
OpenAI의 GPT-4 Technical Report 앞부분을 읽고 정리한 내용!
이전 GPT 시리즈와는 달리 모델의 구조, 크기, 학습 방법 및 데이터 등이 공개되어 있지 않음..
OpenAI의 상업적 행보가 본격적으로 시작된 것은 아닌지.. 덕분에 궁금했던 Input Image 처리 방법을 추측할 수밖에 없었음..
GPT-4

•
OpenAI GPT 4번째 시리즈
•
ChatGPT에 비해 느리지만 더욱 정교한 텍스트 생성.. 무엇보다 Image를 Input으로 받을 수 있는 Multi-Modal 모델 → Image를 생성(출력)할 수는 없음
•
ChatGPT와 마찬가지로 Next Token Prediction 방식으로 Pre-Training + RLHF을 활용한 Post-Training 수행
•
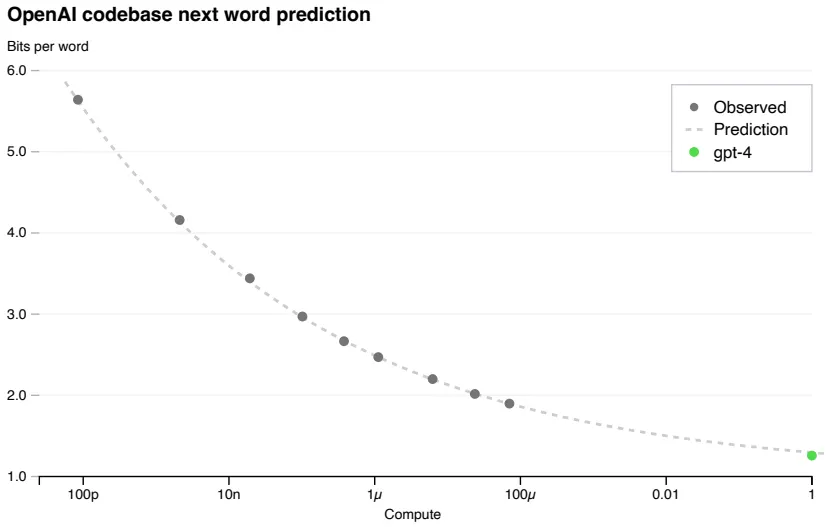
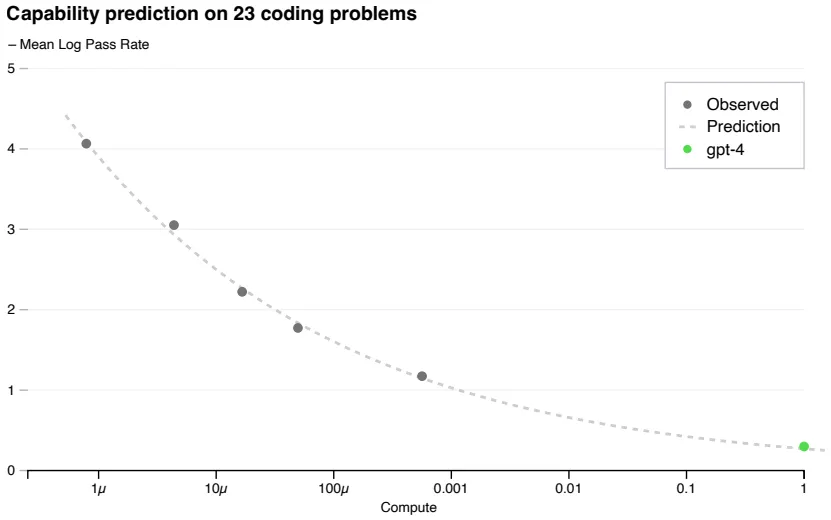
Technical Report에서 가장 처음 강조하는 부분은 GPT-4의 학습이 예상 가능(Predictable)하다는 점
•
구체적으로, 최종 GPT-4보다 짧게 학습된 (적은 연산량의, 최대 1/10,000) 모델들로부터 최종 모델의 Loss (위 그림), Capability (아래 그림)를 유추할 수 있다는 의미
•
Large LMs은 학습 비용이 매우 크기 때문에 예측 가능한 Scaling이 중요!
