
Trained LM을 활용한 Zero-Shot Semantic Segmentation Research.
NLP가 아닌 Vision 등의 분야도 공부하려 하였으나, 게으른 탓에 잘 되지 않음..
연관된 분야부터 조금씩 공부해 나갈 예정!
Semantic Segmentation

Semantic Segmentation은 특정 이미지를 주어진 Labels에 해당하는 영역들로 구분하는 Task이다.
Task의 특성상 모든 Pixel들에 Labeling이 요구되고, Label의 수(종류)가 많을수록 Annotator의 작업 난이도가 심화되기 때문에 Label Set의 크기를 키우는 데에 한계가 있다.
이를 해결하기 위해 Zero/Few-Shot 기법들이 연구되어왔으나 몇 가지 문제점들이 존재한다.
•
일단 함께 묶기는 했지만, Few-Shot은 적어도 1개 이상의 Labeled Data가 필요하다는 점에서 Zero-Shot에 비해 편의성이 매우 떨어진다.
•
Zero-Shot은 주로 Labels의 Word Embedding으로부터 도움을 받지만, 아직까지 Word2Vec 수준의 Embedding만을 사용했다.
본 논문은 CLIP의 Text Encoder와 같은 Modern LM과 Contrastive Learning을 차용하여, Pixel과 해당 Label의 Embedding을 Align하는 Zero-Shot Semantic Segmentation 기법, LSeg를 제안한다.
위 그림은 실제 LSeg의 수행 결과로, 붉은 글씨가 Unseen Labels을 나타낸다.
Proposed Model: LSeg
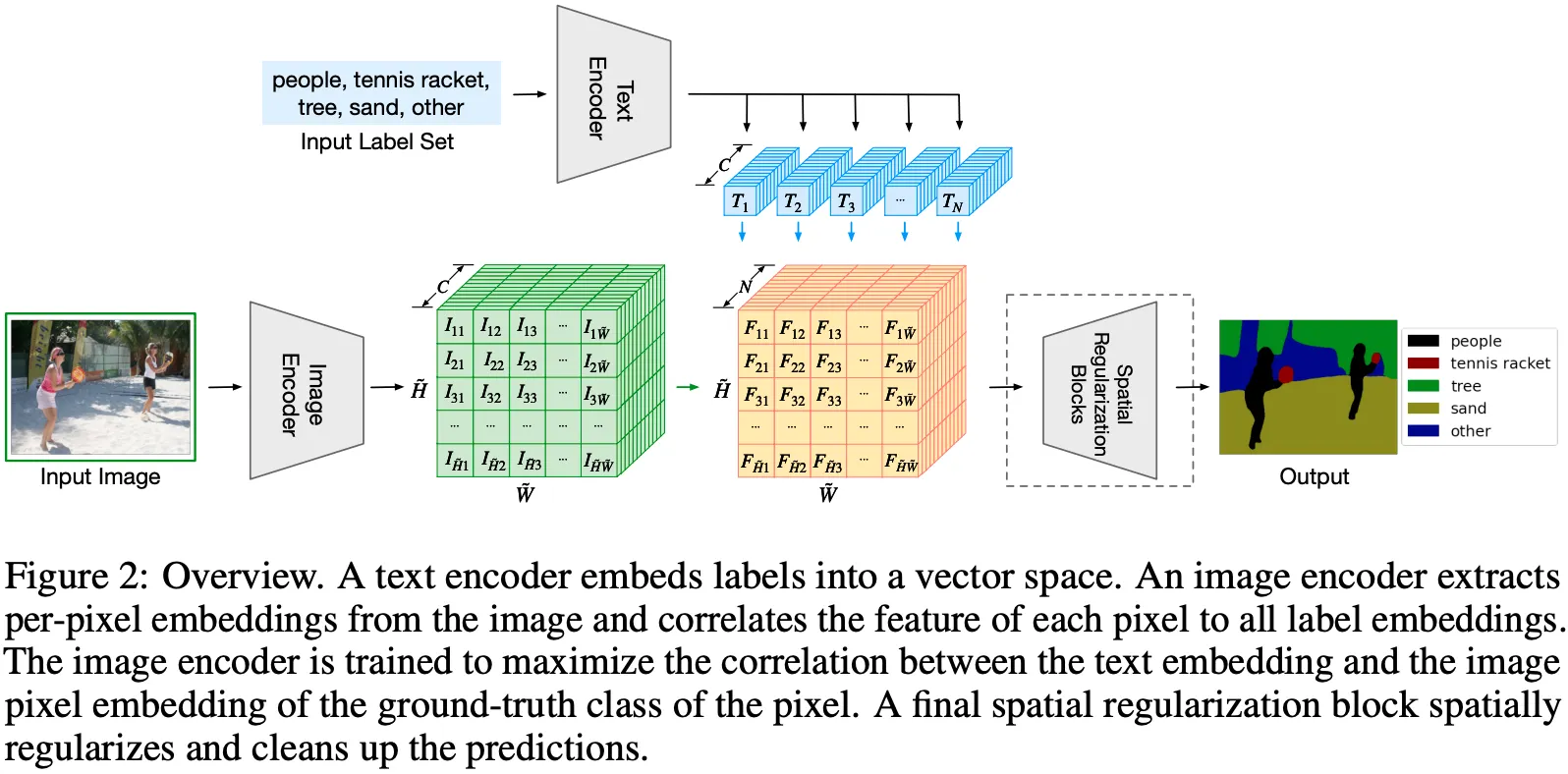
제안 기법의 핵심 아이디어는 간단 명료하다.
