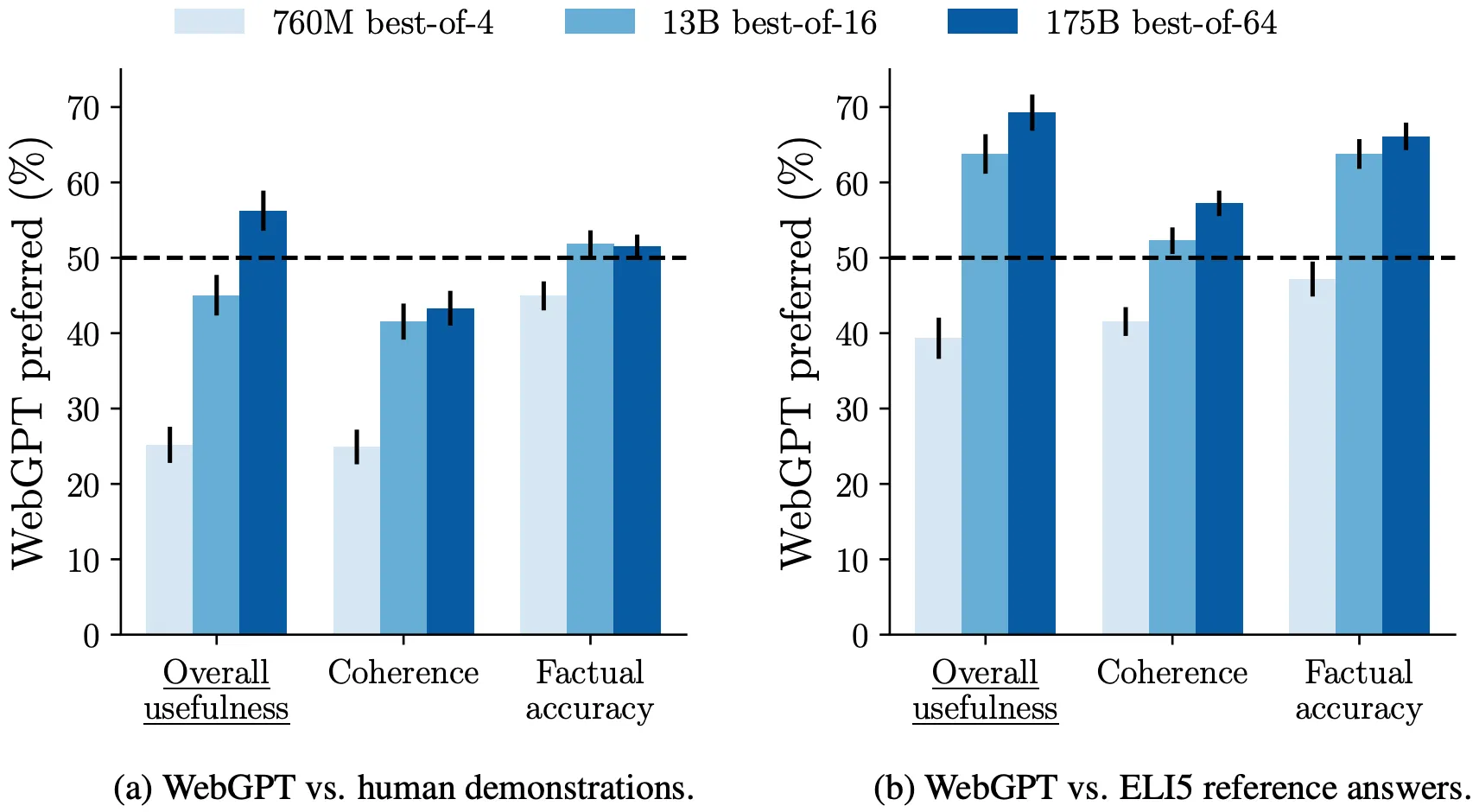
실험 결과, 제안 모델이 ELI5 Dataset에서 사람과 비슷한 (선호도 50% 남짓) 성능을 보이며 (위 그림),
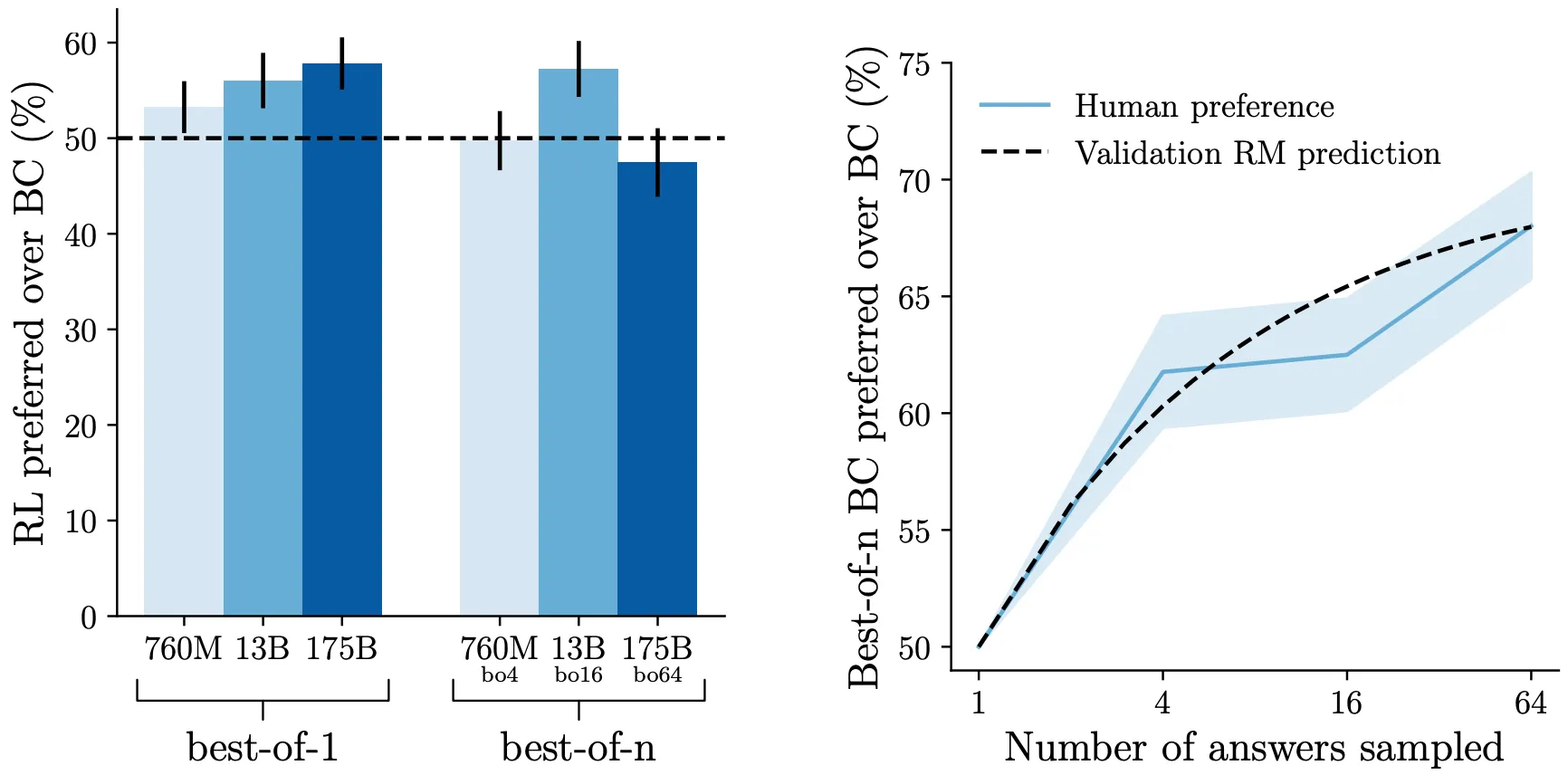
RL 모델이 BC 모델+Rejection Sampling에 비해 큰 성능 향상을 갖지 못함을 알 수 있다 (아래 그림).
RL에 비해 Rejection Sampling은 추가 학습이 필요하지 않다는 장점이 있지만, Inference에서 더 많은 Computations를 발생시킨다. 또한, Sampling하는 답변의 수에 비례하여 성능이 향상된다.