•
과거 OpenAI의 LM Scaling 연구와 맥이 맞닿아 있음
•
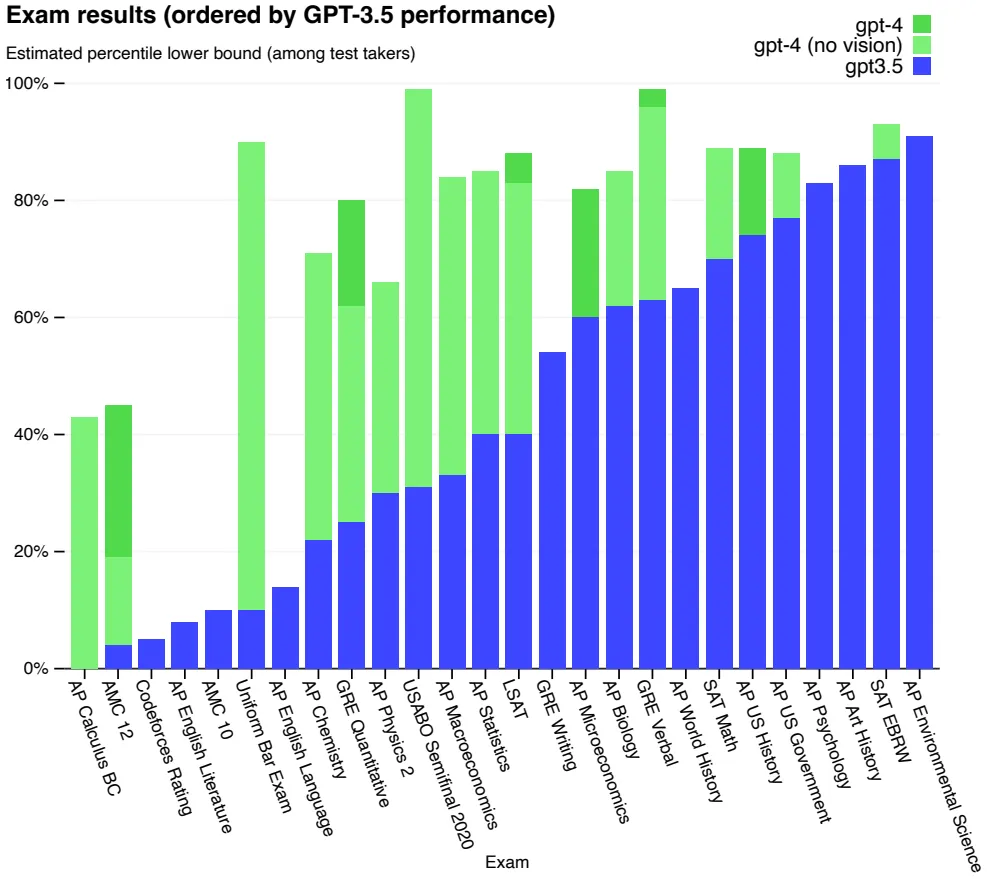
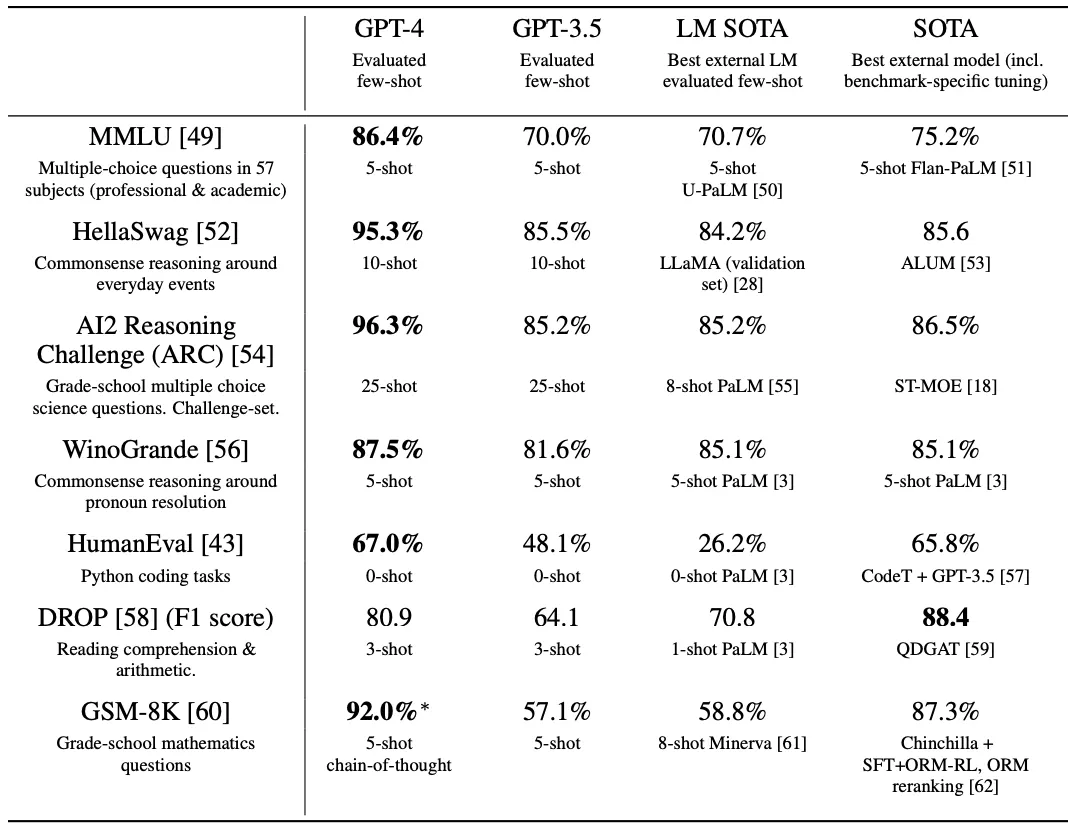
모델의 성능은 역시나 SOTA 수준!
•
성능 측정은 크게 다음과 같은 2개 영역에서 수행됨
◦
Academic/Professional Exams (위 그림): Real-World Applications 느낌
◦
Academic Benchmarks (아래 그림): 전통적인 ML Benchmarks 느낌
•
