
지난 달에 리뷰한 V-L Models (UNITER, VILLA, Frozen)와는 달리 Image, Text의 Dual-Encoder 구조+Contrastive Learning을 활용한 Google Research.
Noisy, BUT Large-Scale Conceptual Captions-Like Dataset을 구축하여 Pre-Training을 수행하는 것이 핵심 Idea.
CLIP과 유사한 느낌이기도 하고.. 많이 흥미로운 내용은 아니지만, 좋은 References가 많아 기록해 둠!
Problems
•
NLP에서 Unlabeled Corpus로부터 Text Representations를 얻는 것과 달리 Vision 혹은 V-L Representations는 Curated & Expensive한 Dataset (ImageNet, Conceptual Captions..)이 필요함
•
그렇기에 Vision & V-L Dataset의 Scale을 키우는 것은 제한적임
•
본 연구는 Dataset 구축 시에 Data Filtering 기준을 완화시켜, Noisy하지만 Large-Scale (1.8B Pairs)의 Conceptual Captions-Like (Vision & V-L) Dataset을 얻음
•
해당 Dataset으로 Pre-Trained된 모델은 UNITER, VILLA와 같은 Cross-Modal Attention 모델들을 능가하는 성능을 보임
Proposed Model: ALIGN
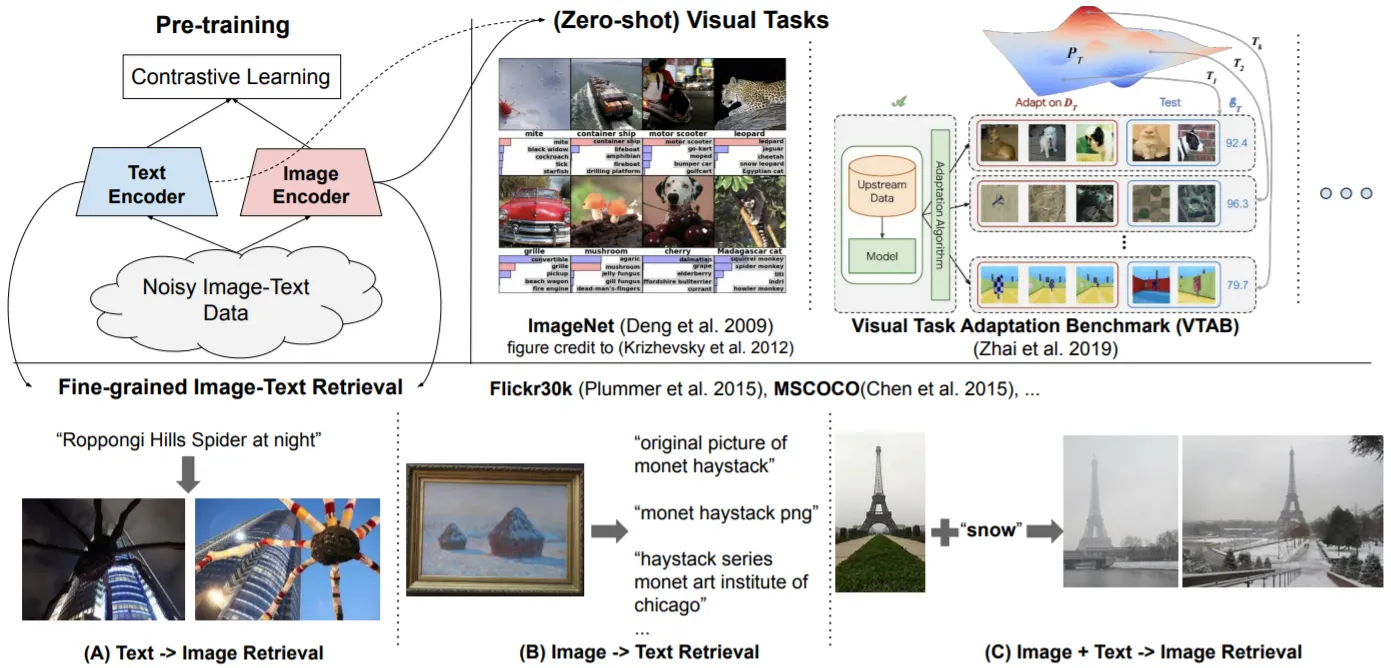
•
Image (EfficientNet), Text (BERT)의 Dual-Encoder 구조
•
Contrastive Learning: Normalized Softmax Loss 사용. Temperature 변수가 중요하여 Learnable Param으로 설정
•
(Zero-Shot & Fine-Tuned) Image-Text Matching & Retrieval Tasks에서 좋은 성능을 보이며, CLIP 이상의 Visual Classification 결과를 보임
•
가장 흥미로웠던 결과는 Word2Vec과 유사하게 Image, Text Representations를 가감하여 원하는 특성의 Image를 Retrieval할 수 있다는 점이다!
미래에 공부할 것들..!Contrastive Learning, Vision Transformer..