
Gradient Descent Optimization 기법들에 관해 복습 & 공부한 내용 정리.
스스로의 이해를 위한 글로, 일부 내용 부정확할 수 있음! 자료 정리 위주.
스스로의 이해를 위한 글로, 일부 내용 부정확할 수 있음! 자료 정리 위주.위 자료들을 감사하게도 한국어로 설명해주신 다음의 블로그 포스팅들도 참고하였음
Gradient Descent
•
Objective Function에 대한 모델의 Parameter 별 편미분 값을 활용하여, 각 Parameter 값을 최적화하는 DL의 대표적인 Optimization Algorithm
•
해당 알고리즘의 Key Challenge 중 하나는 Non-Convex한 Loss Function에서 Local Minima를 어떻게 벗어날 것인가이며 (Local Minima가 아닌 Saddle Point를 핵심 문제로 지적하는 논문이 있음),
•
모델의 모든 Parameter에 동일한 Learning Rate가 적용되는 것을 어떻게 풀어나갈 것인가 역시 중요한 Key Challenge임
Solutions
•
Momentum
•
Adaptive
•
Adam
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
•
일반적으로 좋은 성능의 Adam Optimizer는 Parameter 별로 2개의 값(Past Gradients for Momentum & Past Squared Gradients for Per-Coordinate Gradient Scaling)을 추가 저장하기 때문에 모델 크기의 3배에 해당하는 메모리를 사용함
•
(아래부터는 본인이 이해한 내용)
•
Adafactor의 경우, 메모리 사용량을 완화하기 위해 Low-Rank Approximation을 적용함
◦
일반적으로, SVD를 수행한 후에 Top-k개의 Singular Value에 상응하는 벡터들만을 남기는 방식 사용 (PCA와 비슷)
•
Adafactor는 Past Squared Gradients를 Rank-1 Matrix로 취급하는데, Rank-1 Matrix는 2개의 Column Vector의 외적으로 표현할 수 있음 (Definition)
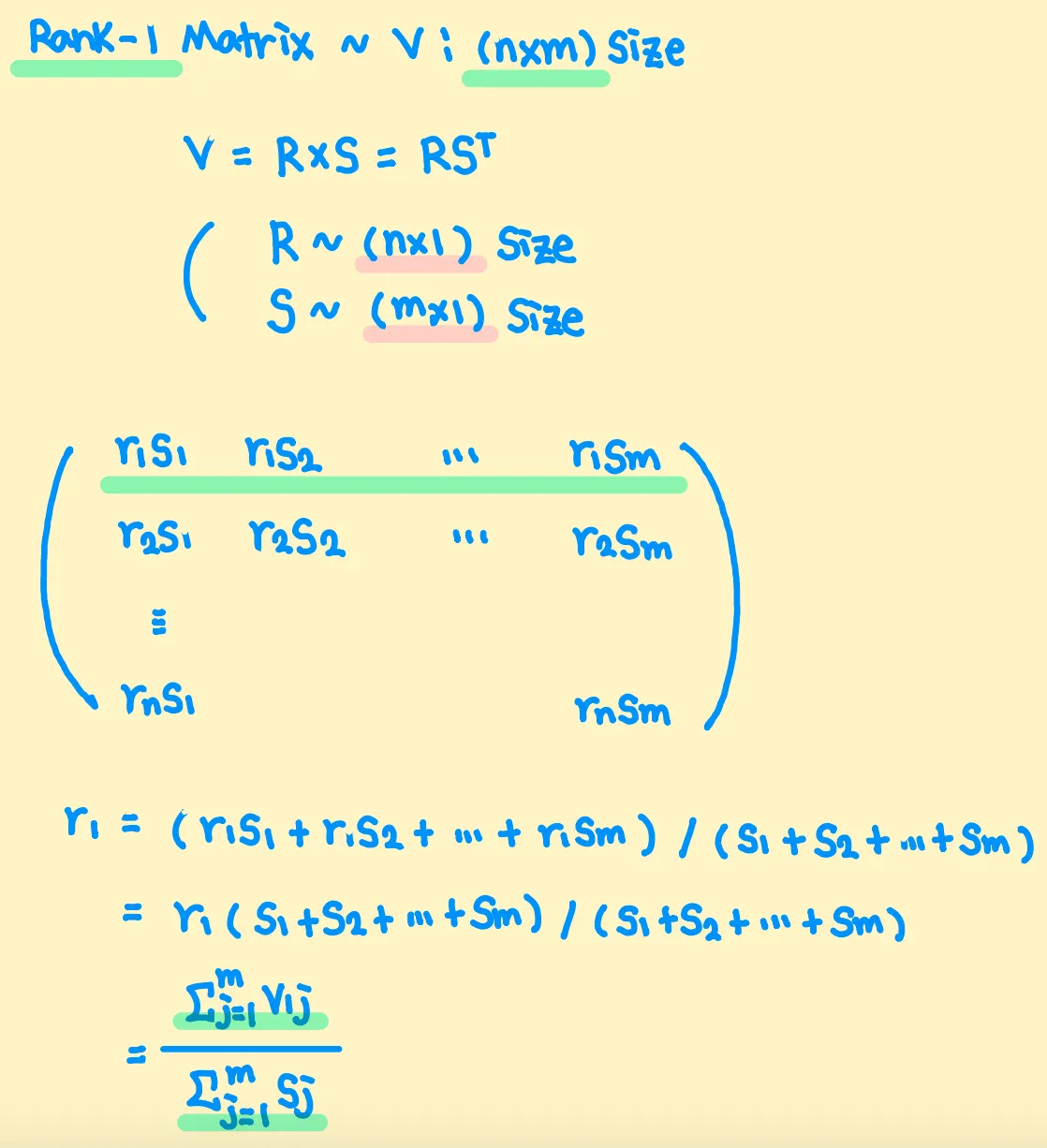
•
위와 같은 성질을 활용하여, Past Squared Gradients 전체를 저장하는 것이 아닌, 각 행/열 값들의 합만을 저장하는 방식을 사용함
•
추가적으로, Momentum을 사용하지 않는다고 하는데.. 읽지는 않았음