또한, MMLU Benchmark에서 Low-Resource 언어들의 성능이 이전 영어 SOTA를 능가하는 좋은 Multi-Lingual Capability를 선보임
•
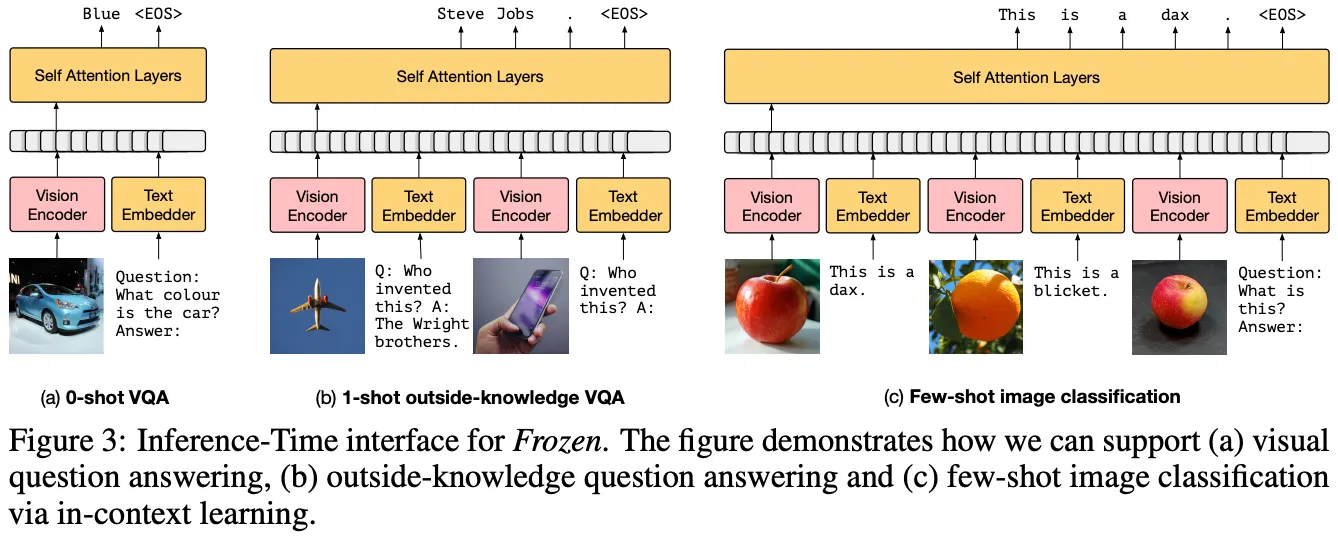
Image를 텍스트와 함께 입력받아 처리할 수 있음
•
유머 설명, 복잡한 표나 그림 해석 등 좋은 VQA 성능을 보임
•
◦
Image를 텍스트 임베딩 공간으로 매핑하는 별도의 Encoder 학습 → LM은 Freeze
•
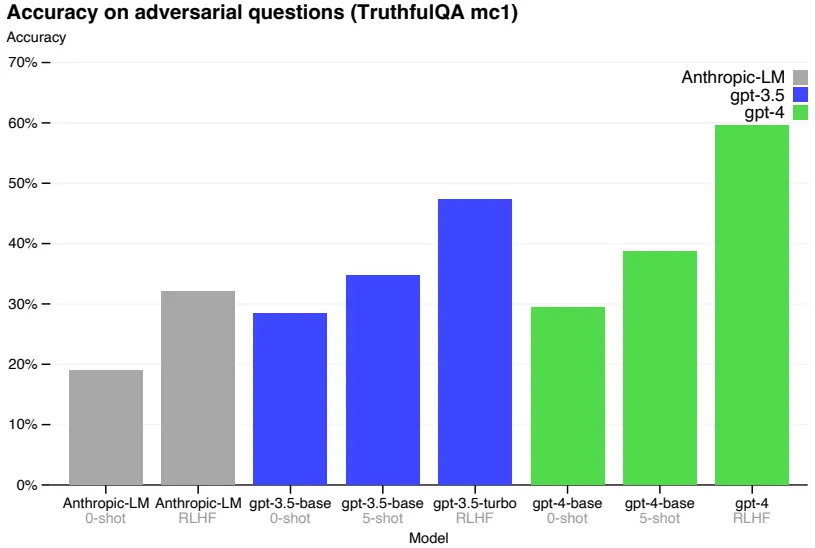