한정된 Label Set (학습 데이터)으로 일단 모델을 학습한 후, Test Time에 처음 마주하는 Label은 Trained LM으로부터 힌트를 얻어 Segmentation을 수행하는 원리이다.
CLIP을 비롯한 V-L 모델들의 핵심 전제와 유사하다고 생각한다.
이러한 의도에 맞게 Text Encoder로는 RoBERTa, ELECTRA 등이 아닌 V-L Transformer, CLIP의 Text Encoder를 활용하고,
Image Encoder로는 동일 저자의 Dense Prediction Transformers (DPT) 구조를 활용한다. (Backbone은 ResNet or ViT 사용)
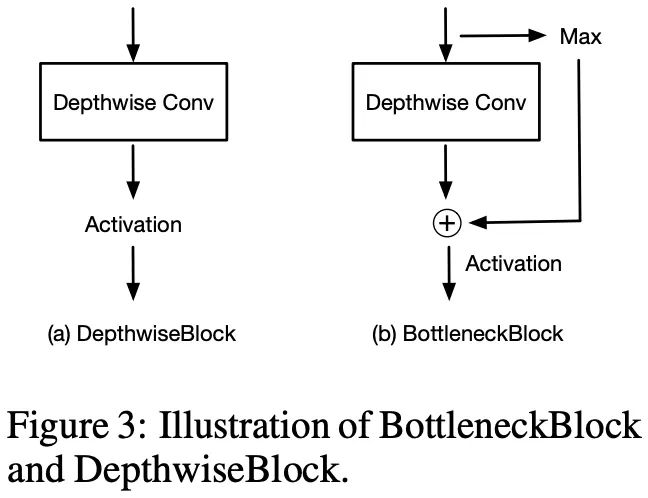
메모리 이슈로, Image Encoder 이전 Downsampling을 수행하는데, 이를 복원하기 위해 Spatial Regularization Block+Bilinear Interpolation을 활용한다고 한다. (이 부분은 잘 모르겠음.. )
)Spatial Regularization Block은 위의 그림과 같고, Zero-Shot의 특성상 Label Set이 유동적이기 때문에 이들 간의 독립성 보장을 위해 Depthwise Convolution을 사용한 것으로 이해하였다.
학습 시, Text Encoder는 Freeze한 채 Image Encoder만 Update하며, Batch 단위가 아닌 Dataset의 전체 Label Set을 단일 이미지의 Contrastive Learning에 사용한다.
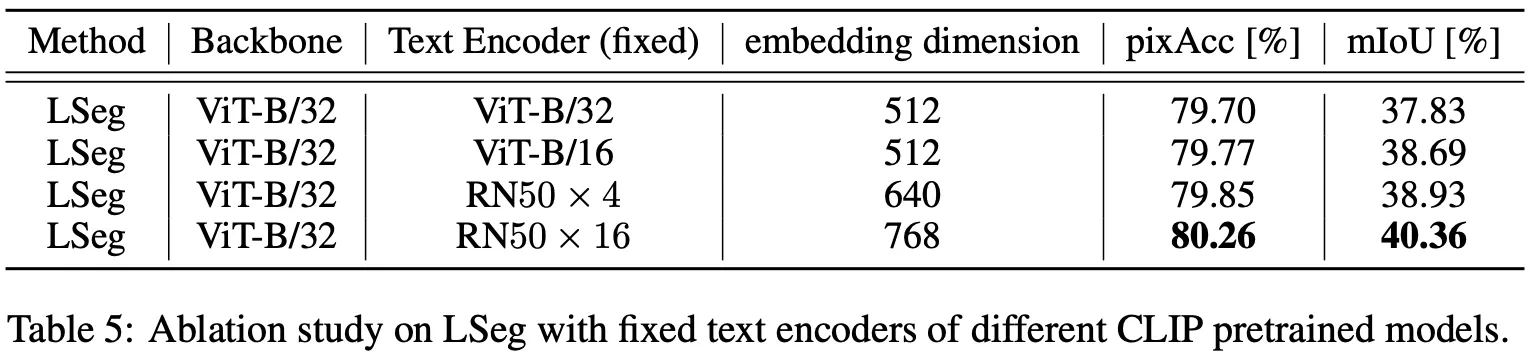
실험 결과는 해당 분야와 Task를 본인이 잘 모르기 때문에 생략한다..
역시나 좋은 성능! (Zero-Shot이지만 다른 1-Shot 기법들에 준하는 성능)
아쉬운 점은 Text Encoder의 Ablation Study에서 순수 LM을 사용해보는 것은 어땠을까 하는 점..!
본 논문에서는 CLIP의 Text Encoder 종류만 교체하였으며, 이 와중에도 Larger 모델이 더 좋은 성능을 보인다!