논문에서는 RLHF Post-Training이 GPT 모델의 고질적인 문제, Hallucination을 완화시킨다고 주장 (TruthfulQA, 위 그림)
◦
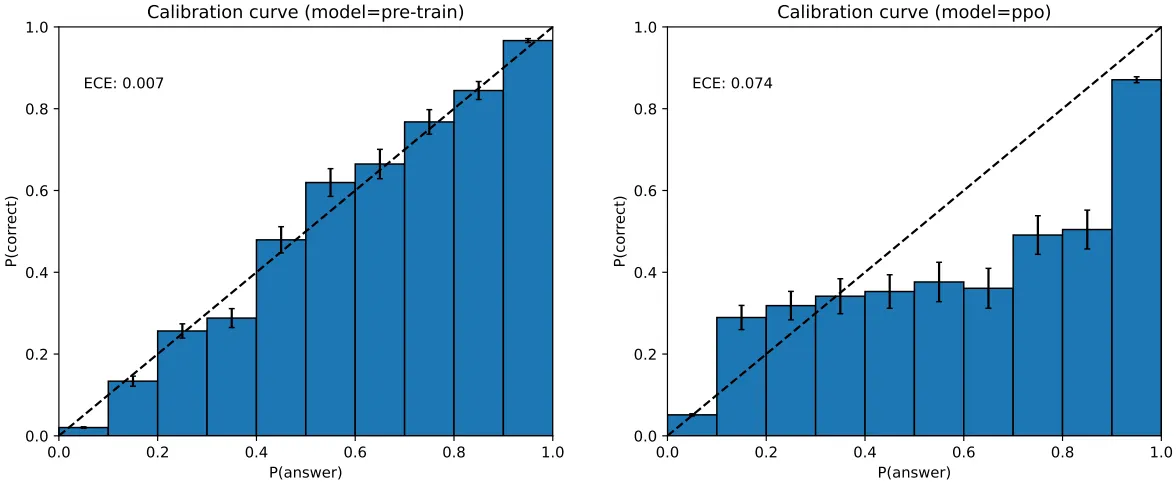
흥미롭게도 Post-Training 시에 모델의 Calibration 성능은 감소한다고 함 (MMLU, 아래 그림)
•
Post-Training에서 GPT-4 Zero-Shot Classifier 활용 → 모델이 Toxic Prompts에 답변을 거부하도록 학습 수행
◦
모델이 Toxic Prompt에 답변을 거부하면 보상을 주고,
◦
반대로 Safe Prompt에는 답변을 거부하지 않을 때 보상을 줌